Reference
[@lecunSelfsupervisedLearning] : excellent introductory article
[@heMaskedAutoencoders2021] : mask autoencoder (MAE)
From Unsupervised Learning to Self-supervised Learning
機器學習 (ML) 的第一課一定會提到三種方式:supervised learning (SL), unsupervised learning (UL), 和 reinforcement learning (RL).
SL 和 RL 的定義和數學框架比較清晰:
- SL 的定義是有 data 和對應的 labels. 數學框架上定義 (continuous and differentiable) loss function 和利用 back propagation 訓練 network to minimize the loss function.
- RL 的定義是有 agent 和 environment 以及 agent 的 (state, action, reward). 數學框架上定義 (non-differentiable in general) reward function 和利用 Markov decision process (MDP) 訓練找到最佳的 state and action sequences.
相對而言,UL 的定義就相對模糊 (data without labels),似乎也沒有一致的數學框架。
- Wiki UL 的定義: UL is a type of algorithm that learns patterns from unlabelled data. 至於要學習什麼 patterns from data?可以是 density, clustering 等簡單性質。或是比較抽象的 minimize energy 等概念。
近年 self-supervised learning (SSL) 橫空出世,光彩已經掩蓋 UL. 有人說 SSL 是 UL 的一支。LeCun 直接用 SSL 取代 “ill-defined” UL 如下 quote. 並試圖給 SSL 一個 unified energy view [@lecunSelfsupervisedLearning]. 本文 follow 這個觀點。
As a result of the supervisory signals that inform self-supervised learning, the term “self-supervised learning” is more accepted than the previously used term “unsupervised learning.” Unsupervised learning is an ill-defined and misleading term that suggests that the learning uses no supervision at all. In fact, self-supervised learning is not unsupervised, as it uses far more feedback signals than standard supervised and reinforcement learning methods do.
Self-Supervised Learning (SSL)
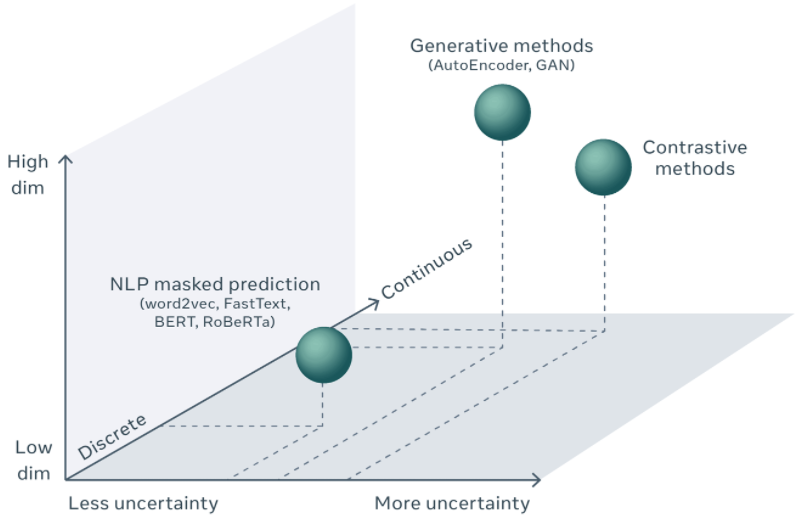
目前廣義的 self-supervised learning method 包含以下幾種:
| Method | Application | Dimension | Algorithm |
|---|---|---|---|
| Generative | Image | High | AutoEncoder, GAN |
| NLP mask prediction | NLP | Low | Word2vec, BERT |
| Contrastive | Image | High | simCLR |
| Image mask prediction (new) | Image | High | MAE |
SSL 有各種不同的方法 for applications of different dimension and uncertainty. 有可能用同一個框架或是觀點整合嗎?
Generative Vs. Contrastive Method
我們先把 SSL 整合成兩大類:Generative and contrastive methods 如下圖。
Predictive method 可以視為是 generative method 的一支。Generative method 的特點就是需要 decoder to generate output, 同時 loss measured in the output space (decoder output).
Contrastive method 則是 discriminative method 的一種。Discriminative method 的特點就是需要 encoder to convert input to feature space (or representation space), 同時 loss measured in the representation space (encoder output).
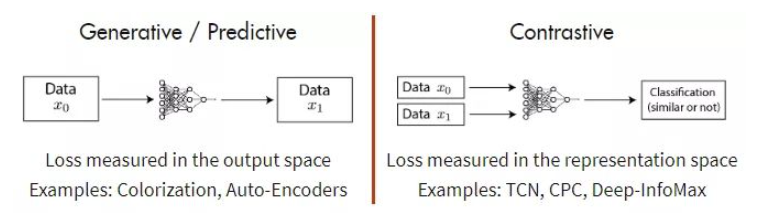
我們已經把幾種 SSL methods 收斂成兩類:generative and contrastive methods. 這是非常廣汎的分類,接下來是如何提出 high level view to unify 這兩類方法。 LeCun 建議用 Energy Based Model.
SSL Unified View - Energy Model
有一個方法提供統一框架是基於能量的模型 (EBM) 思考 SSL。 EBM 是一個 trainable system:給定兩個輸入 x 和 y,告訴我們它們彼此之間的不兼容程度。 例如,x 可以是一個短視頻剪輯,而 y 可以是另一個提議的視頻剪輯。 機器會告訴我們 y 在多大程度上是 x 的良好延續。 為了表明 x 和 y 之間的不相容性,機器會產生一個數字,稱為能量。 如果能量低,則認為 x 和 y 是相容的; 如果它很高,它們被認為是不相容的。
訓練 EBM 包括兩部分:(1) 向其展示 x 和 y 兼容的示例,並對其進行訓練以產生低能量,以及 (2) 找到一種方法來確保對於特定 x,y 值是 與 x 不兼容產生的能量高於與 x 兼容的 y 值。 第一部分很簡單,但第二部分是困難所在。
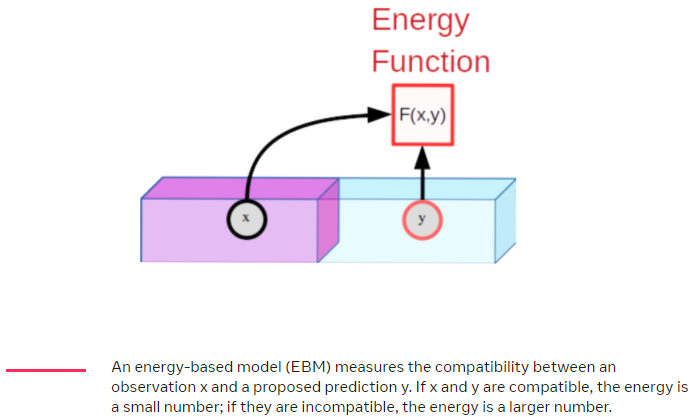
對於圖像識別,我們的模型將兩個圖像 x 和 y 作為輸入。 如果 x 和 y 是同一圖像的輕微失真版本,則模型被訓練以在其輸出上產生低能量。 例如,x 可以是汽車的照片,而 y 可以是同一輛車的照片,該照片是在一天中的不同時間從稍微不同的位置拍攝的,因此 y 中的汽車可以移動、旋轉、變大、變小和 顯示的顏色和陰影與 x 中的汽車略有不同,稱爲 data argument. Training 的方式稱爲 argument invariant.
我們用具體的例子説明。
Joint embedding, Siamese network 孿生網絡
一個特別適合的深度學習架構是所謂的 Siamese networks 或 joint embedding architecture。這個想法可以追溯到 1990 年代初期 Geoff Hinton 的實驗室和 Yann LeCun 的小組的論文。 它在很長一段時間內相對被忽視,但自 2019 年底以來又重新受到重視。A joint embedding architecture 由同一網絡的兩個相同(或幾乎相同)的副本 (i.e. encoder) 組成。 一個網絡輸入 x,另一個輸入 y。 網絡產生的輸出向量稱爲 embeddings,represent x 和 y。 頂部的函數 C 產生一個 scalar 能量,用於測量由共享相同參數 (w) 的兩個相同孿生網絡產生的表示向量 h and h’(embeddings)之間的距離。 當 x 和 y 是同一圖像的略微不同版本時 (i.e. data argument),系統可以容易的調整網絡的參數訓練為產生低能量 (argument invariant),這迫使模型為兩個圖像產生相似的嵌入向量。 困難的部分是如何訓練模型,使其為不同的圖像產生高能量(different embeddings)。
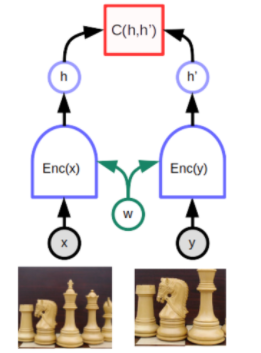
困難在於當 x 和 y 是不同的圖像時,要確保網絡產生高能量,即不同的嵌入向量。 如果沒有特定的方法,這兩個網絡可以很快樂的忽略它們的輸入並始終產生相同的輸出嵌入。 這種現象稱為 collapse。 當 collapse 發生時,不匹配的 x 和 y 的能量並不高於匹配 x 和 y 的能量。
有兩類技術可以避免 collapse:contrastive methods and regularization methods。
Contrastive Energy-Based SSL
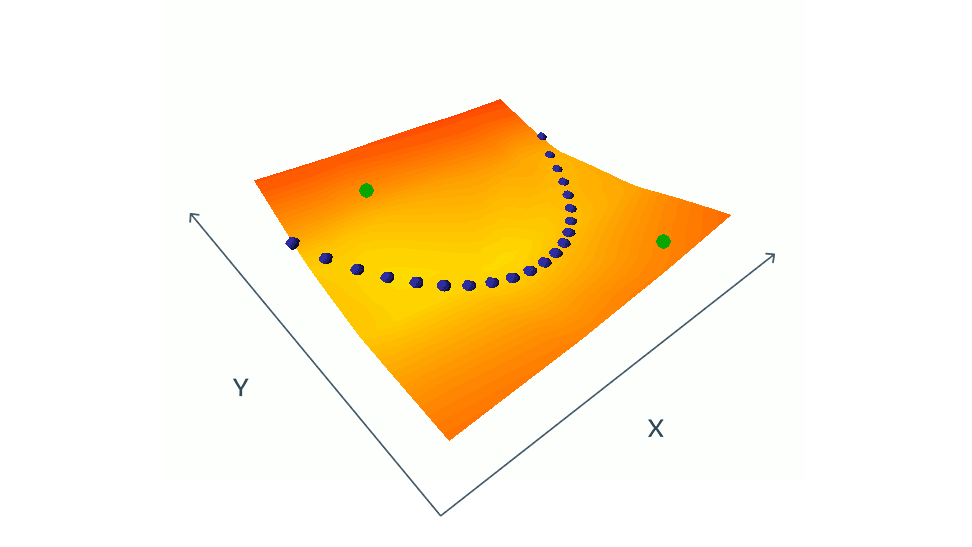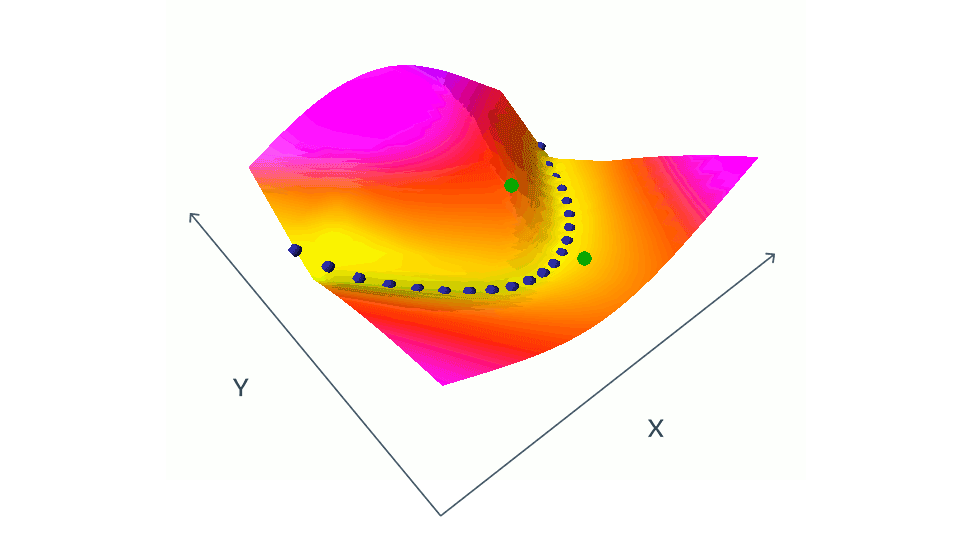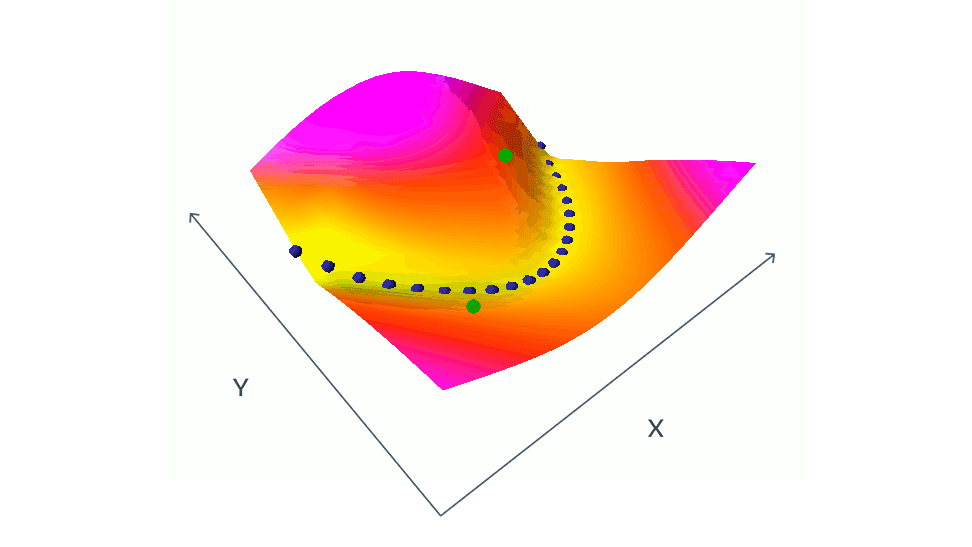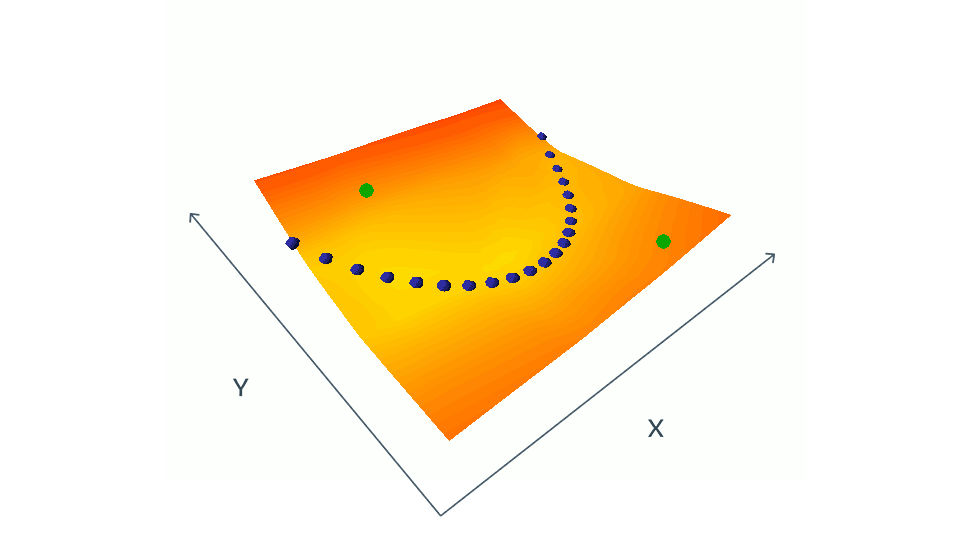
Contrastive method 想法很簡單,就是建構 incompatible x, y pairs, i.e. negative pair,並調整模型的參數,使相應的輸出 energy 變大 (超過 positive x, y pairs )。
下圖顯示使用 contrastive method 訓練 EBM 的策略:同時要下壓 positive (x,y) pairs 的能量 (藍點),並上推精選的 negative (x,y) pairs 的能量 (綠點)。 在這個簡單的例子中,x 和 y 都是純量 (scalar),但在實際情況下,x 和 y 可能是具有數百萬維的圖像或視頻。 要找到 negative pairs (綠點) 塑造適當的能量 function 是非常有挑戰性 (需要一些創意) 而且高計算成本。
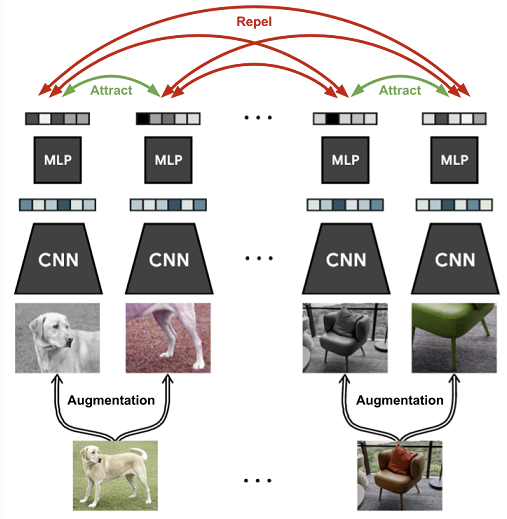
Example 1: Joint embedding method: simCLR - Simple Framework for Contrastive Learning
SimCLR 是 Hinton 團隊在 SSL 領域的一個經典工作 [@chenSimpleFramework2020]。基本架構如下圖所示,就是標準的 joint embedding network. 具體方法
- 對圖像作隨機的augmentation,包含random crop, color distortion和Gaussian blur,使得同一張圖片會衍生出兩種變體,文章中將這一對變體稱作Positive Pair. 研究顯示 color distortion 和 crop 的組合下,訓練出的效果最好。
- 以ResNet作為 CNN encoder,負責萃取圖像中的特徵,以向量形式輸出
- 用 MLP 作為 projection head,把上一步的特徵再進行一次轉換
- 透過contrastive loss,訓練模型能對Positive Pair輸出近乎相同的向量
- 訓練過程中,數量為N的minibatch會經由隨機augmentation變成2N筆資料。取其中一對源自同一張圖片的資料當作 positive pair,剩下的 2(N-1) 筆資料作為 negative pairs,並對每一組 positive pair 算出一個 loss
Example 2: Prediction method: NLP Mask Learning
通過屏蔽 (mask) 或替換 (substitute) 某些輸入詞來訓練 NLP 系統的方法屬於 prediction method. 乍看之下和 contrastive method 不一樣。但還是可以變形成 contrastive method 的範疇。 不過 prediction method 並不使用 joint embedding 架構 (i.e. 相同的 encoders of shared weight),而是使用 predictive 架構,模型直接生成對 y 的預測如下圖。
從 text y 的完整句子開始,然後損壞它,例如,通過隨機屏蔽一些單詞來產生 observation x。 損壞的輸入被饋送到一個大型神經網絡,該網絡經過訓練可以再現原始文本 y。 未損壞的 text 重新生成自身 (low reconstruction error),而損壞的 text 將重新生成自身的未損壞版本 (large reconstruction error)。 如果將 reconstruction error 詮釋為一種能量,它具有所需的屬性:“乾淨” text 的低能量和 “損壞” text 的高能量。
總結來說,就是 positive pairs (unmask words) 和 negative pairs (mask words) 是在一個同一個句子輸入一個網路。而不是像 joint embedding method 使用兩個相同的 networks, for both positive pairs and negative pairs of different imges.
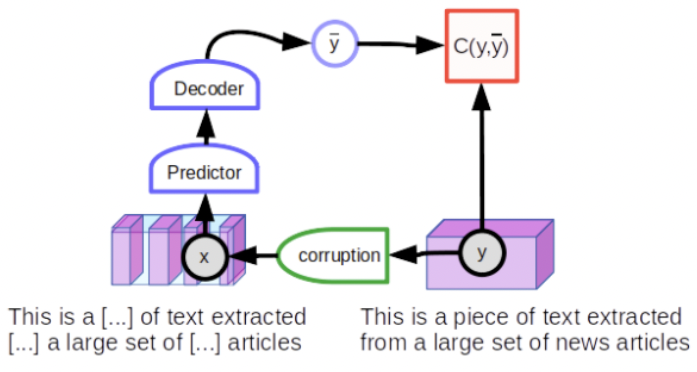
訓練模型以恢復輸入的損壞版本的技術稱為 denoising auto-encoder。 雖然這個想法最早可以追溯到 1980 年代,但在 2008 由 Vincent of Montreal 重新提出做為 robust feature extraction 的理論基礎 [@vincentExtractingComposing2008]。並在 NLP 的領域再度復活:Make language model 可以視為 denoising auto-encoder 的一個實例。
這種類型的 predictive architecture 對於給定的輸入只能產生一個預測。 由於模型必須能夠預測多個可能的結果,因此預測不是一個單詞,而是每個 mask words 位置的詞彙表中每個單詞的一系列分數。對於 NLP of limited set of possible words 可行,但對於 masked image of very high dimension (幾乎有無限可能性) 是否可能? LeCun 認為很困難,或至少無法和 joint embedding method 的結果相比。
Example 3: MAE - Mask Auto-Encoder
一個自然的問題是 image SSL 除了 joint embedding 的 contrastive learning (simCRL) 之外,是否可以用類似 NLP mask learning 的 predictive method? LeCun 認爲很困難。不過 Kaiming He 在 2021 提出 MAE (Mask autoencoder) method 似乎彌補這個部分。
Example 4: Latent-variable Predictive method: GAN?
不過 LeCun 提出一個 latent-variable predictive (潛變量預測) architectures: 給定一個觀測值 x,該模型必須能夠產生一組多個兼容的預測,在圖中用 S 形表示。 由於潛變量 z varies within a set,用灰色方塊表示,對應的輸出也在 a set of 合理的預測上變化。
潛變量預測模型包含一個額外的輸入變量 (z)。因為它的值從未被觀察,所以被稱為 latent variable。 使用經過適當訓練的模型,as the latent variable variesover a given set, the output prediction varies over the set of plausible predictions compatible with the input x. 這不是新鮮的做法,基本和 variational autoencoder 概念一樣。
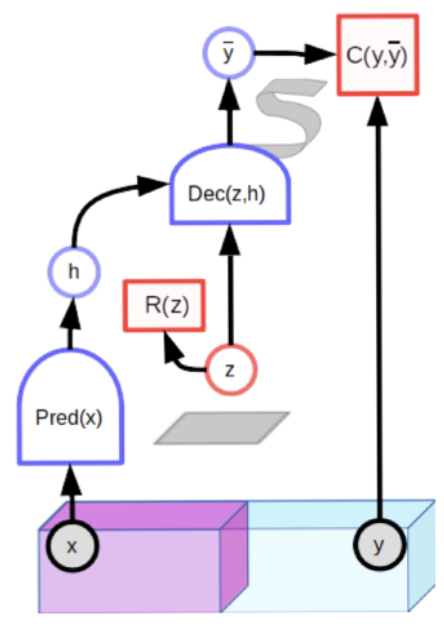
潛變量模型可以用對比方法進行訓練。一個很好的例子是生成對抗網絡(GAN)。Unconditional GAN 其實也是 self-supervised learning. The $C(y, \bar{y})$ 也就是 discriminator can be seen as computing an energy indicating whether the input y looks good。生成器網絡被訓練以產生對比樣本,discriminator 則被訓練分辨對比樣本並給予高能量。
但是對比方法有一個主要問題:它的訓練效率非常低。以高維空間的圖像爲例,一張圖像與另一張圖像有很多不同之處。找到一組對比圖像,涵蓋它們與給定圖像的所有不同方式,這幾乎是一項不可能完成的任務。套用托爾斯泰的安娜·卡列尼娜的話:“幸福的家庭都是相似的;每個不幸的家庭都有自己的不幸。”這似乎適用於任何高維對象。
如果有可能確保不相容對的能量高於相容對的能量,但不明顯的推高許多不相容對的能量呢?
Non-Contrastive Energy-Based SSL
應用於 joint embedding 架構的”非對比方法”可能是目前 SSL 視覺領域最熱門的話題。 該領域在很大程度上仍未充分探索,但似乎很有希望。
Joint embedding 的非對比方法包括 DeeperCluster, ClusterFit, MoCo-v2, SwAV, SimSiam, Barlow Twins, BYOL from DeepMind, and a few others. 他們使用各種技巧,例如為相似圖像組計算 virtual target embeddings(DeeperCluster、SwAV、SimSiam)或通過架構或參數向量(BYOL、MoCo)使兩個 joint embedding 架構略有不同。 Barlow Twins 試圖最小化嵌入向量的各個組件之間的冗餘。
再來 LeCun 提出了 latent-variable preditive model + non-contrastive method 並且說 VAE 是很好的例子?