Source
-
ShakespeareGPT https://www.kaggle.com/code/shreydan/shakespearegpt
-
(56) Let’s build GPT: from scratch, in code, spelled out. - YouTube
Takeaway
Karpathy 有幾個 key concept 非常好!
- LLM weights 基本是 information (lossy) compression, 從 entropy/information 的角度 make sense.
- Attention 是 token to token communication, FFC/MLP 是每個 token 内部的 computation.
Dataset
莎士比亞的文章。總共約 10,000 words? or characters.
Tokenizer
- character level encoder: codebook 65
- BPE (byte-pair encoder)
- GPT2-3: codebook 50541?
- Tiktoken (OpenAI)
基本是 trade-off of the codebook vs. the token length!
Batch Training
- context length: block size
- variable context: (1, 1), (2, 1), (3, 1), …. (block_size, 1)
Language Model
Bigram Lanuage Model
-
Simplest embedding model (vocab_size x vocab_size: 65x65)
-
Traing (forward and backward) and generate
關鍵是 next token prediction from T token to T+1 token
1 | |
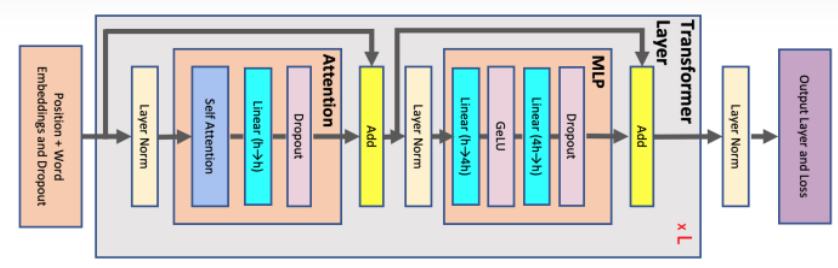
Transformer Model
第一個 transformer example: 210K parameters
第二個 transformer example: 888K parameters
第三個 transformer example: 11.5K parameters