AI 演算法趨勢:利用規模理論,結構越少的 AI 越通用
Less “Structure” Gets More General AI, but Scale Matters
規模理論:包括模型大小和計算規模
就是大力出奇蹟,應該不用特別解釋。
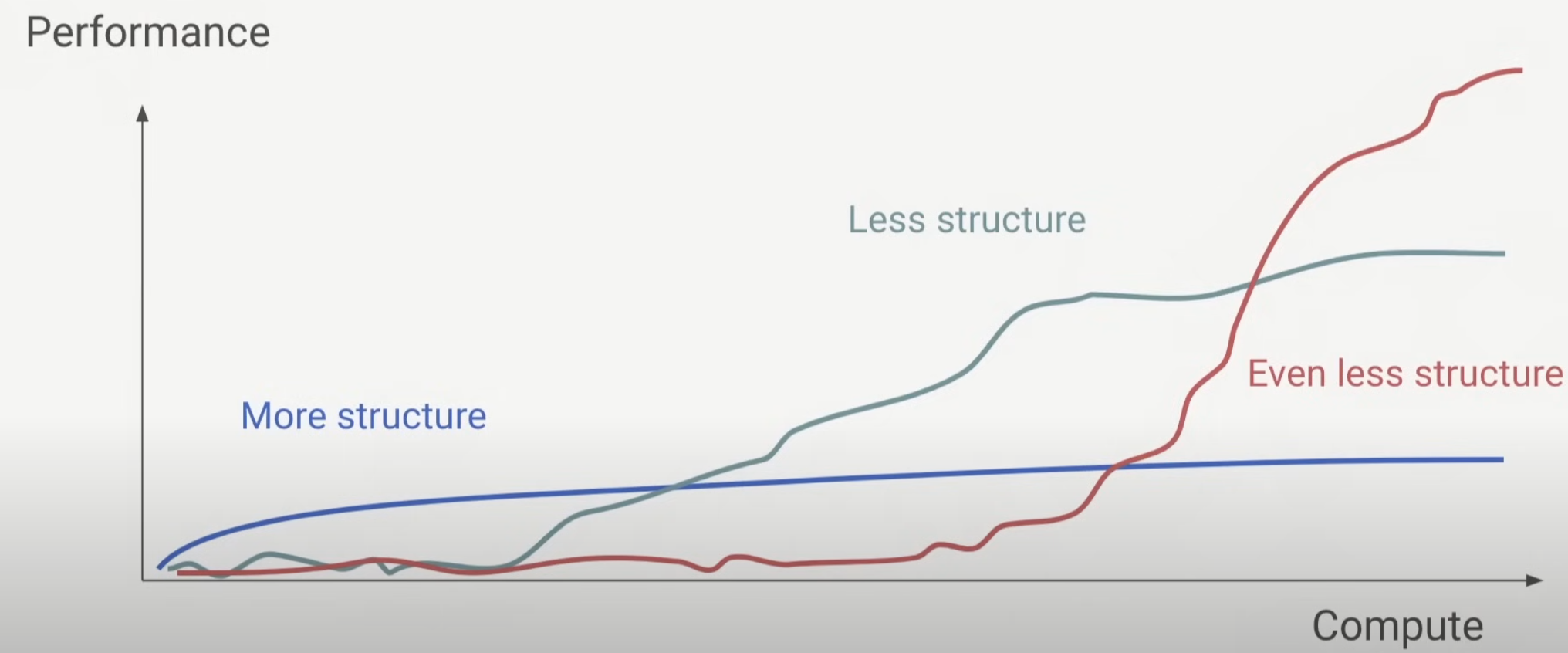
結構 - 少即是多?
結構有用嗎?是的,但這是一把雙刃劍。當模型和計算規模不足時,結構有助於提高性能。然而,隨著規模的增大,結構也會成為限制。這有點像「寄居蟹」的殼。殼最初有利於寄居蟹的成長,但當寄居蟹長大後需要更大的殼時,殼就成為了障礙。
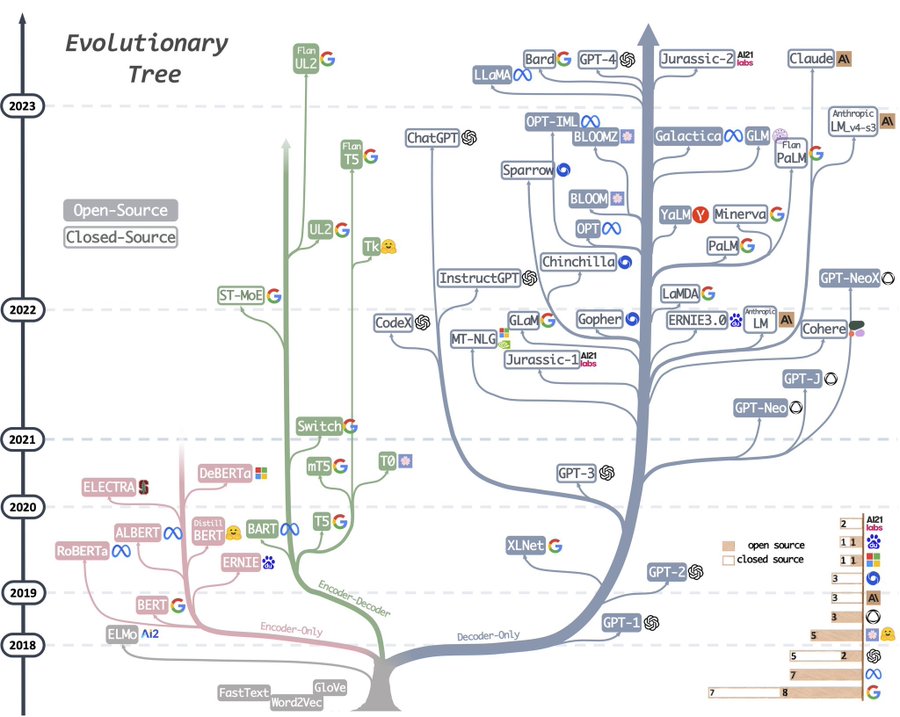
我們以 transformer 結構為例,包括原始的編碼器-解碼器、僅編碼器 (encoder-only) 和僅解碼器 (decoder-only) 的結構,或「殼」。
僅編碼器結構 (Encoder-only)
BERT 採用僅編碼器結構,在 2018 年實現了出色的文本摘要性能(多變少)如上圖左邊的粉紅分支。BERT 的模型大小比原始的 transformer 論文大,基礎版本有 1.1 億 (110M) 個參數。
- BERT 的優點: 僅編碼器結構對文本摘要非常有效。BERT 的雙向注意力顯著提高了摘要性能,特別是對於長輸入和短輸出。
- BERT 的限制: 僅編碼器結構無法用於文本生成,BERT 的雙向注意力隨著模型規模的增大和輸出長度的增加,其優勢會減少。
編碼器-解碼器結構 (Encoder-Decoder)
T5/Flan-T5 採用編碼器-解碼器結構,在 2019 年實現了出色的語言翻譯性能(多變多)如上圖中間的綠色分支。T5 的模型大小各異,最大的版本有 110 億 (11B) 個參數。
- 編碼器-解碼器的優點: 當輸入和輸出有明顯區別(例如不同語言或模態)時,該結構非常有效。它使用自注意力和交叉注意力來捕捉語言內部和跨語言或模態的關係。 T5 目前也用於 Stable Diffusion 3 文到圖的交叉注意力。
- 編碼器-解碼器的限制: 雖然在較小規模時很有用,但隨著模型規模的增大,這種方法會成為限制。交叉注意力將信息從編碼器的最後一層傳遞到所有解碼器層,隨著變壓器層數的增加,它會成為瓶頸。
僅解碼器結構 (Decoder-Only)
GPT 和大多數其他現代模型採用僅解碼器結構,由於限制較少且利用規模理論達到最佳性能(少變多,多變多)如上圖右邊的灰色分支。這種結構目前占主導地位。特別是 GPT-3,於 2020 年發布,模型大小超過 1750 億 (175B) 個參數。
- 優點: 僅解碼器結構將自注意力和交叉注意力合併為一種類型的自注意力,簡化了架構。
- 規模理論: 通過擴大模型大小和計算能力,僅解碼器結構在沒有更多結構限制的情況下實現了最先進的性能。
總之,雖然像僅編碼器和編碼器-解碼器這樣的結構在較小規模時各有優點,但隨著模型和計算規模的增加,限制較少的僅解碼器結構脫穎而出,證明在利用規模理論時,結構越少確實越多。
AI 演算法結構比較
| 結構 | 代表模型 | 發布年份 | 模型大小 | 優點 | 限制 |
|---|---|---|---|---|---|
| 僅編碼器結構 | BERT | 2017 | 基礎版本:1.1 億個參數 | - 適合文本摘要 (多變少) - 雙向注意力顯著提高長輸入短輸出的摘要性能 |
- 無法用於文本生成 - 隨著規模增大和輸出變長,雙向注意力優勢消失 |
| 編碼器-解碼器結構 | Flan-T5 | 2019 | 最大版本:110 億個參數 | - 適合語言翻譯 (多變多) - 使用自注意力和交叉注意力捕捉語言內部和跨語言的關係 |
- 交叉注意力會成為信息瓶頸 - 隨著規模增大,結構成為限制 |
| 僅解碼器結構 | GPT-3 | 2020 | 超過 1750 億個參數 | - 限制少 (多/少變多/少) - 自注意力結構簡單易行 - 用規模理論達到最佳性能 |
- 訓練和推理成本高 - 需要大量數據和計算資源 |
總結來看,當模型和計算規模不足時,結構確實有助於性能提升。然而,隨著規模的增大,過多的結構會成為限制。使用擴展法則並減少結構限制,可以在更大規模下實現更好的性能。
Next
Experimentalist (frequencist) to Baysianist
Bayes formula : … The history of Bayes
Appendix
AI Algorithm Trend
Less “Structure” Gets More General AI, but Scale Matters
Structure - Less is More?
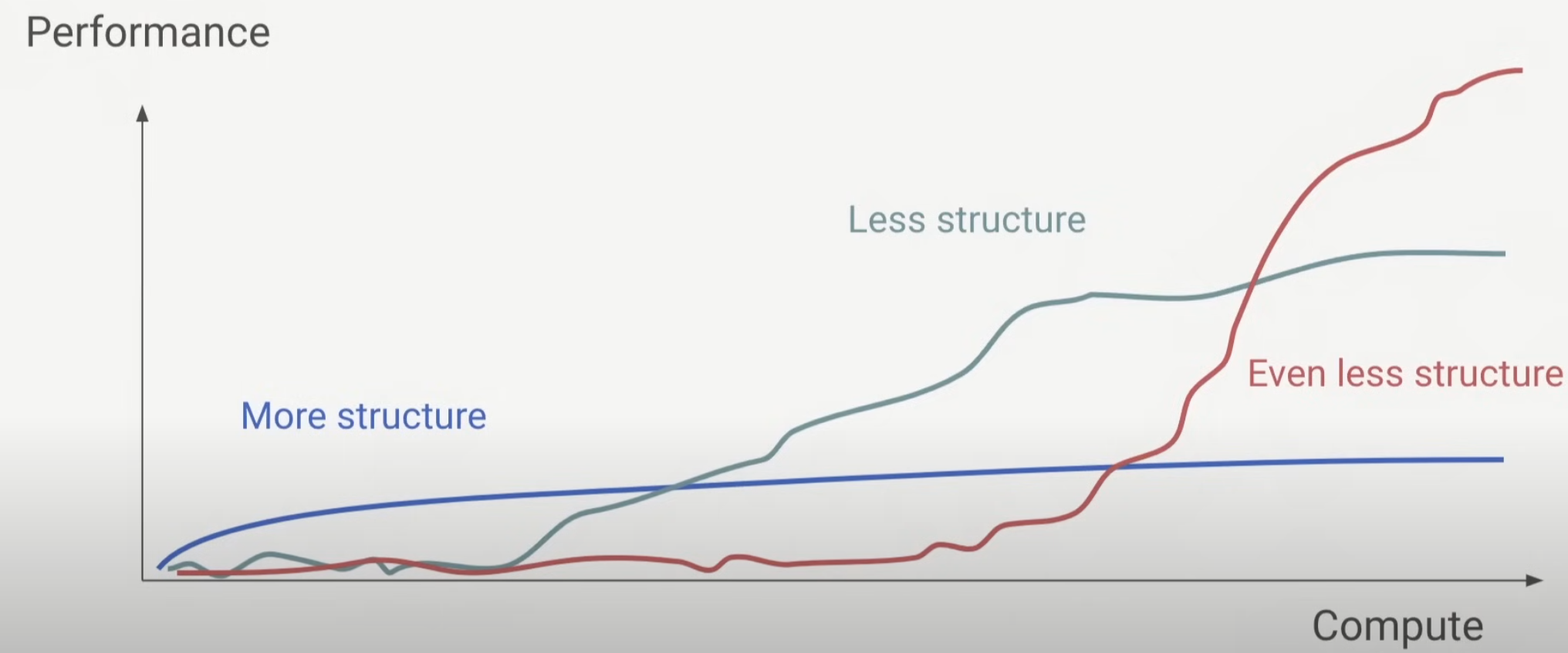
Is structure useful? Yes, but it’s a double-edged sword. Structure helps improve performance when the model and compute scales are not sufficient. However, it also becomes a constraint as the scale grows. It is akin to the shell of a “hermit crab.” The shell benefits the crab’s growth initially but becomes an obstacle once the crab outgrows it and needs a larger shell.
We’ll use the transformer structure as an example, including the original encoder-decoder, encoder-only, and decoder-only structures, or “shells.”
Encoder-Only Structure
Used by BERT, the encoder-only structure achieved good performance for summarization in 2017. The model size of BERT is larger than the original transformer paper, with the base version having 110 million parameters.
- BERT’s Strengths: The encoder-only structure is effective for text summarization. BERT’s bi-directional attention improves performance significantly for summarization, especially for long inputs and short outputs.
- BERT’s Limitations: This structure cannot be used for text generation, and its benefits diminish as the model scale grows and the output length becomes longer.
Encoder-Decoder Structure
Used by Flan-T5, this structure achieved good performance for language translation in 2019. The model size of T5 varies, with the largest version having 11 billion parameters.
- Encoder-Decoder’s Strengths: This structure is effective when the input and output are distinct, like different languages. It employs self-attention and cross-attention to capture relationships within and across languages.
- Encoder-Decoder’s Limitations: While useful at smaller scales, this method becomes a constraint as the model scale grows. The cross-attention, which passes information from the encoder’s last layer to all decoder layers, becomes a bottleneck as the number of transformer layers increases.
Decoder-Only Structure
Used by GPT and most other modern models, the decoder-only structure dominates currently due to having fewer constraints while leveraging the scaling law for optimal performance.
- Strengths: The decoder-only structure merges self-attention and cross-attention into one type of self-attention, simplifying the architecture.
- Scaling Law: By scaling up model size and computational power, the decoder-only structure achieves state-of-the-art performance without the limitations imposed by more structured architectures.
In summary, while structured architectures like encoder-only and encoder-decoder have their merits at smaller scales, the less constrained decoder-only structure excels as model and compute scales increase, illustrating that less structure can indeed be more when leveraging the scaling law.