Reference
[@fxrDeepLearning2018]
Introduction
隨著近幾年深度學習技術的火熱,越來越多的研究工作嘗試將深度學習引入到SLAM中去,有些工作也取得了較為不錯的效果。本文嘗試對相關工作進行簡單梳理,並探討深度學習+SLAM的可行性和發展方向。
長期來講,深度學習有極大可能會去替代目前SLAM技術中的某些模塊,但徹底端到端取代SLAM可能性不大。短期來講(三到五年),深度學習不會對傳統SLAM技術產生很大沖擊。
下面結合具體工作談談這麼說的理由。目前深度學習+SLAM有幾個主要的研究方向:1)單目SLAM學習尺度/深度;2)相機重定位;3)前端提取特征和匹配4)端到端學習相機位姿;5)語義SLAM;
1. 單目SLAM學習尺度/深度 (DL的精度不好)
單目純視覺SLAM最大的問題是缺乏尺度信息,於是最直觀的思路就是引入深度學習來腦補圖像的尺度/深度信息。
代表工作其實有很多,但很大一部分是端到端架構,兩個網絡分別計算pose+depth直接出絕對軌跡,這類工作我放在後面端到端學習位姿部分中介紹,這裏僅例舉估計深度而不計算pose的工作。如TUM發表在CVPR17上的CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction,將LSD-SLAM裏的深度估計和圖像匹配都替換成基於CNN的方法,取得了較為魯棒的結果。

但個人認為用DL估算深度在原理上不是很站得住,DL擅長去做一些高層理解類的任務如特征估計圖像匹配等,但深度估計太偏計算幾何了。人眼去看一張圖像也只能獲得大概定性的深度遠近,而無法得到精確定量的深度大小,這種任務對於DL來說實在有些強人所難了。而傳統的深度計算方法,不考慮誤差理論上是可以得到精確數學解的,深度學習無論如何也無法達到這樣的解析精度。
實際上,相關工作的精度確實不高,CNN-SLAM在室內每個像素的平均誤差約50cm,在室外則高達7米,相比傳統三角化計算深度在精度上有一定差距。但優勢在於魯棒性較強,傳統三角化所面臨的視差太大太小問題在DL這裏都不存在。
2. 相機重定位/閉環檢測 (效果有待評估)
相機重定位/閉環檢測通常需要對當前時刻各類傳感器的信息進行特征提取,並與之前得到的歷史數據進行搜索匹配,以便在跟丟後重新獲取一個初始位置/判斷是否到達了某個歷史位置。
這一過程與傳統的圖像匹配有一定相似性,是比較適合用深度學習去完成的一類任務。
代表工作如DL+SLAM的開山之作——劍橋的論文:ICCV15的PoseNet,使用GoogleNet去做6-dof相機位姿的回歸模型,並利用得到的pose進行重定位。
其結果在當時(15年)非常具有開創性,但其主要意義還是在於開創了一種新的思路,其實用性及精確度並不如傳統重定位方案來的可靠。
3. 前端提取特征和匹配 (應該有機會)
目前DL在圖像領域最成功的應用即是feature engineering,因此用於前端特征提取和匹配是一個比較合理的思路。
Magic Leap 17年放出的文章Toward Geometric Deep SLAM提出了一種基於CNN的提取特征點及匹配方法,包含兩個網絡,第一個用於提取二維特征點,第二個用於輸出二維特征點的單應矩陣。無需描述子,無需繁雜的圖像預處理,高速輕量,在單核CPU上可達30fps。但代碼未開源。
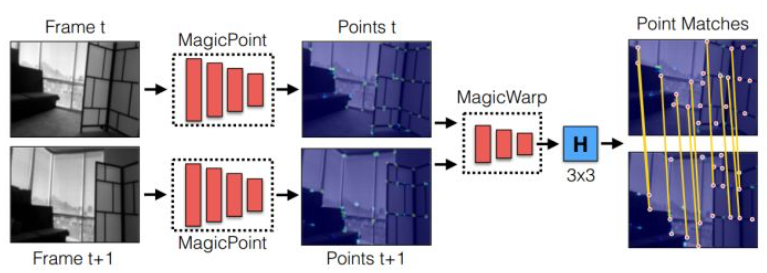
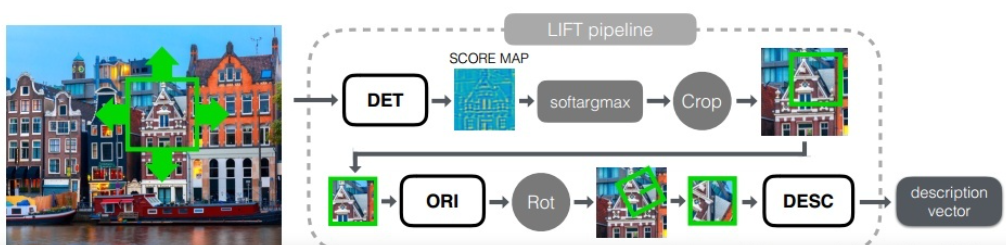
EPFL發表於ECCV16的LIFT: Learned Invariant Feature Transform提出了一種新型的深度網絡,實現了完整的特征處理pipeline:包括檢測,方向估計和特征描述。能提取出相比SIFT更加稠密的特征點,且給予了其端到端架構較好的解釋性。
從實驗結果看來在幾個數據集上的表現吊打目前所有傳統的及基於DL的特征方案(包括SIFT),但未給出運行時間數據,估計其速度應該比較堪憂。不過不考慮計算量已經做到了state-of-the-art。
DL用於特征提取及圖像匹配是一個比較有潛力的方向,因為傳統的特征提取、描述、匹配方案在數學上並沒有一個非常清晰完整的解釋,並且目前看來也很難用數學去進行清晰的描述:如SIFT、FAST各類特征點對圖像的理解僅局限於非常有限的點信息,光流跟蹤一直沒有一個非常完美的數學框架。這一塊去使用DL去進行high-level regression可能會取得意想不到的效果。同時,特征提取及描述一直是SLAM算法中的耗時大戶,花費大量的計算才能得到比較魯棒精確的結果,並且其中很多計算是不可避免難以優化的。那麽利用DL直接出特征會是一個值得一試的思路,畢竟目前DL的優化方法數不勝數。
4. 端到端學習相機位姿 (無可解釋性且汎化差)
端到端SLAM最大的優勢即“端到端”:完全舍去前端提點跟蹤 (tracking)、後端優化 (optimization) 求解的一系列過程,直接輸入圖像給出位姿(或者位姿+深度)。
近一兩年端到端SLAM的相關研究較多,代表性工作如下:
2016年印度理工的 DeepVO 是最早用DL去估計位姿的工作之一,采用了一種基於AlexNet的網絡,僅使用CNN輸入前後圖像給出旋轉角和平移的變化量。在同一場景下效果還ok,但換個場景效果慘不忍睹,幾乎不具有泛化性。
另一篇發表於ICRA17上的DeepVO(名字一樣,不同研究組的)在前一篇的網絡基礎上加進了串聯的RNN,即在CNN後面又串聯了LSTM,在網絡中引入了時間尺度的信息。因此效果要大大好於前一篇DeepVO,但依然不如傳統方法,並且泛化能力一般。
AAAI17的VINet: Visual-Inertial Odometry as a Sequence-to-Sequence Learning Problem使用圖像加IMU數據將VIO當做一個序列到序列的學習問題來處理。使用了一個CNN和兩個LSTM,在中間特征表示層面上融合視覺及IMU數據進行端到端訓練,對相機進行絕對位姿估計。其精度可以媲美state-of-the-art,但由於是絕對位姿估計,必須在相同的場景中訓練和測試,並沒有解決領域遷移(模型泛化)問題。
與之類似的還有出自同一個實驗室的CVPR17論文VidLoc。
Google CVPR17的SfM-Learner,利用光度一致性原理來估計每幀的depth和pose,其原理類似於直接法中優化光度誤差。僅用一段單目視頻就可以訓練兩個網絡,分別輸出pose和depth。在KITTI數據集上的效果優於不開閉環重定位的ORB-SLAM,但略遜於開了閉環重定位的ORB-SLAM。
用DL做端到端SLAM非常簡單粗暴,能夠繞開許多傳統SLAM框架中極為麻煩的步驟如外參標定、時間戳同步,同時避開前後端算法中許多棘手的問題。作為一種全新的思路具有一定的意義。
但同樣端到端SLAM的問題也非常明顯,和前面所說的深度估計類似,SLAM這樣一個包含很多幾何模型非常數學的問題,通過深度學習去端到端解決,在原理上是完全沒有依據的,而且也沒理由能得到高精度解。另一個很大的問題是模型的泛化性難以保證。目前的SLAM系統(視覺裏程計)通常會有一個非常覆雜的框架,從前端到後端每一步都有明確的目的,有完整的數學理論支撐,具有很強的解釋性。而用高度依賴數據的DL去粗暴地近似SLAM系統,對於某些數據集可能效果不錯,換個場景可能就無法跟蹤。
事實上,目前的端到端深度學習SLAM確實在精度上並不能和state-of-the-art的傳統方法媲美,同時在泛化性上表現較差。大部分工作無法直接用視頻進行訓練,訓練過程較為麻煩。
5. 語義 semantic SLAM (Good possibility)
至今為止,主流的 SLAM 方案多是基於處於像素層級的特征點,更具體地,它們往往只能用角點或邊緣 (SIFT/SURF/ORB/FAST) 來提取路標。與之不同的是,人類通過物體在圖像中的運動來推測相機的運動,而非特定像素點。
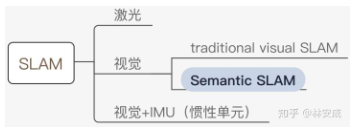
Semantic SLAM 是研究者試圖利用物體信息的方案,其在Deep Learning的推動下有了較大的發展,成為了相對獨立的分支,其在整個SLAM領域所處位置如下圖:
目前而言,所謂 Semantic 是將基於神經網絡的語義分割、目標檢測、實例分割等技術用於 SLAM 中,多用於特征點選取、相機位姿估計,更廣泛地說,端到端的圖像到位姿、從分割結果建標記點雲、場景識別、提取特征、做回環檢測等使用了神經網絡的方法都可稱為 Semantic SLAM。
前面提過的CNN-SLAM除了用CNN估計深度外,還用了CNN做圖像語義分割,然後將geometry和semantic融合起來,生成具有語義信息的地圖。
就是在 mapping 部分使用 semantic segmentation. 但是 tracking (real-time pose and refined pose) 部分仍然是傳統 SLAM.
2016年的工作Semi-Dense 3D Semantic Mapping from Monocular SLAM在LSD-SLAM的基礎上引入DL進行語義地圖構建,本質上是做了2D semantic segmentation,然後利用SLAM投影到三維空間中去。可在室內外環境工作。
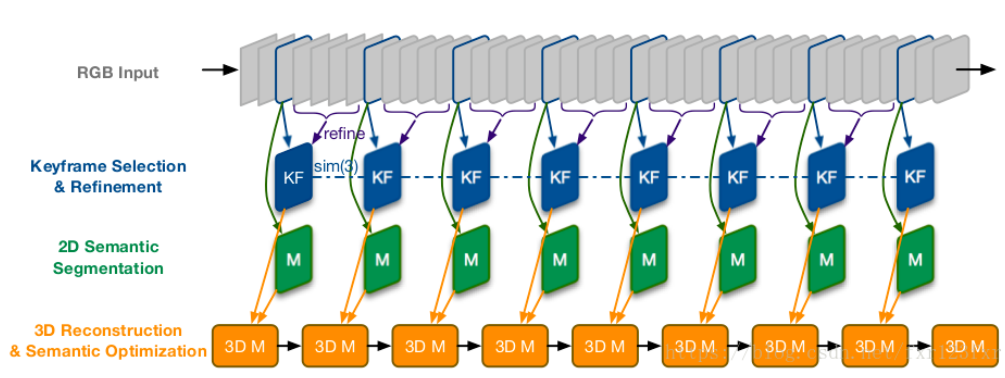
ICRA17 best paper的Probabilistic data association for semantic SLAM在ORB-SLAM2的基礎上引入DL來進行語義SLAM中的數據關聯,語義識別物體,並將目標檢測的結果作為SLAM前端的輸入,與傳統特征互補提高定位魯棒性。難點在於detection結果的data association最好能和定位聯合優化,即構建緊耦合優化,但前者是個離散問題。文章利用EM算法首次針對融合了語義信息的SLAM問題給出了求解思路。
就是在 tracking 部分使用 object detection.
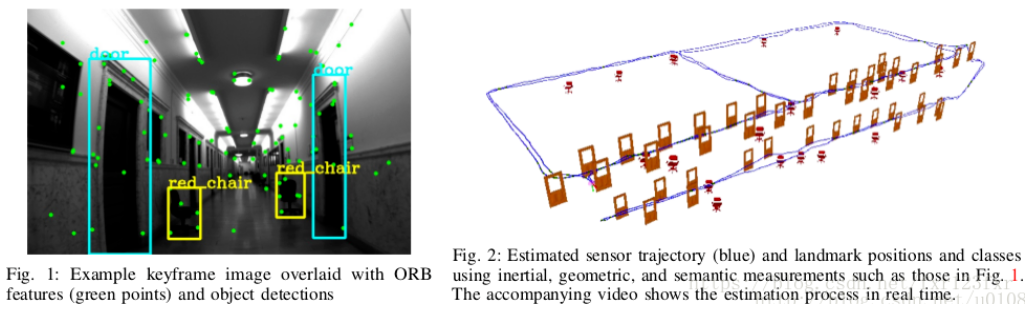
目前用DL做語義SLAM的相關工作大部分是利用DL+SLAM進行語義地圖構建,按照16年的大綜述還處於嬰兒期,很少有工作能反過來再將語義地圖用來服務SLAM的。而後者應當是語義SLAM的最終目標,即像人類一樣對環境進行高層語義理解,進而能解決動態背景、多相機協同等一系列目前SLAM中的難題。在這方面還有很長的路要走。
前面提到的這幾個應用方向排個序:特征提取及匹配 > 閉環/重定位/深度估計 > 端到端SLAM。
總的來講,從2015年第一篇DL+SLAM的工作PoseNet出現,至今還不滿三年的時間,DL+SLAM還是一個非常新有非常大探索空間的方向。其前景學界還沒有一個定論,但有一點毫無疑問,DL的大潮是不可阻擋的,未來的SLAM中一定會融入DL技術,但怎麽去融入,怎麽才能融入好,都還不是一時半會可以解決的問題。
Reference
fxr. 2018. “Deep Learning + SLAM小综述 - CSDN博客.” October 9, 2018.