Source
- What is Retrieval Augmented Generation (RAG) https://www.youtube.com/watch?v=T-D1OfcDW1M
- GitHub - jxzhangjhu/Awesome-LLM-RAG: Awesome-LLM-RAG: a curated list of advanced retrieval augmented generation (RAG) in Large Language Models
- 2310.03025 (arxiv.org) : RAG vs. Long Context
![[Pasted image 20240811220657.png]]
長文本模型、微調與增強式生成技術的比較
長文本模型(Long-Context LLMs, > 128K, e.g. 1M)
優點:
- 直接處理長輸入: 能够直接處理較長的提示或文件,无需外部擷取。
- 潛在的推理能力提升: 可能捕捉到輸入中的更多上下文和關係,進一步提升理解能力。
- 減少對外部知識源的依賴: 在某些情況下,可以直接處理輸入信息,不需要額外的擷取。
缺點:
- 高計算成本: 相較於傳統的 LLM,訓練和推理的計算成本更高。
- 上下文長度限制: 雖然比傳統 LLM 更長,但仍存在可處理輸入長度的限制。
- 數據效率: 可能需要更多的訓練數據來達到最佳性能。
微調(Fine-Tuning)
優點:
- 適應特定任務: 可以針對特定任務或領域進行訓練,以提升性能。
- 性能提升: 通常比直接使用預訓練模型效果更好。
- 潛在的小模型優化: 有時可以在較小的模型上進行微調,降低計算需求。
缺點:
- 需要標註數據: 微調通常需要帶有標籤的數據集。
- 過擬合風險: 如果訓練數據不夠多樣化,可能導致過擬合。
- 計算成本: 雖然比從頭訓練模型低,但仍需要一定的計算資源。
增強式生成(RAG)
優點:
- 接入外部知識: 可以利用大量的外部信息。
- 提升準確度和相關性: 通過結合外部知識,可以生成更準確、相關的回應。
- 靈活性: 可以與不同類型的 LLM 和知識源結合使用。
缺點:
- 需要知識庫: 建立和維護高品質的知識庫可能具有挑戰性。
- 擷取效率: 從知識庫中高效擷取相關信息至關重要。
- 潛在幻覺問題: 如果擷取到的信息不準確或誤導,生成的輸出也可能不正確。
選擇最佳方法
最佳方法取決於具體的應用場景、可用資源和期望的性能。
- 長文本模型 適合直接處理長輸入的任務,例如摘要長篇文件或生成代碼。
- 微調 適用於有大量標註數據且明確性能提升目標的任務。
- 增強式生成 在需要接入外部知識且 LLM 上下文長度有限的情況下很有價值。
在許多情況下,可以結合使用這些技術來達到最佳效果。例如,RAG 系統可以使用長文本模型來處理增強後的輸入,以提升性能。
RAG vs. Long Context
先説結論:
- LLM-4K + RAG > LLM-16K w/o RAG (LLM: Llama2-70B and GPT-43B)
- Llama2-70B-32K + RAG > GPT-3.5-(175B)-16K > Llama2-70B-32K w/o RAG
Takeaway
| LLM only (cloud or edge) | Cloud+Edge LLM post arbitration |
Cloud+Edge LLM pre arbitration |
Cloud info+ edge LLM RAG |
Cloud info+ edge AutoGPT |
|
|---|---|---|---|---|---|
| Accuracy | 1. Based of pre-trained knowledge, could be out-of-date. 2. Hallucination without credible source |
1. Based of pre-trained knowledge, could be out-of-date. 2. Hallucination without credible source |
Worst. Edge LLM error + cloud LLM error |
High | Med-High |
| Cost | Edge:low; Cloud:high | High | Medium | Low | Med |
| Latency | Edge: fast; Cloud: slow | Fast | Fast | Slow? | Slow |
| Self-improve | You don’t know you don’t know. Ceiling: cloud LLM |
Yes, use cloud LLM fine-tune edge LLM |
Maybe | Yes | Maybe |
Source
-
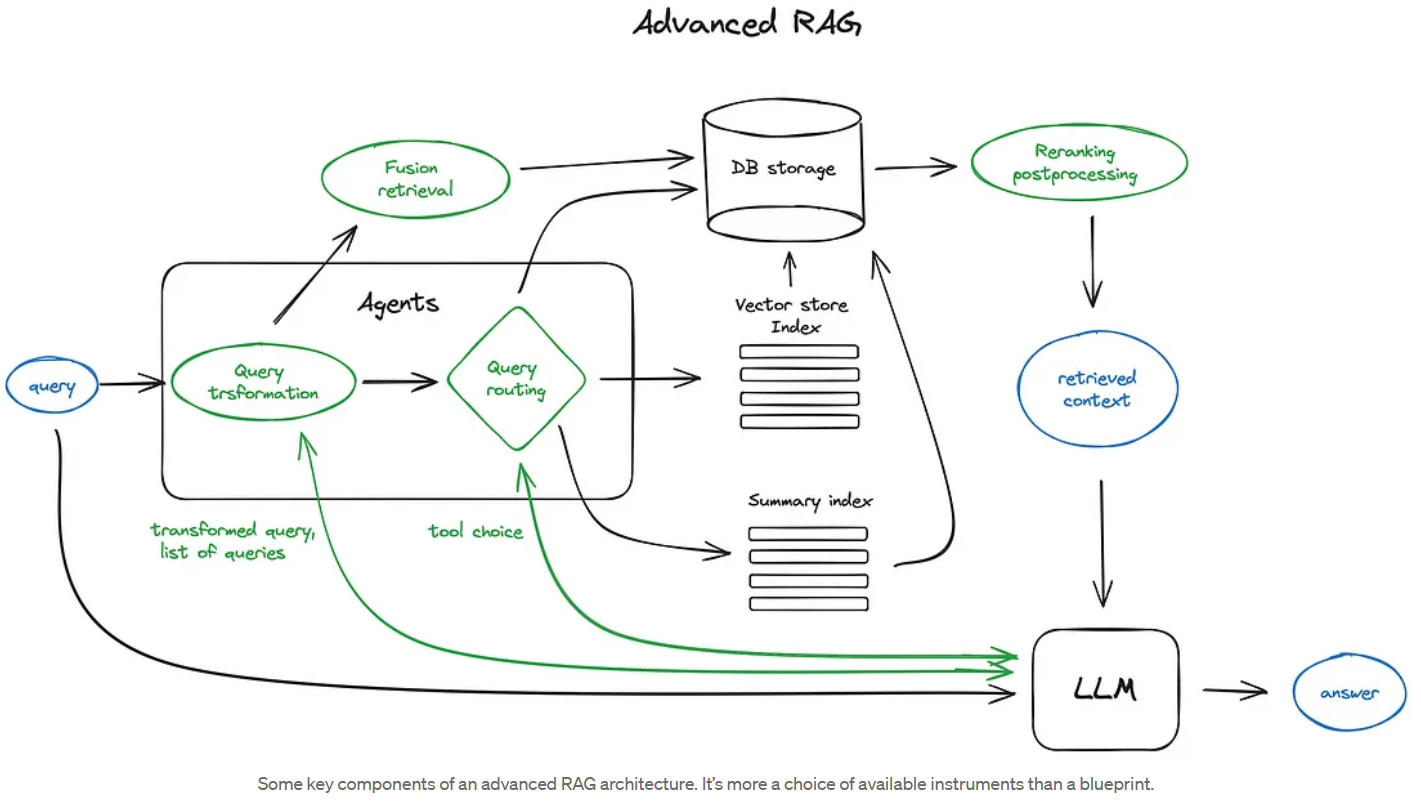
[Advanced RAG Techniques: an Illustrated Overview by IVAN ILIN Dec, 2023 Towards AI](https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6) - https://arxiv.org/html/2312.10997v5
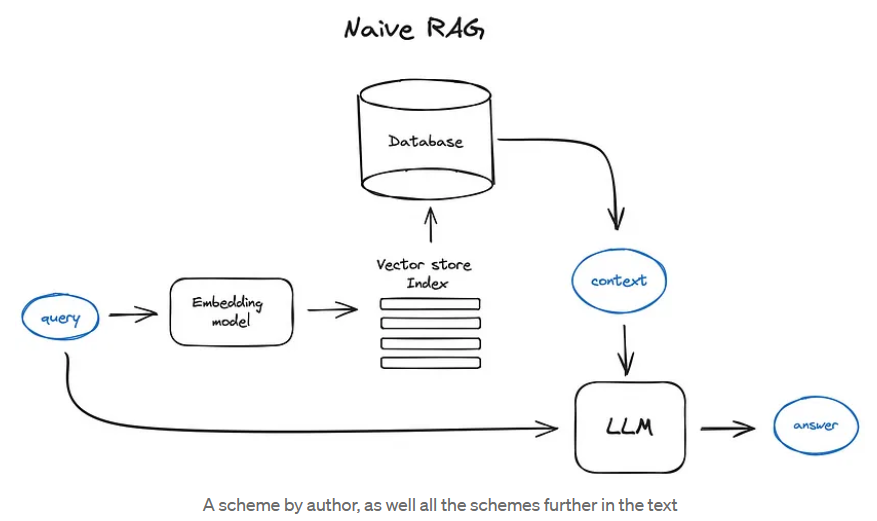
RAG
Vanilla RAG case in brief looks the following way: you split your texts into chunks, then you embed these chunks into vectors with some Transformer Encoder model, you put all those vectors into an index and finally you create a prompt for an LLM that tells the model to answers user’s query given the context we found on the search step. In the runtime we vectorise user’s query with the same Encoder model and then execute search of this query vector against the index, find the top-k results, retrieve the corresponding text chunks from our database and feed them into the LLM prompt as context.
The prompt can look like:
1 | |
Advanced RAG