Reference
[@gaoEyesRobots2016] - Good introductory SLAM art
[@kleinParallelTracking2007] - PTAM SLAM
[@xiaomiORBSLAMLearning2019] - ORB SLAM
[@triggsBundleAdjustment2000] : comprehensive article
vSLAM
SLAM為simultaneous localization and mapping的英文縮寫,也就是同時定位與建圖,localization在討論的是求出感測器自身的位置,mapping在研究的是環境周遭的模型。下圖是 SLAM 直觀的理解:爲什麽需要 “map”, “location”, 和 “simultaneous”.

用一個更具體的例子來解釋SLAM的研究內容:去外地念書的時候,剛搬進宿舍,環境都還不熟通常我們都會
- 先觀察附近的環境,看什麼東西跟路標(特徵提取,feature extraction)
- 邊走邊觀察環境,同時根據那些路標更新地圖(update pose estimation and map)
- 在腦袋中記住並重現那些東西跟路標(建圖)
- 同時也要根據路上的特徵確定自己的位置(video odometry)
- 走了一段時間,和腦袋中的地圖進行匹配,看現在走的地方之前走過了沒(closed loop detection)。
而構建地圖跟確認自己 (在地圖) 的位置這兩件事是同時進行的,所以用 simultaneous。藉由這個小故事我們可以得知:人的眼睛就是某種感測器,我們在不了解環境的情況下,在運動過程中建立環境模型,同時估計自己的運動位姿(i.e. 移動軌跡加上轉動軌跡),這就是SLAM研究的課題。
vSLAM Key Concept
vSLAM 幾個重要的概念:
-
一般假設感測器 (camera) 是運動,環境 (路標) 則是靜止。
-
運動位姿包含移動軌跡加上轉動軌跡。2D 運動具有 3 DOF (Degree of Freedom) 位姿 ;3D 運動具有 6 DOF 位姿。
-
數學上可以用兩個方程式描述位姿和觀測。熟悉 state-space model reader 應該覺得很熟悉。不過 SLAM 一般是非綫性方程式。Kalman filter 其實就是 linear state-space model 的解。
-
**Camera 軌跡和位姿 (trajectory and pose) 運動方程 **:考慮從 k-1 到 k 時刻,感測器位姿 x 是如何變化的(u 是感測器的數據,w 是雜訊)。我們也稱 x 為 state, 需要從觀測 inference.
-
觀測方程 (observations with noise):當感測器在位置 x 上觀測到的路標點 y,產生的觀測數據 z(v 是雜訊)。
-
定位和路標
一個問題是如何定位和找到路標 ! 這就是 feature extraction and matching (特徵提取和匹配)
如果你熟悉計算機視覺,那你應該聽說過SIFT, SURF之類的特征。不錯,要解決定位問題,首先要得到兩張圖像的一個匹配。匹配的基礎是圖像的特征,下圖就是SIFT提取的關鍵點與匹配結果:

位姿估計 state-space equation
如下圖,我們藉由運動方程及觀測方程,在知道 $u_i$(感測器相對位姿變化)及 $z_{i,j}$(路標觀測數據 in local coordinate)的情況,估計 $x_i$(location, 感測器位姿 in global coordinate)及 $y_j$(map, 實際路標點 in global coordinate),也就是個定位 (location) 及建圖 (map) 的問題。
Location (global coordinate): $\quad x_{i}, i=1, \ldots, n$ Landmarks (global coordinate): $\quad y_{j}, j=1, \ldots, m$ Motion equation (global coordinate): $\quad x_{i+1}=f\left(x_{i}, u_{i}\right)+w_{i}$ Observations equation (local coordinate): $\quad z_{i, j}=h\left(x_{i}, y_{j} \right) + v_{i, j}$
注意因爲 camera 視角和遮蔽的關係, $z_{i,j}$ 並非對所有 $(i,j)$ 都觀察的到。
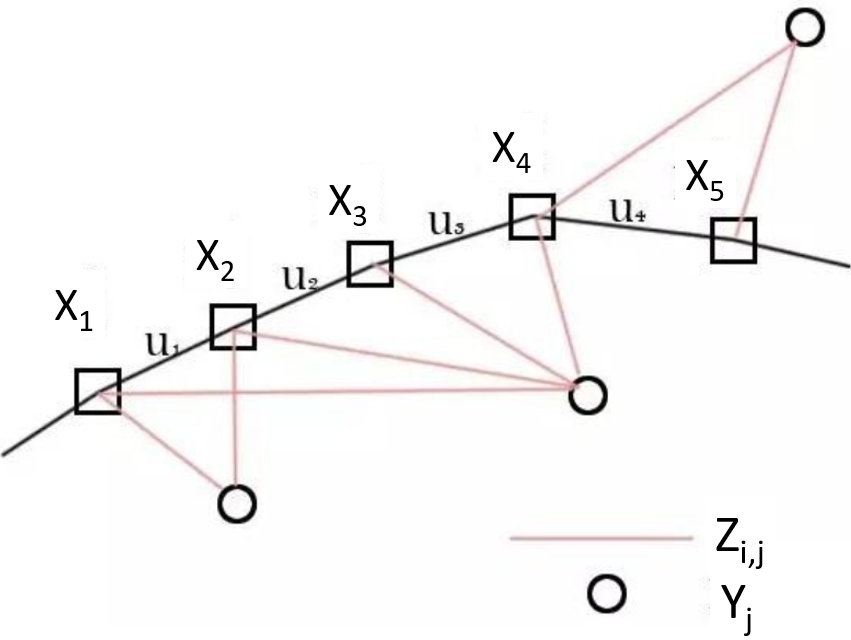
2D 運動方程 : 由兩個位置 (x,y) 及一個轉角來描述camera 位姿 (3DOF)
3D 運動方程 : 由三個位置 (x,y,z) 及三個角度來描述 camera 位姿 (6DOF)
注意這裏的 3DOF or 6 DOF 都是 state variables under estimation. 需要靠著運動方程式和 observations (camera image, Lidar point cloud, or IMU) 來估計。
Example: 2D 觀測方程 (以二維激光感測器為例): 激光感測器觀測到一個 2D 路標 $y=[p_x, p_y]^T$, 觀測數據為 $z=\left[\begin{array}{ll}r, \varphi\end{array}\right]^T$ \(\begin{aligned} &x_{i+1}=f\left(x_{i}, u_{i}, w_{i}\right) \\ &{\left[\begin{array}{l} x \\ y \\ \theta \end{array}\right]_{i}=\left[\begin{array}{l} x \\ y \\ \theta \end{array}\right]_{i-1}+\left[\begin{array}{c} \Delta x \\ \Delta y \\ \Delta \theta \end{array}\right]_{i}+w_{i} .} \end{aligned}\)
\[\begin{aligned} &z_{i, j}=h\left(y_{j}, x_{i}, v_{i, j}\right) \\ &{\left[\begin{array}{l} r \\ \phi \end{array}\right]=\left[\begin{array}{l} \sqrt{\left(p_{x}-x\right)^{2}+\left(p_{y}-y\right)^{2}} \\ \arctan \left(\frac{p_{y}-y}{p_{x}-x}\right) \end{array}\right]+\boldsymbol{v} .} \end{aligned}\]此時,我們已經把原本的SLAM問題變成了一個 states (3DOF) 估計問題,狀態估計問題的求解。注意一般 mono camera 沒有 depth information.
Kalman Filter Vs. Graph Optimization (G2O)/Bundle Adjustment (BA)
兩種位姿估計 (estimation) 做法 (1) 濾波派 (Kalman filter) 和 (2) Bundle adjustment (BA),也就是 nonlinear least square optimization 派。
Kalman Filter (微分法)
- vSLAM 最初多采用濾波派做法。依照這兩個方程式線性與否及雜訊是否成高斯分佈,分為四種系統,四個系統的最優估計會使用不同的方法,例如線性高斯系統可使用Kalman Filter,而非線性非高斯則會使用Extended Kalman Filter。這是 leverage state-space model 的做法。
-
這裏不介紹 Kalman 濾波器,有興趣的同學可以在wiki Kalman 濾波器。由於濾波器方法有幾個缺點,不適合移動終端
-
存儲 n 個路標要消耗 n 平方的空間,在計算量不適合移動終端。
-
一般 Kalman 分爲 prediction step (tracking), update step (mapping), 再重複這兩步。tracking & mapping 兩者是 sequential 無法平行化。如果有大量路標,mapping 可能會變成瓶頸。
-
Kalman filter 雖然是 linear state space model 的 optimal solution, 但對於大的移動或轉動的 nonlinearity equation 所作的 linearization approximation (微分法) 產生的誤差較大。
-
Optimization (變分法)
-
新興的位姿估計方法 把 SLAM 問題做成了一個優化問題 (變分法)。我們不是要求解機器人的位置和路標位置嗎?我們可以先做一個猜測,猜想它們大概在什麽地方。這其實是不難的。然後呢,將猜測值與運動模型/觀測模型給出的值相比較,可以算出誤差:
- From sensor: $z_{i,j}, u_{i}$
- And Initial Guess: $\bar{x}{i}, \bar{y}{j}$
- Then, we can estimate errors from motion and observation equations (P 代表 pose, L 代表 Landmark)
通俗一點地講,例如,我猜機器人第一幀在 (0,0,0),第二幀在 (0,0,1)。但是 $u_1$ 告訴我機器人往 z 方向(前方)走了0.9米,那麽運動方程就出現了0.1m的誤差。同時,第一幀中機器人發現了路標1,它在該機器人圖像的正中間;第二幀卻發現它在中間偏右的位置。這時我們猜測機器人只是往前走,也是存在誤差的。至於這個誤差是多少,可以根據觀測方程算出來。
我們得到了一堆誤差,把這些誤差平方後加起來(因為單純的誤差有正有負,然而平方誤差可以改成其他的範數,只是平方更常用),就得到了平方誤差和。我們把這個平方誤差和記作 $\varphi$,就是我們優化問題的目標函數。而優化變量就是那些 $(x_i, y_j)$。
\[\min \varphi_{x_i, y_j}=\sum_{i}\left(e_{i}^{P}\right)^{2}+\sum_{i, j}\left(e^{L}_{i, j}\right)^{2}\] -
優化的方法有兩類:1st order 只用到梯度/Jacobian (e.g. gradient descent); 2nd order 用到 Hessian (e.g. Gauss-Newton method). 一般使用 2nd order method 因爲收斂快。此處的 $\mathbf{x} = (x_i, y_j)$ \(J=\frac{\nabla \varphi}{\nabla \mathbf{x}}, H=\frac{\nabla^{2} \varphi}{\nabla \mathbf{x} \nabla \mathbf{x}^{T}}\)
-
注意一次 SLAM 過程中,往往會有成千上萬幀。而每一幀我們都有幾百個關鍵點,一乘就是幾百萬個優化變量。這個規模的優化問題放移動終端上可解嗎?過去的同學都以為,Graph-based SLAM 是無法計算的。但就在 2006 後,有些同學發現了,這個問題規模沒有想象的那麽大。上面的 $J$ 和 $H$ 兩個矩陣是“稀疏矩陣”,於是呢,我們可以用稀疏代數的方法來解這個問題。“稀疏”的原因,在於每一個路標,往往不可能出現在所有運動過程中,通常只出現在一小部分圖像裏。正是這個稀疏性,使得優化思路成為了現實。
-
這種優化利用了所有可以用到的 information, 稱爲 full-SLAM, global SLAM. 其精確度比起一開始所説的幀間的匹配高很多。當然計算量也高的多。
Graph Optimization and Bundle Adjustment
由於優化的稀疏性,人們喜歡用“圖”來表達這個問題。所謂圖,就是由節點和邊組成的東西。我寫成G={V,E},大家就明白了。V是優化變量節點,E表示運動/觀測方程的約束。更糊塗了嗎?那我就上一張圖。
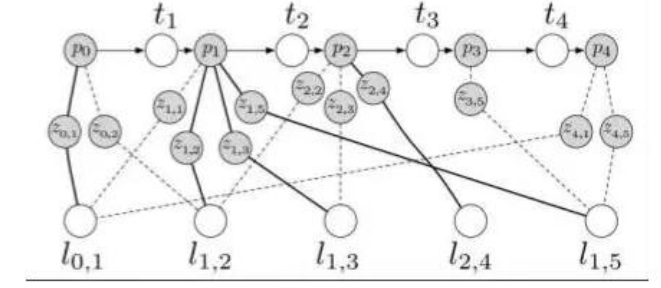
上圖中,p (=x) 是機器人位置,l (=y) 是路標,z 是觀測,t (=u) 是位移。其中呢,p, l (x,y) 是優化變量,而 z,t (z, u) 是優化的約束。看起來是不是像一些彈簧連接了一些質點呢?因為每個路標不可能出現在每一幀中,所以這個圖是蠻稀疏的。
不過,“圖”優化只是優化問題的一個表達形式,並不影響優化的含義。實際解起來時還是要用數值法找梯度的。這種思路在計算機視覺裏,也叫做Bundle Adjustment (BA)。它的具體方法請參見一篇經典文章 [@triggsBundleAdjustment2000].
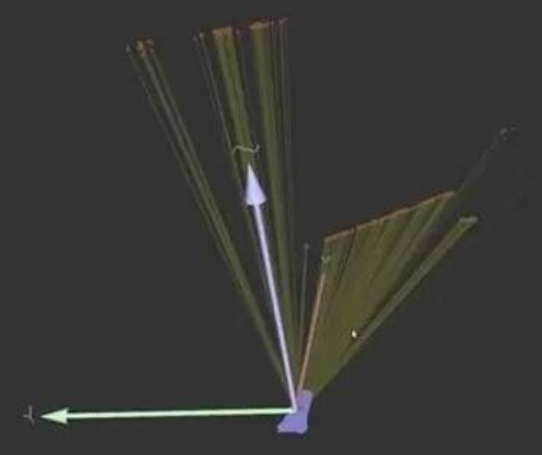
不過,BA的實現方法太覆雜,不太建議同學們拿C來寫。好在2010年的ICRA上,其他的同學們提供了一個通用的開發包:g2o。它是有圖優化通用求解器,很好用。總之,我們只要把觀測和運動信息丟到求解器裏就行。這個優化器會為我們求出機器人的軌跡和路標位置。
如下圖,紅點是路標,藍色箭頭是機器人的位置和轉角(2D SLAM)。細心的同學會發現它往右偏轉了一些:
Bootstrap Initialization
- 需要 bootstrap to initialize the 地圖路標。
- 先利用兩幀圖片初始化,具體方法是先五點法加 RANSAC 求出初值,然後所有匹配點(約1000個)BA優化。由於是單目,所以尺度是未知的,當做常數固定下來。
Localization 誤差累積
SLAM 估計 sequential movement,每一個估計都有一些誤差。 誤差會隨著時間累積,導致與實際值有很大的偏差。 它還可能導致地圖數據崩潰或扭曲,導致後續搜索變得困難。我們以在方形通道周圍行駛為例。 隨著誤差的累積,機器人的起點和終點不再匹配。 這稱為閉環問題。 像這樣的 pose estimation errors 是不可避免的。 檢測閉環並確定如何糾正或消除累積的錯誤非常重要。
關鍵幀 (Key Frame) 和閉環檢測 (Close Loop Detection)
上面提到,僅用幀間匹配 (front-end, tracking thread) 最大的問題在於誤差累積,圖優化 (back-end, mapping thread) 的方法可以有效地減少累計誤差。然而,如果把所有測量都丟進 g2o,計算量還是有點兒大的。根據我自己測試,約10000多條邊,g2o跑起來就有些吃力了。這樣,就有同學說,能把這個圖構造地簡潔一些嗎?我們用不著所有的信息,只需要把有用的拿出來就行了。
Method 1: 引入關鍵幀
最簡單就是如果位姿變化沒有超過一個 threshold 就忽略。注意這是指 mapping phase, 不是 tracking phase. 在 tracking phase 每一幀都要用來產生 $u_i$. 但是用於 optimization (變分法) 最好是累積一定的變化再做 correction。
例如 PTAM 是用以下幾個角度判斷當前幀是否是關鍵幀:1)tracking 效果好;2)距離上一個關鍵幀至少20幀圖片;3)距離最近的地圖點大於一個閾值,這是為了保證baseline足夠大。如果當前幀不是關鍵幀,則做BA優化。
下圖是其中的説明。新的 key frame 帶入新的路標資訊。
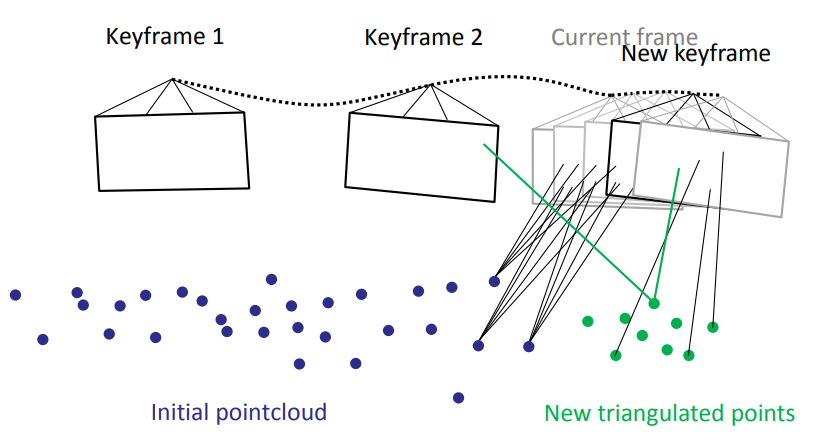
Method 2: 引入閉環檢測
事實上,robot 在探索房間時,經常會左轉一下,右轉一下。如果在某個時刻他回到了以前去過的地方,我們就直接與那時候采集的關鍵幀做比較,可以嗎?我們說,可以,而且那是最好的方法。這個問題叫做閉環檢測。
閉環檢測是說,新來一張圖像時,如何判斷它以前是否在圖像序列中出現過?
有兩種思路:一是根據我們估計的機器人位置,看是否與以前某個位置鄰近;二是根據圖像的外觀,看它是否和以前關鍵幀相似。
目前主流方法是後一種,因為很多科學家認為前一種依靠有噪聲的位置來減少位置的噪聲,有點循環論證的意思。後一種方法呢,本質上是個模式識別問題(非監督聚類,分類),常用的是 Bag-of-Words (BOW)。但是 BOW 需要事先對字典進行訓練,因此SLAM研究者仍在探討有沒有更合適的方法
在Kinect SLAM經典大作中,作者采用了比較簡單的閉環方法:在前面n個關鍵幀中隨機采 k 個,與當前幀兩兩匹配。匹配上後認為出現閉環。這個真是相當的簡單實用,效率也過得去。
高效的閉環檢測是SLAM精確求解的基礎。研究者也在嘗試利用深度學習技術提高閉環檢測的精度,例如本文作者發表在Autonomous Robot期刊上的論文Unsupervised Learning to Detect Loops Using Deep Neural Networks for Visual SLAM System采用了無監督的深度自動編碼機從原始輸入圖像中學習緊湊的圖像表示,相比於傳統的Bag of Word方法提高了閉環檢測的 robustness。
vSLAM Building Blocks
經過剛才的介紹,我們大概可以把 vSLAM分成幾個部分:
-
Visual Odometry (VO) or Front End (通常稱爲 tracking thread):特徵提取和匹配,以及估計相鄰畫面(圖片)間感測器的的運動關係。具體說就是從兩張相鄰畫面計算 camera 的位姿變化: $z_{i,j}, z_{i+1, j} \to u_i$。
-
Pose Estimation/Optimization or Back End (通常稱爲 mapping thread):透過狀態 (states) 來表達自身及環境加上噪聲的不確定性,並採用濾波器或圖優化去估計狀態 (estimate states) 的均值和不確定性。就是從多張畫面估計 camera 位姿和路標:$z_{i,j}, u_i \to x_i, y_j$
-
Closed Loop Detection,透過感測器能識別曾經來到過此地方的特性,解決隨時間漂移的情況;
-
Mapping,根據估計的軌跡,建立對應的地圖。
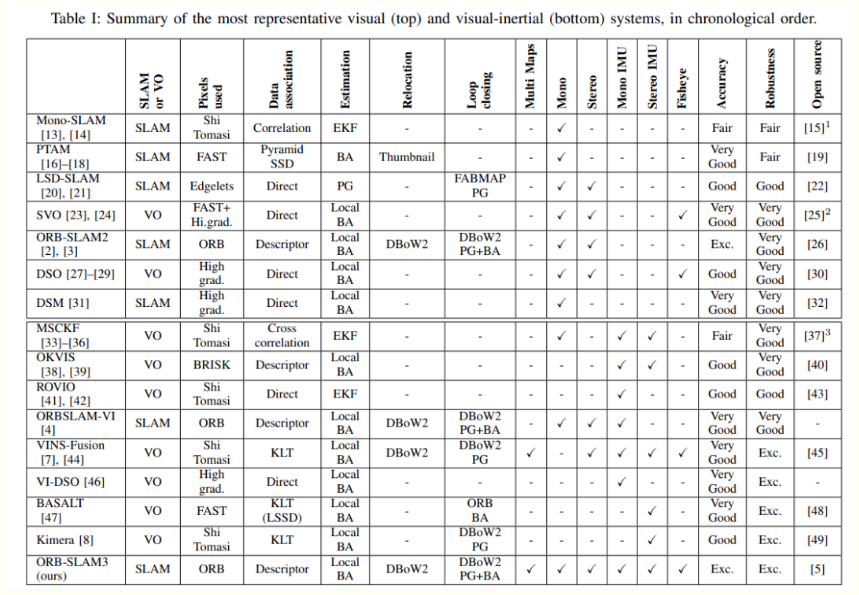
下表列舉幾個比較有名的 vSLAM 算法:LSD-SLAM, Mono-SLAM, PTAM, ORB-SLAM, RGBD-SLAM, RTAB-SLAM。 不同的 vSLAM 算法的主要差別就在 front-end 的特徵提取算法和 backend-end 的優化算法。
| Input | Front end (Sparse or Dense) | Back end (Filter or Graph) | |
|---|---|---|---|
| LSD (large scale direct) | Mono | NA (direct and sparse) | KF |
| Mono SLAM | Mono | KF | |
| BASALT | Mono + IMU? | FAST (sparse) | EKF+BA |
| PTAM | Mono | FAST (sparse) | BA (graph) |
| ORB SLAM | Mono | ORB: Oriented FAST and Rotated BRIEF | BA (G2O) |
| ORB SLAM2 | Stereo/RGB-D | ORB | BA |
| ORB SLAM2s | optical flow? | ||
| RTAB SLAM | RBG-D | ||
| ORB SLAM3 |
VO: tracking only (?); SLAM: tracking+optimization(+mapping)
接下來我們針對幾個有名的 vSLAM 算法介紹:
-
Kalman filter based SLAM : single process for tracking and mapping on every frame, not real-time
-
PTAM : parallel tracking (every frame) & mapping (key frame) processes
-
ORB : parallel tracking, mapping, and looping processes
Example 1: vSLAM: PTAM (Parallel Tracking And Mapping)
PTAM 是視覺SLAM領域裏程碑式的項目 [@kleinParallelTracking2007]。在此之前,MonoSLAM 為代表的基於卡爾曼濾波的算法架構是主流,它用單個線程逐幀更新相機位置姿態和地圖。地圖更新的計算覆雜度很高,為了做到實時處理(30Hz),MonoSLAM 每幀圖片只能用濾波的方法處理約10~12個最穩定的特征點。
PTAM最大的貢獻是提出了 tracking、mapping 雙線程的架構,如下圖:tracking 線程只需要逐幀更新相機位置姿態,可以很容易實現實時計算;而 mapping 線程並不需要逐幀更新,why?,有更長的處理時間,原來只能用在離線 SfM(Structure from Motion)的 BA(Bundle Adjustment)也可以用起來。
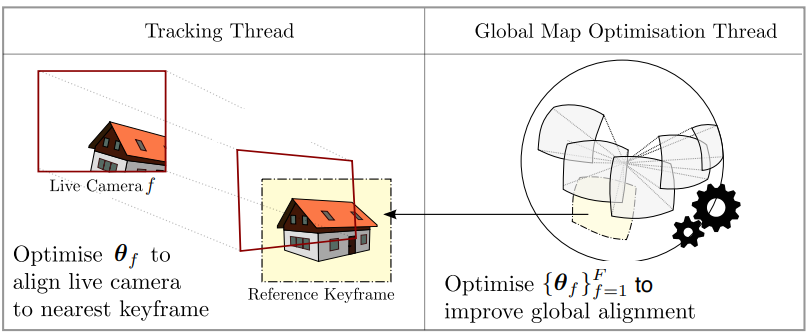
Why? 因爲 (i) 路標是靜止的,沒有 real-time 需求,所以不需要逐幀更新;(ii) 但是 optimized camera pose 即使落後幾幀,還是可以用於 correct pose (e.g. VIO?)
這種基於優化的算法比濾波法在單位計算時間可以得到更高的精度。這種多線程的處理方式也更順應現代CPU的發展趨勢。之後的 vSLAM 算法幾乎全部沿用了這一思想。
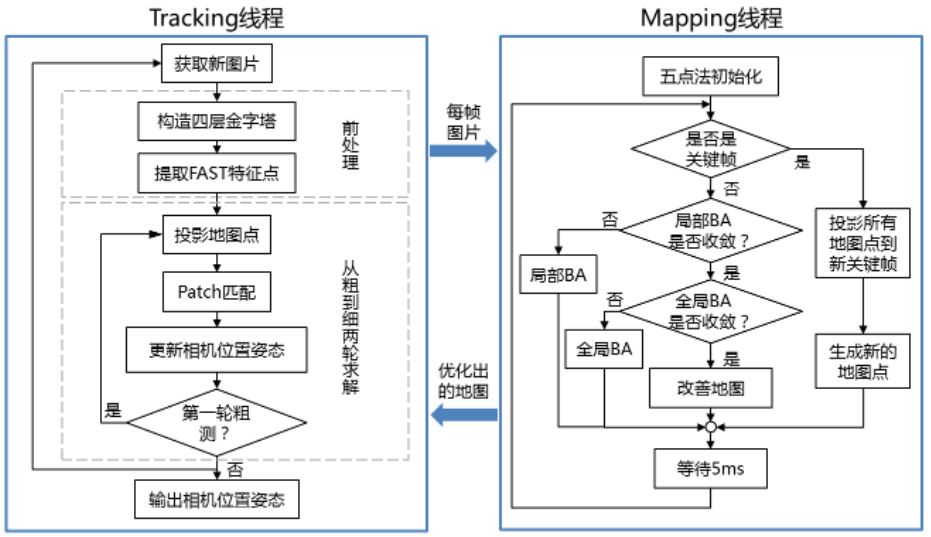
Tracking 線程:
-
地圖(由地圖點和關鍵幀組成)是已知且固定的。對圖片構造金字塔的目的有兩個:1)加快匹配;2)提高地圖點相對於相機遠近變化時的魯棒性。FAST是常用的特征點,優點是快,缺點是不 robust。通常會先提取出大量的(成百上千個)FAST特征,然後用各種約束剔除誤匹配。
- 基於運動模型(PTAM選用減速模型,一般勻速模型更常見)假定當前幀的初始位置姿態,把地圖點投影到當前幀,建立起當前幀和關鍵幀(每個地圖點會關聯第一次觀察到它的關鍵幀)的聯系。隨後在匹配點附近找一塊小區域(這就是所謂的patch),通過比較當前幀和關鍵幀的patch的相似度(計算SSD),可以剔除誤匹配
- PTAM用三個級別評判tracking質量:好、不好、丟失。只會在 “好” 的狀態下插入新關鍵幀和地圖點,如果“丟失”,會有簡單的重定位功能(在所有關鍵幀中找相似的)。
Mapping 線程:
- 優化對象是地圖點位置和關鍵幀位置姿態,不再考慮當前幀的位置姿態。
- 先利用兩幀圖片初始化,具體方法是先五點法加 RANSAC 求出初值,然後所有匹配點(約1000個)BA優化。由於是單目,所以尺度是未知的,當做常數固定下來。
- 首先從以下幾個角度判斷當前幀是否是關鍵幀:1)tracking 效果好;2)距離上一個關鍵幀至少20幀圖片;3)距離最近的地圖點大於一個閾值,這是為了保證baseline足夠大。如果當前幀不是關鍵幀,則做BA優化。
- PTAM把BA優化分為局部和全局兩部分,這和tracking線程從粗到細兩輪求解是一個思路,都是為了降低計算覆雜度,加速求解。在局部BA階段,只考慮滑動窗內的關鍵幀(5幀),以及它們能觀測到的所有地圖點。額外的約束是能觀測到這些地圖點的其他關鍵幀,這些關鍵幀固定不動,並不是優化對象。
- 全局BA階段,優化對象納入所有的關鍵幀和地圖點。在閑暇時間mapping線程可以利用舊的關鍵幀改善地圖,要麽從舊的關鍵幀觀察新添加的地圖點,要麽重新測量之前被剔除的外點,如果被成功觀測並收斂,則作為新的地圖點插入地圖。如果當前幀是關鍵幀,則做兩件事情:1)把所有地圖點投影到這個新的關鍵幀(tracking線程處於計算量的考慮只投影了一部分地圖點),為之後的BA做準備;2)生成新的地圖點,會對新關鍵幀的特征點做非極大值抑制,並篩選出最顯著(Shi-Tomasi 分數)的一批特征點,然後在最近的關鍵幀上沿極線搜索匹配點,只要能找到匹配點,就三角化出地圖點。
Example 2: vSLAM: ORB-SLAM
ORB-SLAM 是西班牙 Zaragoza 大學的 Raúl Mur-Arta 編寫的 vSLAM 系統。 它是一個完整的 SLAM 系統,包括visual odometry (VO)、tracking、mapping, re-localization, and loop closing,是一種完全基於稀疏特征點的單目 SLAM 系統,同時還有單目、雙目、RGBD 相機的接口。其核心是使用 ORB (Oriented FAST and Rotated BRIEF) 作為整個 vSLAM 中的核心特征。
ORB-SLAM 基本延續了 PTAM 的算法框架,但對框架中的大部分組件都做了改進, 歸納起來主要有 4 點:
- ORB-SLAM 選用了 ORB 特征 (step 1), 基於 ORB 描述量的特征匹配和重定位, 都比 PTAM FAST 具有更好的視角不變性。此外, 新增三維點的特征匹配效率更高, 因此能更及時地擴展場景。擴展場景及時與否決定了後續幀是否能穩定跟蹤。
- ORB-SLAM 加入了 loop closing 的檢測和閉合機制 (step 5), 以消除誤差累積。系統采用與重定位相同的方法來檢測回路(匹配回路兩側關鍵幀上的公共點), 通過方位圖 (Pose Graph) 優化來閉合回路。
- PTAM 需要用戶指定 2 幀來初始化系統, 2 幀間既要有足夠的公共點, 又要有足夠的平移量. 平移運動為這些公共點提供視差 (Parallax) , 只有足夠的視差才能三角化出精確的三維位置。ORB-SLAM 通過檢測視差來自動選擇初始化的 2 幀。
- PTAM 擴展場景時也要求新加入的關鍵幀提供足夠的視差, 導致場景往往難以擴展. ORB-SLAM 采用一種更 robust 的關鍵幀和三維點的選擇機制——先用寬松的判斷條件盡可能及時地加入新的關鍵幀和三維點, 以保證後續幀的 robust 跟蹤; 再用嚴格的判斷條件刪除冗余的關鍵幀和不穩定的三維點,以保證 BA 的效率和精度。
ORB-SLAM block diagram (Mono)
PTAM 引入 tracking and mapping 分開運行的觀念。ORB-SLAM 再改善加上 looping,如下圖。
ORB-SLAM 它是由三大塊、三個綫程同時運行的。第一塊是跟蹤 (tracking),第二塊是建圖 (mapping),第三塊是閉環檢測 (loop closing)。
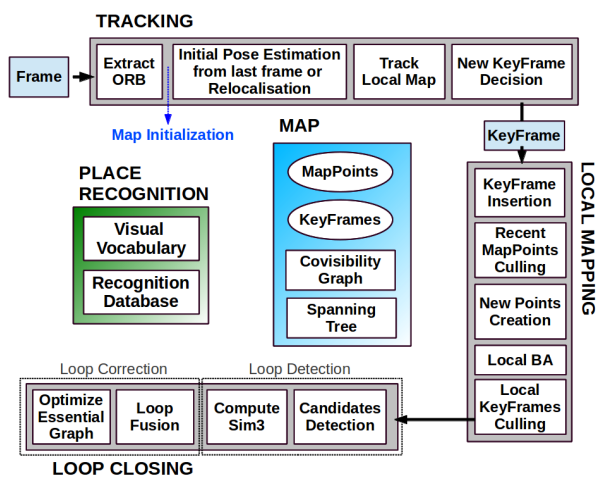
-
跟蹤(Tracking) - Frontend and timing critical 這一部分主要工作是從 mono 圖像用 ORB 特徵提取,根據上一幀進行姿態估計,或者進行通過全局重定位初始化位姿,然後跟蹤已經重建的局部地圖,優化位姿,再根據一些規則確定新關鍵幀。
-
建圖(Local Mapping)- Backend 這一部分主要完成局部地圖構建 (step 3)。包括對關鍵幀的插入,驗證最近生成的地圖點並進行篩選,然後生成新的地圖點,使用 Local BA,最後再對插入的關鍵幀進行篩選,去除多余的關鍵幀。
-
閉環檢測(Loop Closing)- Backend 這一部分主要分為兩個過程,分別是閉環探測和閉環校正。閉環檢測先使用 WOB 進行探測,然後通過 Sim3 算法計算相似變換。閉環校正,主要是閉環融合和 Essential Graph 的圖優化。
優點
- 一個代碼構造優秀的視覺 SLAM 系統,非常適合移植到實際項目。
- 采用 G2O 作為後端優化 (backend graph optimization) 工具,能有效地減少對特征點位置和自身位姿的估計誤差。
- 采用 DBOW 減少了尋找特征的計算量,同時回環匹配和重定位效果較好。重定位:比如當機器人遇到一些意外情況之後,它的數據流突然被打斷了,在 ORB-SLAM 算法下,可以在短時間內重新把機器人在地圖中定位。
- 使用了類似「適者生存」的方案來進行關鍵幀的刪選,提高系統追蹤的 robustness 和系統的可持續運行。
- 提供最著名的公共數據集( KITTI 和 TUM 數據集)的詳盡實驗結果,以顯示其性能。
- 可以使用開源代碼,並且還支持使用 ROS?。 (Github: slightech/MYNT-EYE-ORB-SLAM2-Sample)
缺點
-
構建出的地圖是稀疏點雲圖。只保留了圖像中特征點的一部分作為關鍵點,固定在空間中進行定位,很難描繪地圖中的障礙物的存在。
-
初始化時最好保持低速運動,對準特征和幾何紋理豐富的物體。
- 旋轉時比較容易丟幀,特別是對於純旋轉,對噪聲敏感,不具備尺度不變性。
- 如果使用純視覺 vSLAM 用於機器人導航,可能會精度不高,或者產生累積誤差,漂移,盡管可以使用 DBoW 詞袋可以用來回環檢測。最好使用 VSLAM+IMU 進行融合,可以提高精度上去,適用於實際應用中機器人的導航。
ORB-SLAM2 block diagram (Stereo/RGB-D)
ORB-SLAM2 在 ORB-SLAM 的基礎上,還支持標定後的雙目相機和 RGB-D 相機。雙目對於精度和 robustness 都會有一定的提升。ORB-SLAM2 是基於單目,雙目和 RGB-D 相機的一套完整的 SLAM 方案。它能夠實現地圖重用,回環檢測和重新定位的功能。無論是在室內的小型手持設備,還是到工廠環境的無人機和城市裏駕駛的汽車,ORB-SLAM2 都能夠在標準的 CPU 上進行實時工作。ORB-SLAM2 在後端上采用的是基於單目和雙目的光束法平差優化(BA)的方式,both local and full BA,這個方法允許米制比例尺的軌跡精確度評估。此外,ORB-SLAM2 包含一個輕量級的定位模式,該模式能夠在允許零點漂移的條件下,利用視覺裏程計來追蹤未建圖的區域並且匹配特征點。
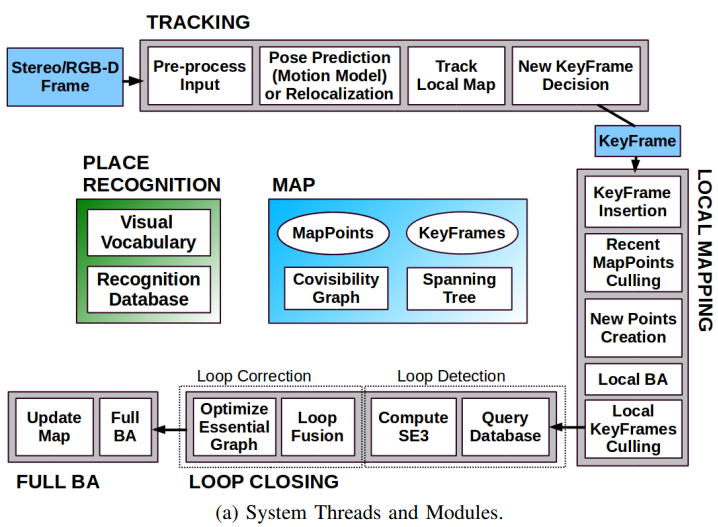
ORB-SLAM2 Input Preprocessing : 使用 stereo instead of mono. 多做了 stereo matching 產生 stereo/mono keypoints.
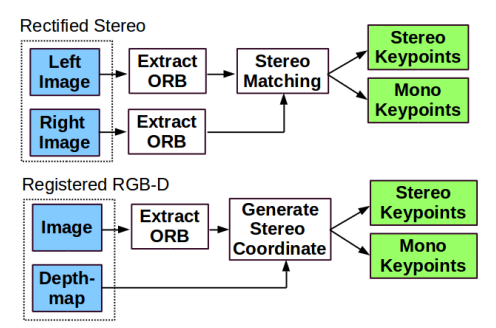
ORB-SLAM2S uses sparse optical flow to speed up
ORB-SLAM3 block diagram (with IMU)
ORB-SLAM3 是一個支持視覺 (VO)、視覺加慣導 (VIO)、混合地圖的 SLAM 系統,可以在單目,雙目和RGB-D相機上利用針孔或者魚眼模型運行。
-
ORB-SLAM3 是第一個基於特征的緊耦合的VIO系統,僅依賴於 MAP 估計 (包括IMU在初始化時)。這樣一個系統的效果就是:不管是在大場景還是小場景,室內還是室外都能 robust 實時的運行,在精度上相比於上一版提升了2到5倍。
-
第二個創新點是根據改進 recall 的新的重定位模塊來構建的混合地圖,因為這個模塊他可以讓 ORB-SLAM3 在特征不是很好的場景中長期運行:當 odometry 失敗的時候,系統會重新構建地圖並將這個地圖和原來構建的地圖對齊。和那些僅利用最新的幾幀數據的裏程計相比,ORB-SLAM3是第一個能夠在所有算法階段重用所有先前信息的系統。這樣的機制就可以在 BA 的時候用有共視關系的關鍵幀,即使兩幀在時間相差很遠,或者來自原來的建圖過程。這個系統在EuRoC數據集上達到了平均3.6cm的精度,在TUM-VI這種利用手持設備快速移動的數據集 (AR/VR場景) 上達到了9mm的精度。
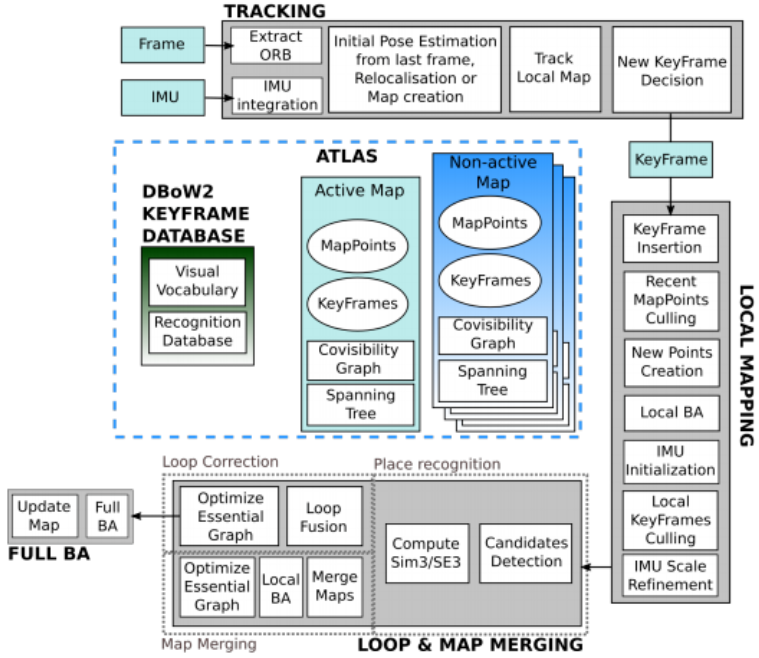
一些關鍵詞
Front-end Feature Extraction
What is ORB - Oriented FAST and Rotated BRIEF
Bundle adjustment (BA) is known to provide accurate estimates of camera localizations as well as a sparse geometrical reconstruction. ORB-SLAM BA
- corresponding observations of scene features (map points) among a subset of selected frames (keyframes)
- keyframes complexity grows, to avoid select the unnecessary redundancy.
- a strong network configuration of keyframes and points to produce accurate results.
- the ability to performance fast global optimization (pose graph) to close loops in real-time.