Reference
[@chatzisComprehensiveStudy2020]
[@chenAwesomeHand2022]
手是我們的主要操作工具,它們在空間中的位置、方向和關節對於許多人機界面至關重要。 Hand pose estimation 對於 VR/XR、手語識別、手勢識別和機器人人機界面等各種應用非常有用。
Pose estimation 包含 hand pose 和 body pose estimation 目的在精確測量人體運動,有機會成爲新一代的自動化工具。雖然 hand pose estimation 和 body pose estimation 這兩個領域在目標和難度上有很多相似之處,但 hand pose estimation 有特別的問題需要解決,例如缺乏 characteristic local features, pose ambiguity, and self-occlusion.
Hand Pose Estimation
Hand pose estimation 算法和其他的 computer vision 算法有一個基本的不同,就是 hand pose estimation 是 output 3D joint points. 2D hand pose output 基本沒有太大的用途 for hand sign, or user interface。一般的 object or people detection,image segmentation,以及類似的 face 算法像美顔、表情、識別,一般只要 output 2D bounding box, 2D contour, or 2D feature points.
即使和 hand pose estimation 非常相似的 body pose estimation,正面的 body pose (例如 Kinect) 一般也只要 2D 即可。但是行走、或是更複雜的 dancing, 則需要 3D post estimation.
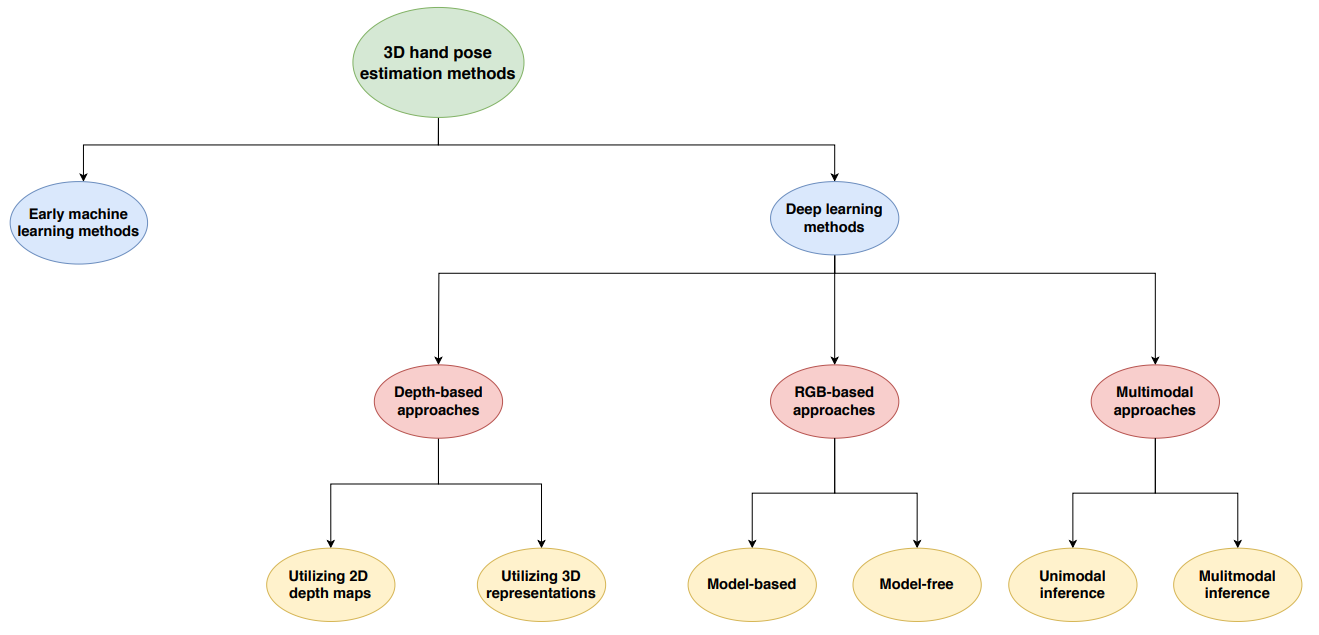
下圖是實現 3D hand post estimation 幾種分類的方法。我們聚焦在深度學習方法。主要差別是 input 的方法:
-
傳統的 vision-based 3D hand pose estimation 主要靠 depth information (3D point cloud, 或是 RGB+D) 判斷,例如 depth camera (e.g. stereoscope, ToF, structure light)。不過這些硬體都有 cost 以及 overhead (e.g. calibration). Depth camera 一般在戶外都有一些限制。
-
另一個方式是使用 monocular RGB camera 估計 hand joint locations for both hands。就是從 2D image output 3D joint points. 這本身是 ill-posed problem. 又可以分成 model-based (with prior information) 或是 model-free method. 一般會用 2D RGB video (motion) sequence 產生比較可靠的 estimation. 我們對此應該不陌生,motion map 和 depth map 算法常常可以是同一類算法,e.g. RAFT for motion map and depth map.
- 2D RGB image to 3D hand pose estimation $\to$ severely ill-posed problem
- 2D RGB video to 3D hand pose motion $\to$ ill-posed problem, but more information to solve
-
第三種是 multimodal approaches。此處不討論。
Hand Pose Estimation Pipeline
在討論 hand pose estimation 算法之前,我們先討論算法的 pipeline. 例如
Face recognition 算法 pipeline 一般是:
- face detection $\to$ scoring $\to$ crop face bounding box and resize $\to$ face recognition
Face beautify 算法 pipeline 一般是:
- face detection $\to$ face landmarks $\to$ face beautify
Hand pose estimation 算法 pipeline 一般是:
- hand detection (and tracking) $\to$ crop hand bounding box and resize $\to$ (1) hand pose estimation (using video sequence) or (2) reconstruct the 3D hand position! (not in this discussion)
Hand Detection or Palm Detection
Use a simple and efficient CNN architecture modified by YOLOv4, simultaneously localize and classifies hand. 這和 surveillance camera 用 YOLOv4 做 people detection 類似。Hand detection 的好處是 bounding box 只 focus on hand, 再來的 image crop and resize 讓計算量比較精簡。
Palm detection 是訓練一個 CNN network 直接 detect palm with a bounding box. 好處是之後的計算量更少。
一般這類應用的 camera 基本都是對著 hand,可以用 frame-by-frame 的 image 做 hand detection, 而不用 tracking algorithm. 但因爲手的確可能會有比較大幅度的橫向或縱向運動,也可以考慮使用 tracking algorithm,就像 surveillance 的 people detection 基本就一定需要 tracking algorithm.
Track and prediction!!
Hand landmark and keypoint (關鍵點) estimation
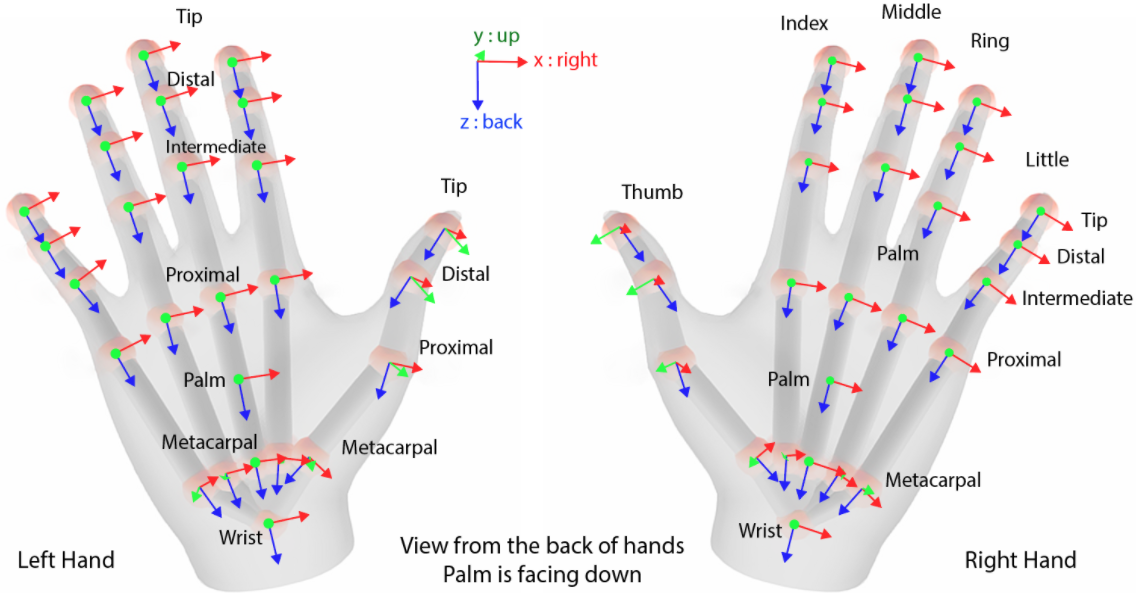
在 hand detection 之後做 crop bounding box. 再來用 cropped image 預測 key-point. 這裏可以用 OpenXR 定義的 26 key-points. OpenXR 規範中定義的 26 個關鍵點 (4 for thumb finger, 5 for the other four fingers, 1 for wrist, 1 for palm),如下圖。
我們的 keypoint estimation network 使用上述 hand detection 步驟中的 crop image 的 predicted bounding box。 這與以前的做法不同,以前的做法關鍵點只基於每個圖像而非 predicted bounding box。 如果手被物體遮擋或在框架中僅部分可見,這是有問題的。 為了克服這個問題,我們的模型考慮了從先前幀中提取的信息。 因此,我們的模型明確地將外差關鍵點作為額外的網絡輸入。
以下是 Unity 的 hand pose estimation, 一共有 26 關鍵點。

以下是 Ultraleap 的 hand pose estimation, 一共有 24 關鍵點 (5x4+4)。

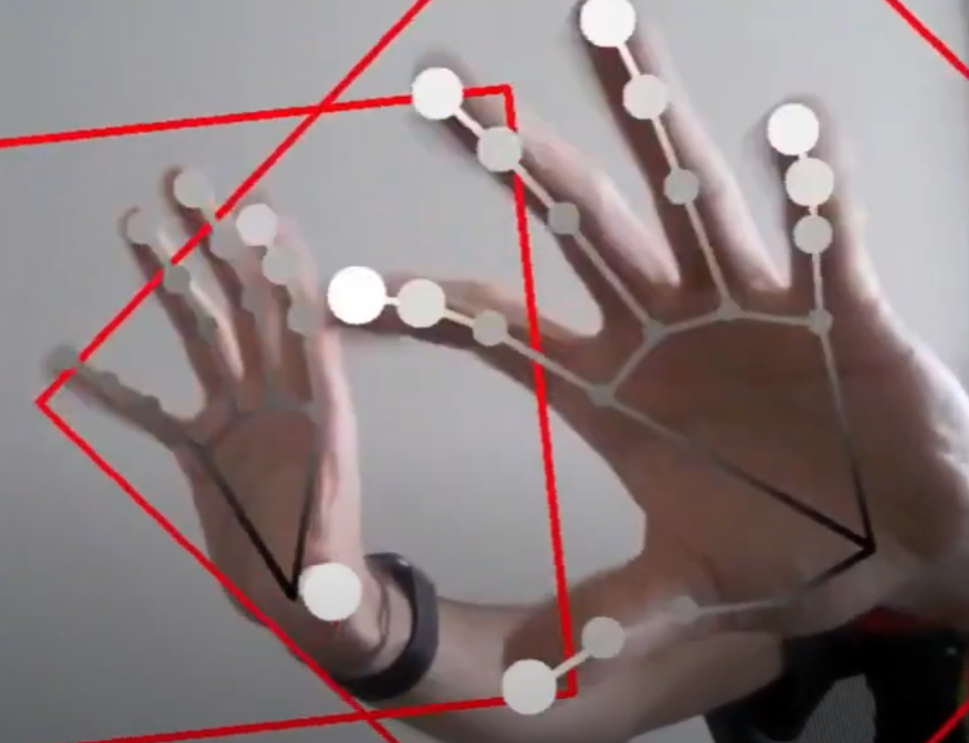
Collabora 是 21 關鍵點 (5x4 + 1) + prediction。網絡產生 2D heatmap for each of the 21 predicted keypoints. 也就是不是 100% 的當幀的結果,而是 predicted 下一幀的機率 (use 2D heatmap)。 Constructed by evaluting a Gaussian following, which is processed by a simple regression model to calculate the final landmarks.
2D Hand Pose and 3D Hand Pose
如果是有 depth 的 image
Collabora 對在 XR 中使用手部姿勢估計特別感興趣,因為該應用程序與我們在 Monado(世界上第一個開源 OpenXR 運行時)上的工作非常吻合。
input 可以是 3D (Depth or RGB+D) 或是 2D (RGB, ill-posed), 但是 output 不論是 keypoints 或是 3D reconstruction 都是 3D output!
或 hand pose reconstruction 都
The difficult problem!
Input: RGB (no D) video
Output: 21/24/26 keypoints sequence in 3D space!
The more difficult problem!
Input: mono video
Output: 21/24/26 keypoints sequence in 3D space!
Technique:
Time sequence –> RNN + CNN?
SSL –> for hand
接下來討論如何進行
- Develop a hand post estimation pipeline: hand detection, hand landmark and prediction (tracking), estimation model.
- Data-augmentation and learning methodology for model training