Introduction
下一步想要用 Copilot 做幾件事
-
寫一個 data crawler 從 GFXbench 抓 GPU 相關資料
-
抓來的 html 用 BeautifulSoup parsing 需要的 content
-
BeatifulSoup parsed content 再用 regular expression 取出 structured data
-
Structured data 放入 database
-
database 可以 query and output formatted data
當然是用 Python 做爲 programming language
Step 1 & 2: Data Crawler and HTML Parsing
參考:[@weiyuanDataCrawler2017] and [@oxxoWebCrawler2021]
資料爬蟲是用在沒有以檔案或是 API 釋出資料集的情況下。這個時候就只能捲起袖子,自己想要的資料自己爬!
第一類比較簡單,是靜態網頁
動態網頁
傳統的 Web 應用允許使用者端填寫表單(form),當送出表單時就向網頁伺服器傳送一個請求。伺服器接收並處理傳來的表單,然後送回一個新的網頁,但這個做法浪費了許多頻寬,因為在前後兩個頁面中的大部分HTML碼往往是相同的。由於每次應用的溝通都需要向伺服器傳送請求,應用的回應時間依賴於伺服器的回應時間。這導致了使用者介面的回應比本機應用慢得多。
動態網頁有別於靜態網頁產生資料的方式。靜態網頁是透過每一次使用者請求,後端會產生一次網頁回傳,所以請求與回傳是一對一的,有些人把他們稱為同步。在動態網頁的話,是透過 Ajax 的技術,來完成非同步的資料傳輸。換句話說,就是在網頁上,任何時間點都可以發送請求給後端,後端只回傳資料,而不是回傳整個網頁。這樣一來,就不是一對一的關係,在處理資料上就會比較麻煩。
AJAX應用可以僅向伺服器傳送並取回必須的資料,並在客戶端採用JavaScript處理來自伺服器的回應。因為在伺服器和瀏覽器之間交換的資料大量減少,伺服器回應更快了。同時,很多的處理工作可以在發出請求的客戶端機器上完成,因此Web伺服器的負荷也減少了,如下圖。整的流程更複雜,不過後端還是可以用 beautifulsoup 處理。
所以我們換個角度,原本是模擬瀏覽器的動作,現在我們直接模擬人的操作。
這次使用 Selenium 4.x (注意和 reference 使用 3.x 語法不同) 實作 Data Crawler,Selenium 主要是拿來模擬瀏覽器行為的工具,而我們也利用的功能,模擬使用者瀏覽資料的過程取得資料,進一步利用 beautifulsoup 將原始資料進行爬梳。
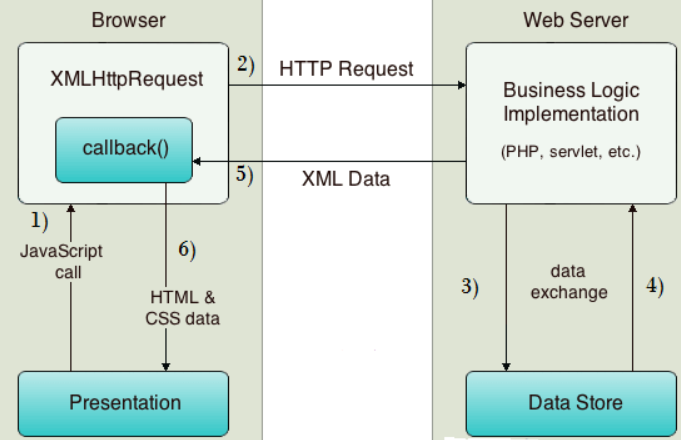
模擬 Request
先從 selenium website download browser 的 driver. 這裏選擇 Chrome driver. 測試碼如下。
- 先啓動 Chrome webdriver
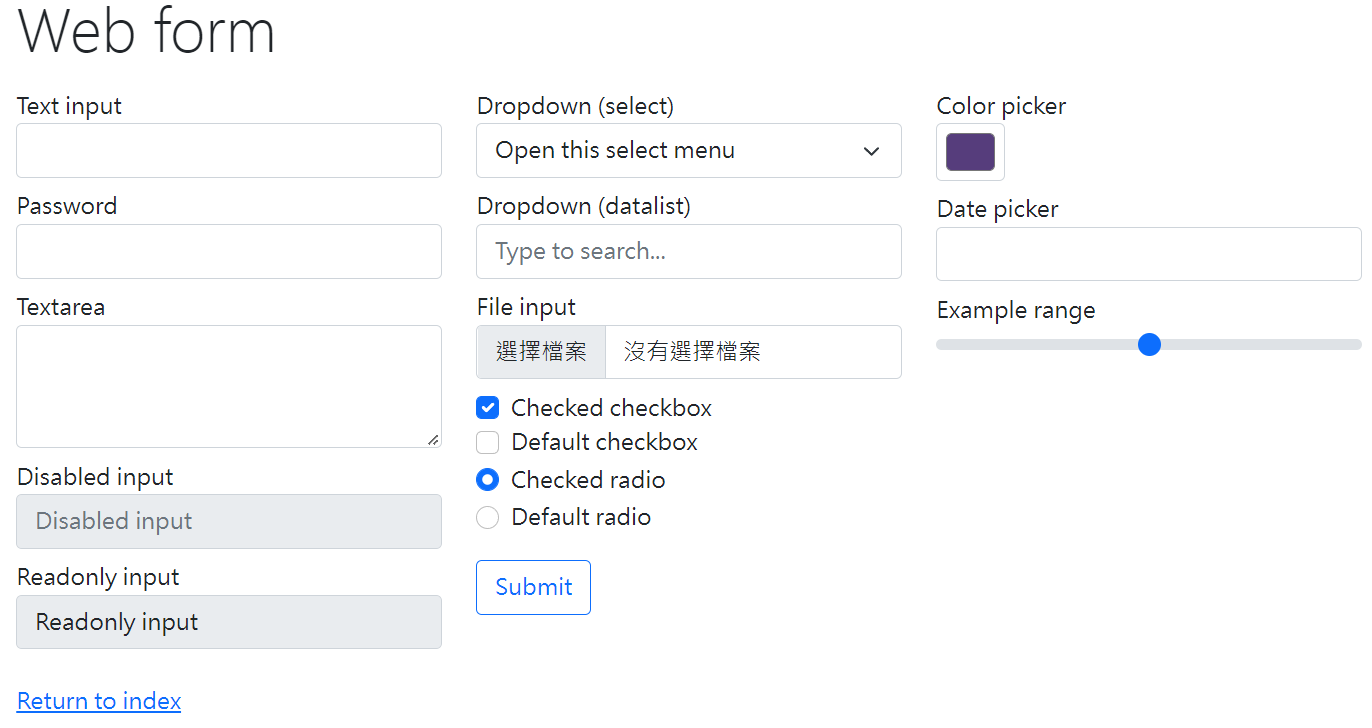
- 使用 get, request html from https://www.selenium.dev/selenium/web/web-form.html.
1 | |
https://www.selenium.dev/selenium/web/web-form.html 的網頁如下圖:
- 一般先 get title.
- 再來是 waiting strategy: “Synchronizing the code with the current state of the browser is one of the biggest challenges with Selenium, and doing it well is an advanced topic.” 不過我們基本就用 try-and-error 先設定 0.5 秒。
- **dynamic 就是和頁面互動: **
- 例如頁面上有 text box (e.g. Text input, Password, Textarea), menu (e.g. Dropdown, Color picker, Date picker), check box (e.g. checkbox, radio), button (submit), etc.
- 一般用 find_element(by=BY.NAME) 或是 BY.ID 找到對應的 “WebElement”。不過 NAME, ID 都要事先知道。
- 設定 WebElement (e.g. text, click). 一般最後是用 click() 送出 request.
- 注意此時不用再 request and get. 理論上 webpage 會自動 update.
Selenium4 新特性
Selenium4 至少需要 Python 3.7 或更高版本。 Python 3.6 (含) 之前的版本只能 install selenium3
Selenium 3 & 4 find_element 的比較
最常用的是 by_name, by_css_selector, by_id (Selenium 3), or By.NAME, By.CSS_SELECTOR, By.ID.
Selenium 3:
1 | |
Selenium 4:
1 | |
如果是多個 elements, 使用 find_elements instead of find_element.
Selenium 4: executable_path 更新成 service (minor)
Selenium 3:
1 | |
Selenium 4:
1 | |
如果是多個 elements, 使用 find_elements instead of find_element.
How about ui select?
driver.close or driver.quit
- > driver.close() command will only close the browser window which is in focus, out of all the windows opened
- > If the current focus is on the main/defect window, driver.close() will close the main/default window
- > If you have switched to a popup window or new tab window from the main/default window, driver.close() will close the current focused child window
- > driver.quit() command will close all the browser windows which are opened irrespective of their count (including the default and child windows)
How to pass the final html?
html = driver.page_source
GFXBench Dynamics Crawler
[@tutorialspointHowSelect2021] : tutorial on dropdown menu, can be used for GFXBench test options selection.