Main Reference
- [@santamariaEntropyMutual2015]
- [@baoMEMCNetMotionEstimation2019]
- [@parkBMBCBilateral2020]
FRC - Frame Rate Conversion
FRC 顧名思義就是做幀率轉換,一般是從低幀率轉換成高幀率。爲什麽需要做 FRC? 有兩個原因:(1) bridge video/game content frame rate and device refresh rate; (2) 高幀率 (HFR - High Frame Rate) 提高 video or game 的流暢性 (smoothness),這是目前主流或是高階電視和手機的賣點。
Video Content Frame Rate
大多電影拍攝還是 native 24 FPS (李安的 Billy Lynn’s Long Halftime Walk 是史上最高電影使用 native 120 FPS). TV 和 Game 大多是 native 30, 60 (少數 120 FPS). Video call 例如 WeChat, Line, Zoom 可能用不到 10 FPS 的 video stream 節省頻寬和遲延 (latency).
Device Refresh Rate
主流電視 (2021) 的 refresh rate 是 60Hz; 高階電視可以到 120Hz, 甚至 240Hz (大多是插黑幀)。主流旗艦手機 (2021) 的 refresh rate 是 120Hz.
下表 summarize video content 和 device refresh rate 的 gap, 需要 FRC to bridge the gap.
| Video Cotent Frame Rate | Device Refresh Rate |
|---|---|
| Movie: 24 FPS | TV device: 60/120/240Hz |
| TV video: 30, 60 FPS | Smart phone device: 60/90/120Hz |
| Game: 30, 60, 90 FPS | |
| Video call: 15/10 FPS |
Smoothness
以上是單從 bridge video/game content and device refresh rate 出發。如果只是這個目的,最簡單的方法就是插重複幀,或者插黑幀。
我們舉一個實際的例子,例如 movie content 是 24 FPS, 但要在 60 Hz TV 顯示。 最簡單的方法就是如下的插幀。
不單是插重複幀,而且還不是均匀插幀。而是 2-3-2-3 插幀。兩個問題 (1) 不均匀插幀會造成視覺上有顫抖 (judder) 現象,Youtube 有一些影片可以參考;(2) 低 frame rate (e.g. 24 FPS) 雖然有所謂的 “電影感”, 但在内容有高速運動的畫面 (e.g. 球賽或是打鬥) 就會顯得模糊1。
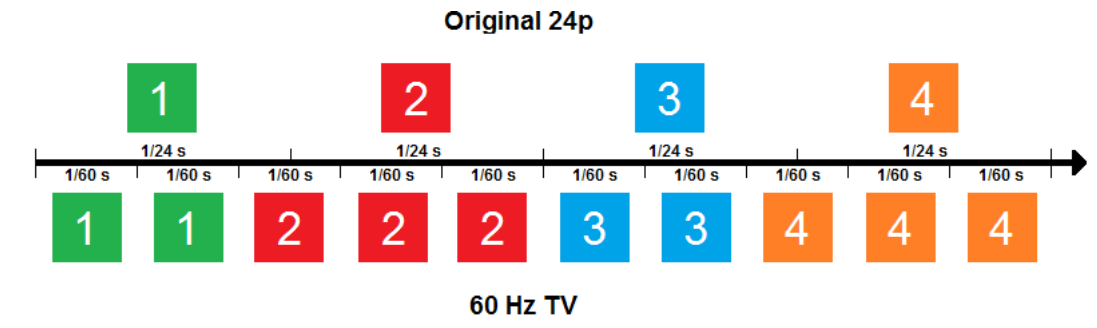
實務上沒有任何電視會用這種方法做 24 to 60 FPS 的 FRC. 這就會帶到下一個題目, MEMC.
MEMC - Motion Estimation Motion Compensation
FRC 是一個規格需求,從 A FPS 轉到 B FPS, 一般 B > A. 最簡單的做法是(不均匀)重複插幀或是插黒幀。不過沒有電視這樣做,因爲視覺感受 (visual perception) 不好。
目前主流的方法就是對 native frames, e.g. N and N+1 at 24 FPS, 做 motion estimatin (ME), 再根據要插出的幀的時間做 motion compensation (MC), e.g. M, M+1, …, M+5 at 60 FPS, 也就是 2 個 input frames 產生 5 個 output frames (24FPS to 60FPS). ME 加 MC 合稱爲 MEMC.
Forward and Backward Motion Map
我們用一個最簡單也是目前最常用的 MEMC 爲例,如下圖: input frame rate N at 30FPS, output frame rate M at 60 FPS, conversion rate 為 2. 兩張 input frames, 叫做 $I_0$ and $I_1$, 可以計算或搜尋出 forward motion (vector) map, 就是 image 的每一個 pixel 都有對應的 motion vector, 稱爲 $F_{0\to1}$. 這個過程就是 ME (motion estimation). 再來藉助 $I_0$ 和 $F_{0\to 1}$,就可以 forward warp 出 $I_{0.5}$ output frame. 這個過程就是 MC (motion compensation).
In summary: ME 就是產生 motion map; MC 就是用原來的 image 加上 motion map, warp 出 output image.
上述 forward warp 並不是唯一的 ME-MC。我們也可以計算 backward motion (vector) map, 稱爲 $F_{1\to 0}$, 藉助 $I_1$ 和 $F_{1\to 0}$, 同樣可以 backward warp 出 $I_{0.5}$ output frame.
乍看之下,好像 forward motion map $F_{0\to 1}$ 和 backward motion map $F_{1\to 0}$ 是 reverse 的關係。其實不然。
以下圖 original image 爲例,$F_{0\to 1}$ 在 $I_0$ 小車的位置的 motion vector 是前進,其他位置為 0. 但 $F_{1\to 0}$ 雖然 motion vector 是後退,和 $F_{0\to 1}$ 剛好是 reverse,但卻是在 $I_1$ 的小車位置,而不是在 $I_0$ 小車的位置,一般我們稱爲不同的 anchor point (錨定點)。所以 forward motion map $F_{1\to 0}$ 不是 backward motion map $F_{0\to 1}$ 的 reverse map,因爲 moving object 在不同 frame 的 anchor point 不同!
More problem when occulusion occurs
The motion map is NOT 1-to-1, but many-to-1!!
Back to Physics (Laplace Monster!)
current object position and velocity, we can predict everything
Problem, we don’t have velocity => easy, we use t_0 and t_1 for the velocity
Problem, 2D and 3D
Problem, new information, for example, a monkey jumping from the stone at t1 (I don’t know where it is in t_0.5)! or move to a new scene! => inpainting, best guess
Video use both forward and backward and blending for more information!
爲了讓 picture quality 更好,一般我們也會估算 backward motion vector, 稱爲 $F_{1\to 0}$
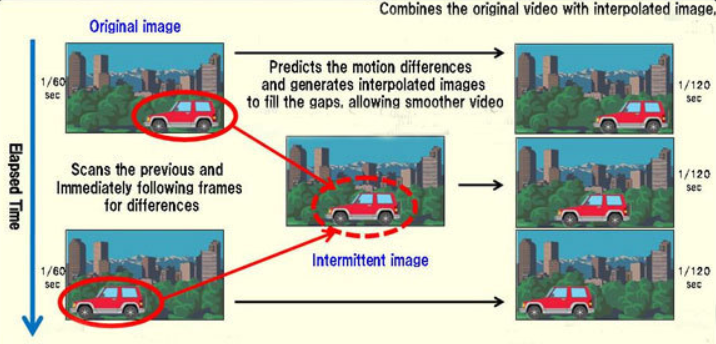
MEMC 的技術基本分爲 (1) 傳統的方法和 (2) 深度學習的方法 [wikiVideoSuperresolution2021].
此處略過 (1),主要介紹 (2) 深度學習的 MEMC.
Challenge
- 3D to 2D so information is not complete, occusion problem without depth map!! (ill-condition)
- 2D video Interpolation will suffer from the occusion problem
- 3D graphics (with depth map) interpolation does not have this problem, but graphic will not use this because of latency
- Extrapolation has additional problem of information deficiency (ill-condition)
- 2D Video will not use it because it’s quality loss, and it can tolerate latency
- 3D Graphic suffer from this problem
MEMC Basic And Challenges
顧名思義,MEMC 分爲兩個部分: ME (Motion Estimation) and MC (Motion Compensation).
Deep Learning Based MEMC
Deep Learning Based 可以分爲兩類:(A) ME and MC; (B) Deformable convolution.
ME-MC
Motion Estimation: provide information about the motion of pixels between frames.
Motion Compensation: a warping operation, which aligns one frame to another based on motion information.
| ME / MC | Two frames Interpolation | One Frame Extrapolation |
|---|---|---|
| one motion | ||
| Game, Motion/depth map from ground truth | forward warping | |
| XR, Motion/depth map from IMU sensor | forward warping | |
| Video, Motion/visual maps from consecutive frames | Prefer backward warping for better quality: ideal two images blending, no inpainting; but has image halo issueto solve motion map halo (use motion map inpainting) | Forward warping problem: 1. predicted motion map error cause overshoot; 2. object occulusion w/o depth map; 3 Image inpainting |
對於 video 而言,ME 主要由連續 frames 產生,例如 optical flow. 基於 optical flow 的 深度學習有 FlowNet, RAFT, etc. 可以參考上文。
對於 game 而言,ME 有機會事先得知 (object motion based on physics), 不一定要用最後的 image frames 產生。
Aligned by deformable convolution
一般 image 的 convolution 都是 fixed kernel (e.g. CNN). Deformable convolution 則是先 estimate shifts for kernel and do convolution.
3D Convolution
motion estimation: optical flow
AI-MEMC
AI motion estimation
FlowNet
RAFT
Kernel method
AI motion compensta
MEMC
- CV
- AI optical flow - pixel level
- Kernel - patch level
Motion Estimation Motion Compensation (MEMC)
Optical flow 的一個主要應用是 MEMC,就是所謂插幀。基本所有的電視都有這個功能。就是從 $I_{t-1}$ 和 $I_{t+1}$ 内插出 $I_t$. 這個插幀可以在正中間,例如 30 FPS to 60 FPS; 或是 60 FPS to 120 FPS. 也可以不在正中間,例如 24 FPS to 60 FPS.
MEMC 顧名思義包含 ME (Motion Estimation) 和 MC (Motion Compensation).
ME 基本有三類: (i) conventional ME (此處不論); (ii) optical flow motion estimation (pixl level); (iii) kernel (patch level) (也不論)。
MC 包含: image warping,image inpainting.
因爲深度學習的 optical flow motion estimation 已經包含 image/feature warping, 因此 ME 和 MC 可以合在同一個網路。就是把原來 optical flow network for motion estimation 擴大 to cover 完整的 MEMC network。
基本可以把 MEMC 分爲三個 steps,如下圖: [@baoMEMCNetMotionEstimation2019]
Step 1: 我們可以從 $I_{t-1}$ 和 $I_{t+1}$ 得到 forward optical flow $f_{t-1\to t+1}$, 和 backward optical flow $f_{t+1\to t-1}$.
Step 2: 再來是從 step 1 的 optical flow 内插 $f_{t\to t-1}$ 和 $f_{t\to t+1}$
Step 3: 接下來觀念上可以用 $I_{t-1} + f_{t\to t-1}$ backward warping 得到 $I_t$. 同樣用 $I_{t+1} + f_{t\to t+1}$ backward warping 得到 $I_t$. 當然這兩個結果還是會有差異。因此觀念上可以做 bilaterial warping 得到更好的結果。

接下來會看一些例子。
Ex1: MEMC-Net (2019),ME is based on FlowNetS
[@baoMEMCNetMotionEstimation2019] 下圖是 MEMC-Net architecture. 最上面的分支就是 Motion Estimation.
ME part
Step 1: Motion estimation 直接用 FlowNetS in Fig. 3. Input: $I_{t-1}, I_{t+1}$, output: $f_{t-1\to t+1}, f_{t+1\to t-1}$.
Step 2: 用 flow projection layer, input: $f_{t-1\to t+1}, f_{t+1\to t-1}$, output $f_{t\to t+1}, f_{t\to t-1}$. 基本假設 linear motion projection.

MC part
Warping : motion warping + kernel warping
Inpainting: 因爲有兩張 frames, 一般會有 1 frame occlusion 可以被另一 frame cover. 所以只要標出 Occulusion mask 配合 warping 即可。最後如 PWCnet 再加上 context network for post processing.
再看一個例子,BMBC:
Ex2: BMBC (Bilateral Motion Estimation with Bilateral Cost Volume, 2020), based on PWCNet
[@parkBMBCBilateral2020] 下圖是 BMBC archtecture. 上三路的 (shared) bilateral motion network 是最重要的 building block to perform Motion Estimation (ME)。之後的 warping layer 和第四路的 context extractor 則是 perform Motion Compensation (MC)。
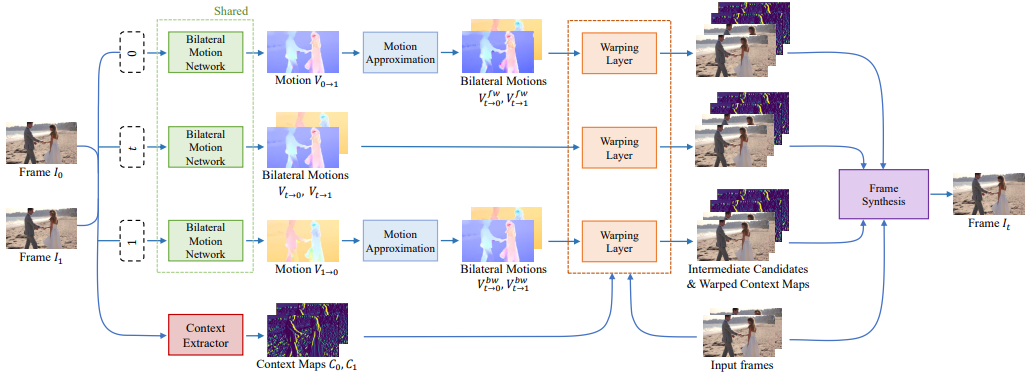
ME part
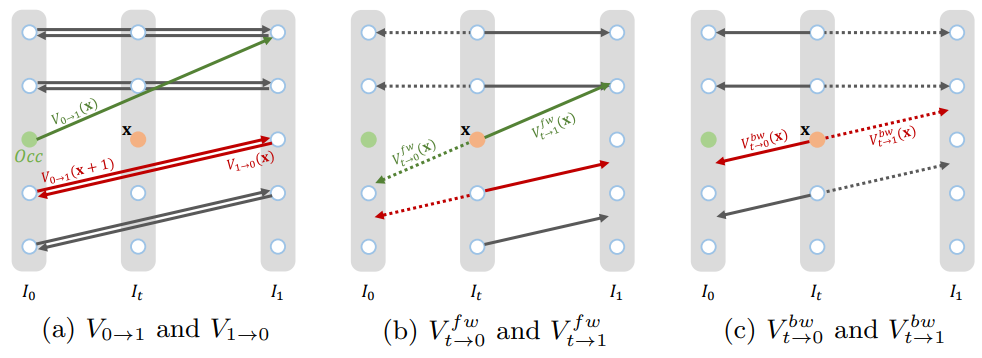
Combine Step 1 and 2: Bilateral Motion Estimation,如下圖。這裏把 step 1 和 2 結合一起,直接得到 $V_{t\to 0}$ 和 $V_{t\to 1}$,如下圖。
其實是把 PWCnet 加上改良,把原來 Pyramid1 warp to Pyramid0 部分,再加上 Pyramid0 warp to Pyramid1 (改良 bilateral 部分)。比較巧妙的部分是直接把兩個改成 Pyramid1/2 warp to Pyramid t. 並且得到 $V^l_{t\to 0}$ and $V^l_{t\to 1}$。 注意這裏都是用 backward warping!
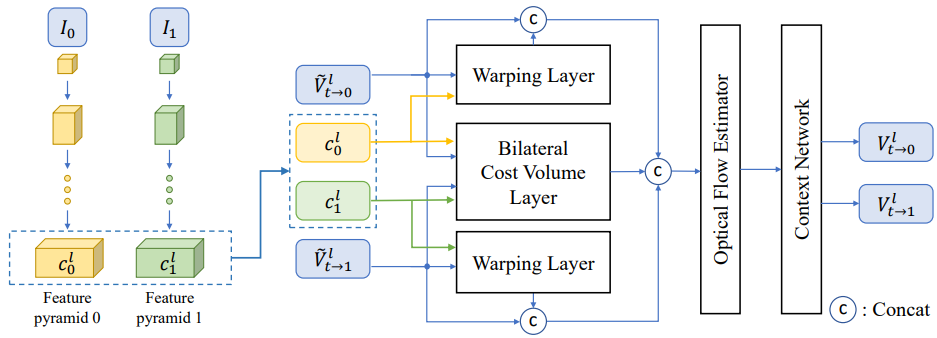
Cost Volume 的做法也是變成雙向。$d$ 是 search window size $D = [-d, d] \times [-d, d]$ 爲了減小 computation complexity.
\(B C_{t}^{l}(\mathbf{x}, \mathbf{d})=c_{0}^{l}\left(\mathbf{x}+\widetilde{V}_{\mathrm{t} \rightarrow 0}^{l}(\mathbf{x})-2 t \times \mathbf{d}\right)^{T} c_{1}^{l}\left(\mathbf{x}+\widetilde{V}_{\mathrm{t} \rightarrow 1}^{l}(\mathbf{x})+2(1-t) \times \mathbf{d}\right)\)
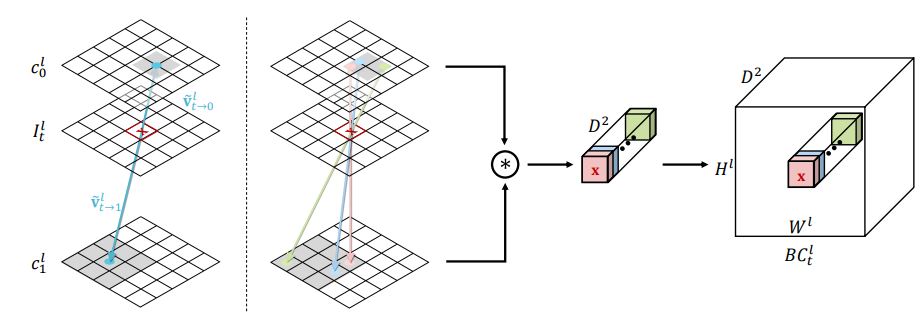
注意 $V_{0\to 1}$ 或是 $V_{1\to 0}$ 只是 $t=0$ 或是 $t=1$ 的特例。就回到 PWC-Net.
那麽上上圖的 branch 1 and 3 的 Motion Approximation 是要做什麽? 主要是針對 occlusion 再產生更多的 $V_{t\to 0}$ 和 $V_{t\to 1}$,如下圖。細節請直接參考 paper.
再來非常複雜的把三路中每一路的 4 張 estimated Image t, 連同 2 張 input image, 一共 4x3+2 = 14 張合成 $I_t$. 應該是不計計算成本。
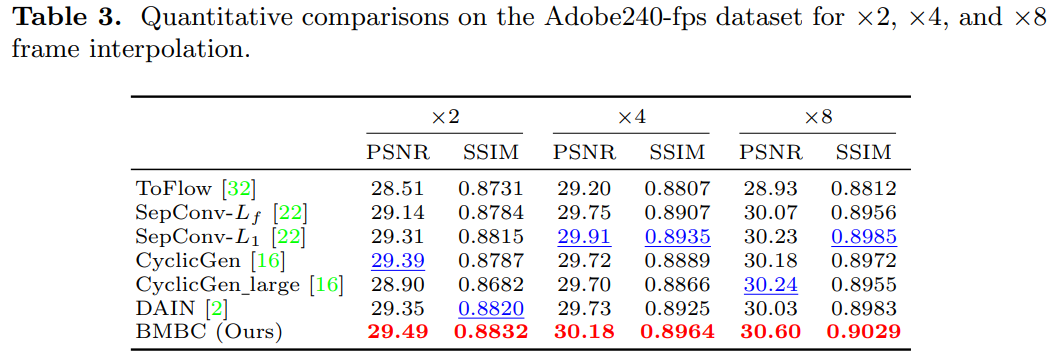
實驗結果
用了 4 組 datasets, Middlebury, Vimeo90K, UCF101, Adobe240-fps. 並且比較 SOTA 結果。
- Adaptive convolution: SepConv, ToFlow, CtxSyn
- Optical Flow NN: ToFlow, SPyNet, MEMC-Net (Bao), DAIN (depth aware, Bao), BMBC
Middlebury
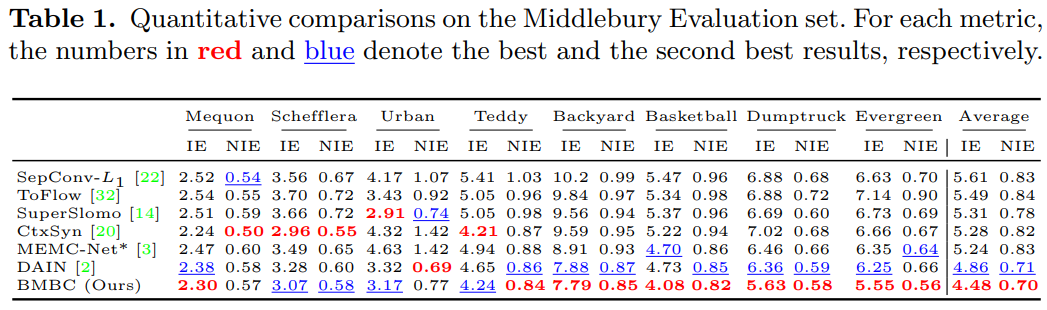
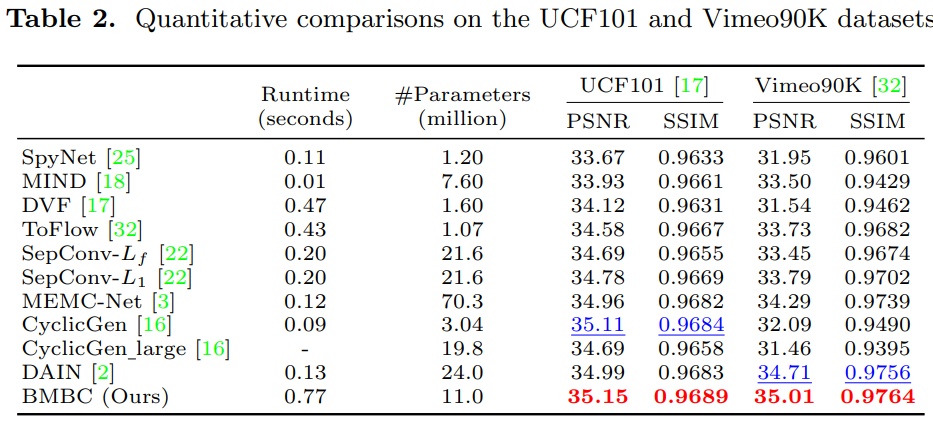
-
電影一般用特效 (e.g. slow motion) 處理。 ↩