介紹
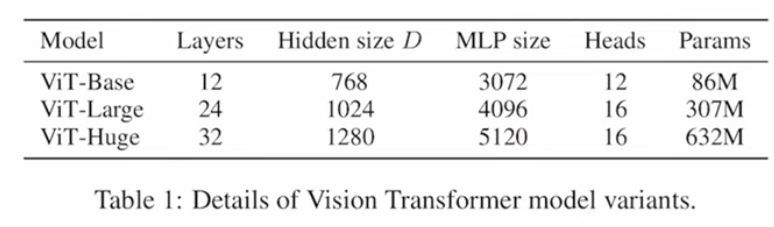
如下表 (2024Q3) LLM 趨勢:(1) 更大的模型尺寸(> trillion 參數),(2) 更長的上下文長度(> million tokens/標記),(3) 更低的推理成本(每百萬標記低於1美元),(4) 多模態和代理。
| 公司 | 尺寸 | 長度 | 模態,文本+ | MMLU | Lmsys | |
|---|---|---|---|---|---|---|
| Gemin1.5 | 谷歌 | 1.8T | 2M | 圖像 | 90 | 1, 5 |
| ChatGPT4 | OpenAI | 1.8T | 128K | 圖像/語音 | 86.4 | 2, 3 |
| Claude3.5 | Anthropic | NA | 200K | 圖像 | 86.8 | 4 |
| Ernie4 | 百度 | ~1T | ~2M | 圖像 | – | – |
| Llama3.1 | Meta | 405B | 128K | 圖像 | 88.6 | 6 |
| Large2 | Mistral | 123B | 128K | 圖像 | 84 | – |
| Owen2.5 | 阿裡巴巴 | 100B | > 1M | 圖像 | 82.8 | – |
為什麼需要更大的模型尺寸?
LLM 是一個數據吞噬怪物。根據縮放定律,LLM 吞食和處理大量數據,可以從語言中捕捉更多高維信息,以及來自語音、圖像或視頻的不同模態,從而產生更准確的預測和見解。
因此,最簡單的原因是在廣泛覆蓋中獲得更好的准確性。
LLM 基准
有兩種類型的基准,結構化問答類似於參加具有定義問題和正確答案的考試,例如 MMLU - 綜合知識問答,GSM8K - 數學。人類評估問答是基於主觀評估的隨機問題和答案,沒有定義的問題,例如 lmsys 競技場。
對於評估大型語言模型(LLM)的這兩種基准進行比較:
| 方面 | 結構化問答 | 人類評估問答 |
|---|---|---|
| 定義 | 具有定義問題和正確答案的基准。 | 基於模型輸出的主觀人類評估基准。 |
| 示例 | MMLU(多任務語言理解) ,GSM8K(數學問題)。 |
LMSYS 競技場,人類判斷任務。 |
| 問題類型 | 具體答案的固定問題。 | 由人類評估的開放式問題或任務。 |
| 評估方法 | 基於正確性的自動評分。 | 人類評分員評估質量、相關性和連貫性。 |
| 目標 | 測量特定能力(例如知識、推理)。 | 評估整體性能、可用性和用戶滿意度。 |
| 范圍 | ~60 個類別 | <5 個類別 |
這兩種基准對於了解LLM的優勢和劣勢都是有價值的,它們可以相互補充,提供對模型性能的全面評估。
MMLU(大規模多任務語言理解)基准
MMLU(大規模多任務語言理解)是一個旨在評估大型語言模型(LLM)在多種自然語言理解任務中的基准。
關鍵特征:
- 任務類別:MMLU 包含 57 個類別,涵蓋閱讀理解、數學和常識推理等多個領域。
- 數據集規模:該基准由超過 10,000 個問題組成,這些問題來源於學術考試、標准化測試和其他教育材料。
- 評估格式:問題以 多項選擇格式呈現,允許自動評分。
- 泛化能力:評估模型將知識泛化到新任務和未見任務的能力。
- 人類基准:提供與人類表現的比較,提供關於LLM與人類能力對比的見解。
MMLU 評分榜(2020-2024):愈大愈好
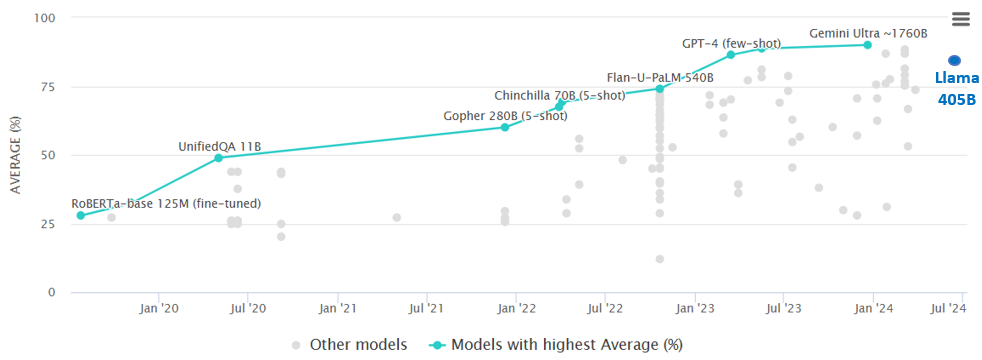
MMLU 基准(多任務語言理解)Papers With Code
MMLU 排行榜(2024年7月)
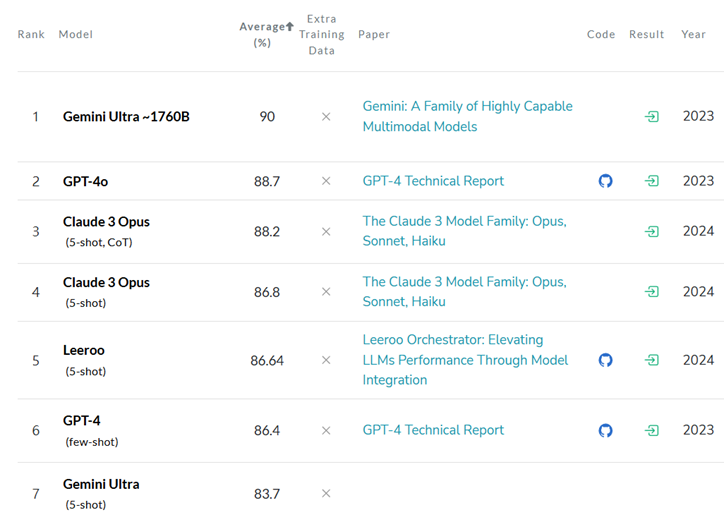
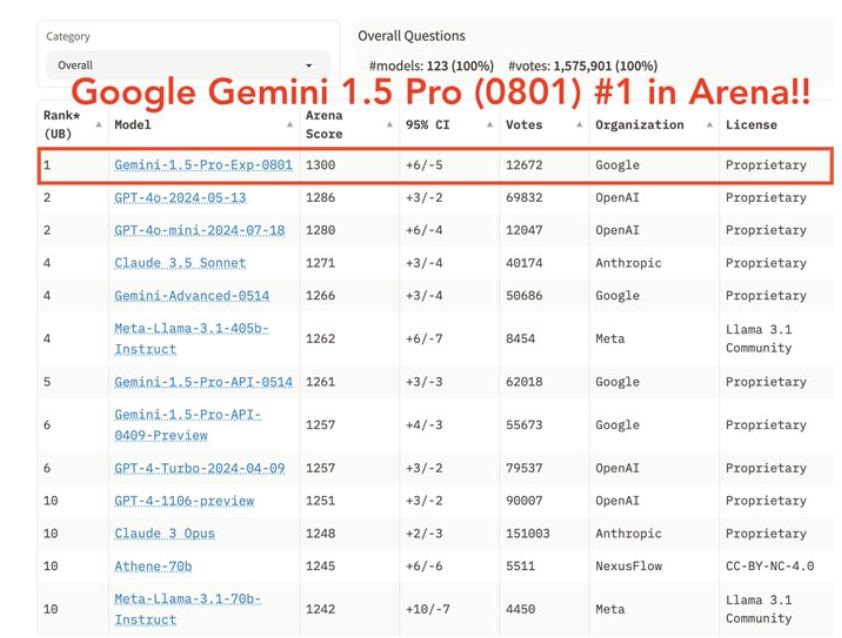
Lmsys Chat Arena 排行榜:愈大愈好
兩個前提:
- 評估(弱模型,如 GAN 中的判別器)比生成(強模型,生成器)更容易
- 相對評估比絕對評估更容易
注意事項:
- 使用 ELO(分布式)來獲取整體排名
- 雙盲評估:參與者和 LLM 都不知道誰在評估哪個模型。
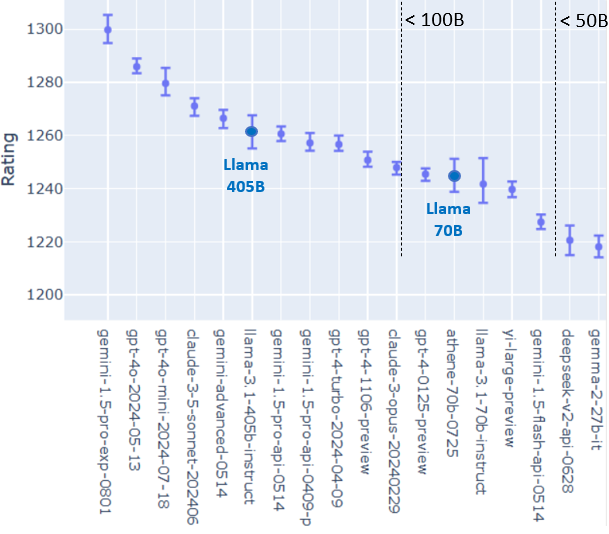
LMSys 聊天機器人競技場排行榜 - lmsys 的 Hugging Face 空間
為什麼 LLM 需要更長的上下文?
更長的上下文長度意味著 更長的(短期)記憶。這對於某些應用非常重要,並有助於減少 LLM 的幻覺。
- (應用)長文本摘要
- (應用)多輪對話
- (應用)多模態:圖像和視頻需要更長的上下文長度
- (減少幻覺)RAG - 檢索增強生成
注意:極長的上下文(例如 > 1M 標記)實際上可以實現完整的上下文數據庫嵌入,超越 RAG 的需求。然而,極長上下文的過高成本和延遲並不能很好地替代 RAG。RAG 迄今為止是將外部知識融入文本生成任務中最有效和實用的解決方案,以 (1) 減少 LLM 的幻覺;並且 (2) 提供來源的引用。
LLM 推理成本更低
雲 LLM 的推理成本顯著下降,目前入門模型的價格已低於每百萬標記 1 美元。
人工智能的 ABC:A. 算法,B. 大數據,C. 計算能力。對於使用變換器模型的 LLM,有一個簡單的公式:
計算能力 C ≈ α × 變換器模型的大小 A × 數據的大小 B
α 是一個常數。對於推理,α = 2;對於訓練,α = 6。
假設使用 H100(2000 TOPS)每小時 3 美元。我們可以計算訓練 LLM 的成本和 LLM 推理的成本。
推理成本
每 100B 模型大小,每 1M 推理標記 0.4 美元。
- 1T 模型: $0.4 \times 10 = $4.0 M-標記
- 400B 模型: $0.4 \times 4 = $1.6 M-標記
- 70B 模型: $0.4 \times 0.7 = $0.28 M-標記
LLM 成本分析
例如,Llama3.1-405B 使用的數據大小為 15T,相應的計算能力為 $6 \times 0.4T \times 15T = 36 \times 10^{24} = 3.6 \times 10^{25}$。
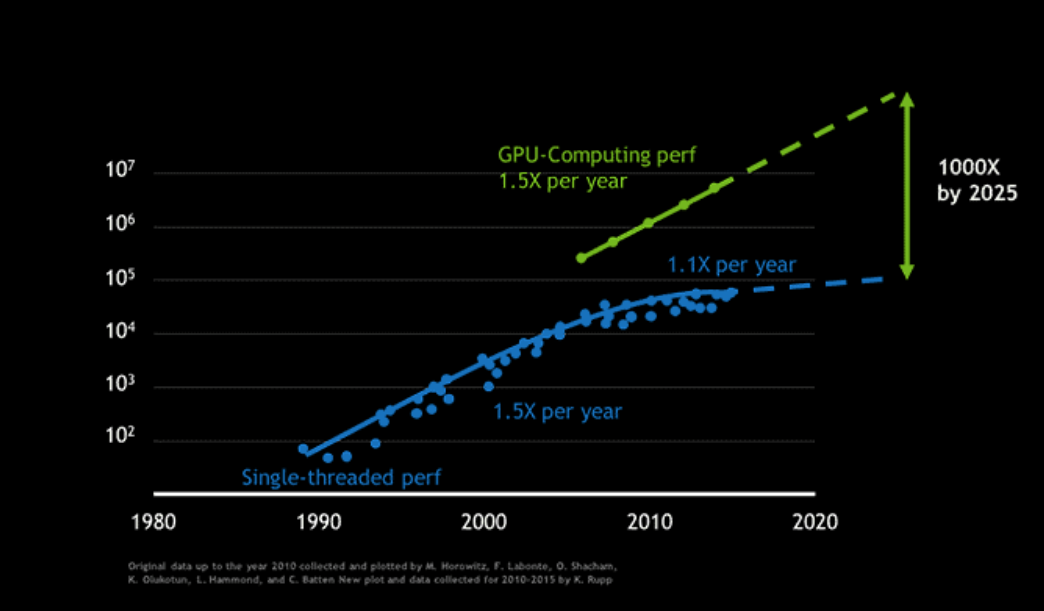
GPU 芯片的計算能力每兩年增加 2.25 倍,或每年增加 1.5 倍。
如何降低推理成本
這似乎與更大的模型尺寸相矛盾,但推理成本卻更低! 這裡有一些技巧:
- 訓練 3 種不同的模型尺寸:超大尺寸用於基准測試和教師模型。大尺寸和中等尺寸用於學生模型。學生模型是從教師模型中提煉出來的,以減少模型尺寸但保持相對接近的准確性。
訓練成本
每 100B 模型大小,每 1T 訓練標記 130 萬美元。
例如:Llama3-405B/70B/8B 使用 15T 標記: $1.3M \times 4.83 \times 15T/1T = $95M ~ $100M - 優化以提高 GPU 利用率。
- 批量大小
- 閃存注意力
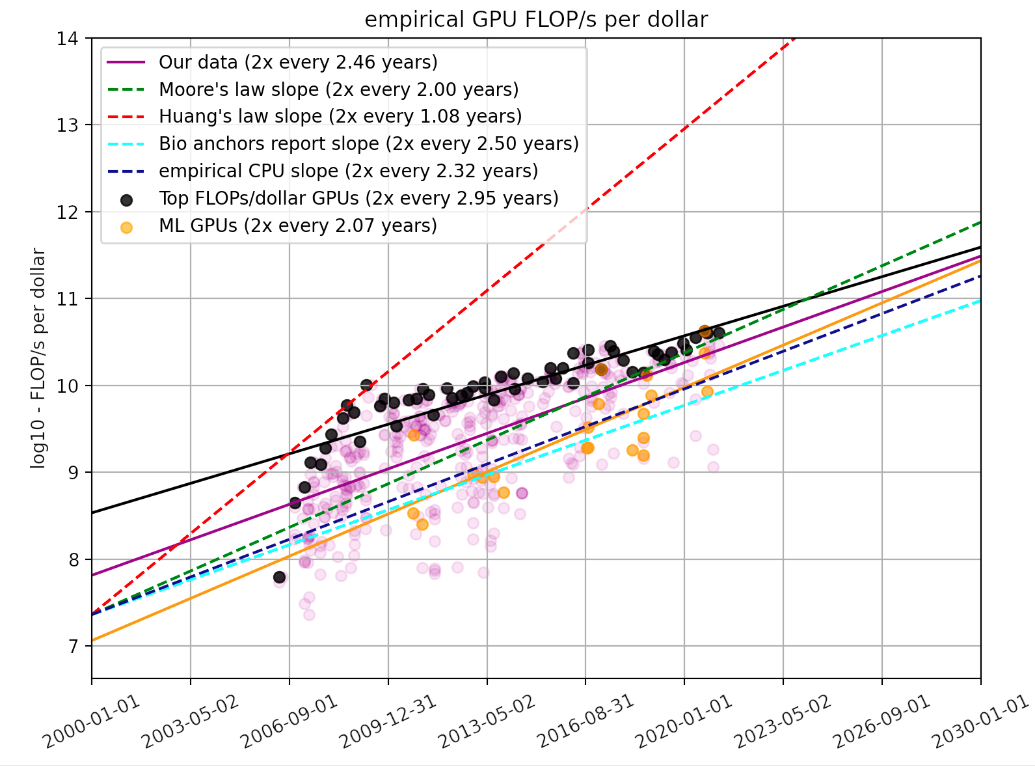
- 更好的硬件(TOPS / $):處理、封裝、架構和格式。
LLM 下一步:多模態和代理
LLM 風險:幻覺,對人類提示敏感。 多模態代理需要更大(因此更准確和通用)的 LLM,具備長上下文能力,以處理文本/語音/圖像/視頻信息的多輪交互。 多模態代理的應用:個人助手、企業代理(客戶支持、銷售與市場分析)、工業自動化(機器人)。
總結:
- 雲 LLM(更大、更長且更便宜)推動最佳的准確性和通用性,吸引廣泛用戶,高吞吐量,因此降低資本支出和運營支出的貨幣化成本。
- 設備上的 SLM(更小、更快且更個性化)專注於用戶體驗:低延遲的多媒體(語音/圖像/視頻)交互和個性化任務自動化。
- 設備上的 SLM + (私有)雲 LLM 的混合 AI 可能在成本和用戶體驗之間提供良好的補充和平衡。
Appendix B: English Version
Introduction
LLM Trends: (1) Larger model size (> trillion parameter), (2) Longer context lengths (> million tokens), (3) Lower inference costs (less than $1 per million tokens), (4) Multimodality and agents.
| Company | Size | Length | Modality, Text+ | MMLU | Lmsys | |
|---|---|---|---|---|---|---|
| Gemin1.5 | 1.8T | 2M | Image | 90 | 1, 5 | |
| ChatGPT4 | OpenAI | 1.8T | 128K | Image/Voice | 86.4 | 2, 3 |
| Claude3.5 | Anthropic | NA | 200K | Image | 86.8 | 4 |
| Ernie4 | Baidu | ~1T | ~2M | Image | – | – |
| Llama3.1 | Meta | 405B | 128K | Image | 88.6 | 6 |
| Large2 | Mistral | 123B | 128K | Image | 84 | – |
| Owen2.5 | Ali | 100B | > 1M | Image | 82.8 | – |
Why Bigger Model Size?
LLM is a data swallow monster. Based on the scaling law, LLM ingest and process vast amounts of data can capture more high dimensional information from lanuage as well as different modality from voice, image, or video, resulting in more accurate predictions and insights.
Therefore, the simplest reason is better accuracy in wide coverage.
LLM Benchmark
There are two types of benchmarks, structured Q&A is like taking exams with defined questions and correct answers, such as MMLU - comprehensive knowledge Q&A, GSM8K - math. Human evaluation Q&A is random question and answer based on subjective evaluation without defined questions, such as lmsys arena.
A comparison of the two types of benchmarks for evaluating large language models (LLMs):
| Aspect | Structured Q&A | Human Evaluation Q&A |
|---|---|---|
| Definition | Benchmarks with defined questions and correct answers. | Benchmarks based on subjective human evaluations of model outputs. |
| Examples | MMLU (Massive Multitask Language Understanding), GSM8K (math problems). | LMSYS Arena, human judgment tasks. |
| Question Type | Fixed questions with specific answers. | Open-ended questions or tasks evaluated by humans. |
| Evaluation Method | Automated scoring based on correctness. | Human raters assess quality, relevance, and coherence. |
| Objective | Measure specific capabilities (e.g., knowledge, reasoning). | Assess overall performance, usability, and user satisfaction. |
| Scope | ~60 categories | <5 categories |
Both types of benchmarks are valuable for understanding the strengths and weaknesses of LLMs, and they can complement each other in providing a comprehensive evaluation of model performance.
MMLU (Massive Multitask Lanuage Understanding) Benchmark
MMLU (Massive Multitask Language Understanding) is a benchmark designed to evaluate large language models (LLMs) across a diverse set of natural language understanding tasks.
Key Features:
- Task Categories: MMLU includes 57 categories spanning various domains, such as reading comprehension, mathematics, and common sense reasoning.
- Dataset Size: The benchmark consists of over 10,000 questions derived from academic exams, standardized tests, and other educational materials.
- Evaluation Format: Questions are presented in a multiple-choice format, allowing for automated scoring.
- Generalization Focus: Assesses models’ abilities to generalize knowledge to new and unseen tasks.
- Human Baseline: Provides a comparison against human performance, offering insights into how LLMs stack up against human capabilities.
MMLU Score Board (2020-2024): Bigger is Better
MMLU Benchmark (Multi-task Language Understanding) Papers With Code
MMLU Leaderboard (2024/7)
Lmsys Arena Leaderboard: Bigger is Better
Two premises:
- Evaluation (weak model, like discriminator in GAN) is easier than generation (strong model, generator)
- Relative evaluation is easier than absolute evaluation
Caveats:
- Use ELO (distributed) to get the overall ranking
- Double-blind evaluation: neither the participants nor the LLMs know who is evaluating which model.
LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys
Why LLM Needs Longer Context?
Longer context length implies longer (short-term) memory. This is important for some applications and helps to reduce LLM hallucination.
- (Application) Long text summary
- (Application) Multi-run conversation
- (Application) Multimodality: image and video require longer context length
- (Reduce hallucination) RAG - Retrieval-Augment-Generation
Note: Extremely long context (e.g. > 1M tokens) actually enables full in-context database embedding and surpasses the need for RAG. However, the excessive cost and delay of extremely long context are not a good replacement for RAG. RAG is by far the most efficient and practical solution for incorporating external knowledge into text generation tasks to (1) reduce LLM hallucination; and (2) provide the citation of the source.
LLM Inference is Cheaper
Cloud LLM inference cost drops significantgly, with prices now below $1 per million tokens for entry models.
ABCs of artificial intelligence: A. Algorithms, B. Big Data, and C. Computing Power. For LLMs using transformer models, there is a simple formula:
Computing Power, C ≈ α × Size of Transformer Model, A × Size of Data, B
α is a constant. For inference, α = 2; for training, α = 6.
Assuming using H100 (2000 TOPS) $3/hour. We can compute the cost of training a LLM and the cost of LLM inferencing.
Inferencing Cost
$0.4 per 100B model size, per 1M inference token.
- 1T model: $0.4 x 10 = $4.0 M-tokens
- 400B model: $0.4 x 4 = $1.6 M-tokens
- 70B model: $0.4 x 0.7 = $0.28 M-tokens
LLM Cost Analysis
For example, Llama3.1-405B uses a data size of 15T, and the corresponding computing power is $6 \times 0.4T \times 15T = 36 \times 10^{24} = 3.6 \times 10^{25}$.
The computing power of GPU chips increases by 2.25 times every two years, or by 1.5 times annually.
How to Reduce the Inference Cost
It seems contradict to the bigger model size, but lower inference cost! There are tricks:
- Train 3 different model size: super size is for benchmark and the teacher models. The big size and medium size are for student models. The student models are distilled from the teach models to reduce the model size but keep relative close accuracy.
Training Cost
$1.3M per 100B model size, per 1T training token.
Ex: Llama3-405B/70B/8B with 15T tokens: 1.3M x 4.83 x 15T/1T = $95M ~ $100M - Optimization to increase the GPU utilization rate.
- Batch size
- Flash attention
- Better HW (TOPS / $): process, package, architecture, and format.
Trends in GPU Price-Performance – Epoch AI
LLM Next: Multi-modality and Agent
LLM risk: hallucination, sensitive to human prompt. Multimodal agent requires a bigger (therefore more accurate and general) LLM with long context capability to process text/voice/image/video information in multi-run interactions. Multimodal agent applications: personal assistant, enterprise agent (customer support, sales & marketing analysis), industrial automation (robots).
In summary
- Cloud LLM (bigger, longer, and cheaper) pushes best accuracy and generality, drive wide users, high throughput, and therefore low cost to monetize the capex and opex.
- On-device SLM (smaller, faster, and personal) focus on user experience: low latency multimedia (voice/image/video) interaction and personalized task automation.
- Hybrid AI of on-device SLM + (private) cloud LLM may offer a good complement and balance between cost and user experience.
Appendix A: LLM Attention Rationale
先看不好的方法 for NLP
-
NLP 的問題是 input text string 一般是變動的,例如:“Hello, world”, 或是 “This is a test of natural language processing!”
- Input 是 text string, 切成 tokens ($\le$512). 儘量塞 sentence 或是 0 padding. 每個 token 是 768-dim (feature) vector. 也就是 (input) token embedding 是一個 arbitrary width ($\le$ 512) 2D matrix X. 最終希望做完 attention 運算還是得到同樣的 shape.
- Token size 不是固定 ($\le 512$) 有很多 implications:
- Need to use layer norm instead of group norm! 因爲不同 sample 的長度不同。
- 另外在 transformer for Computer vision 例如 ViT 應用:token length = 224x224/16x16 + 1 (CLS token) = 197!
- 如果 input-output 是 inter-token 和 inter-feature 的 fully-connected network, 顯然不可行!
- 因為是一個 $(512\cdot 768)^2 = 154$ B weights,同時 computation 也要 154 T operation!
- Input 是變動的長度, 所以固定的 154B weights 無法得到不同 width 的結果。

- 如果 input-output 只作用或處理在 embedding dimension (i.e shared weight for all input tokens!), 例如 1-dimension convolution, kernel 就是 1x768, channel length = 768. 假設 input 是 3-channel (e.g. RGB or KQV), parameter = 3 x 768^2 = 2M parameters. 顯然也不夠力。同時 each token 都是獨立處理,缺乏 temporal information!
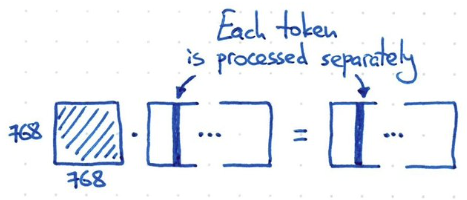
Catch
- 我們需要找一個方法介於 fully connected model and 1-d convolution network!!!
- Fully connect network size: (512x768)^2 = 154B
- 1-dimension network size: (768x768) < 1M
- 所以需要如同下面的方法!計算 $f(X) = X X^T X$. 假設 X 是 m x n -> (m x n) (n x m) (m x n) = m x n 得到和原來一樣的 shape!
- 此時 token 和 token 之間 interact, 但又不像 fully connected 這麼多 interaction!!! 這就是 attention 的原理!
- Rank = min(m, n)! 如果 width 很小,例如短句。或是 attention 範圍小。rank 就小。計算量就小,也避免 overfit!
- 問題是以下的方法,沒有任何 trainable parameter!!!!
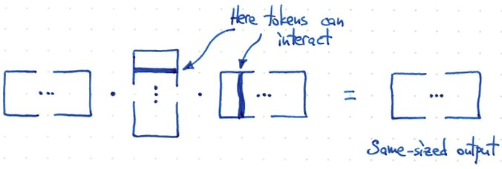
如何引入 Trainable Parameter?
- 如何做到?非常容易! 重組 input 引入 V (value) matrix. 引入 K, Q matrix and similarity/attention matrix!!
- 使用 K, Q 計算 similarity matrix (512x512),then softmax for attention matrix. V 通過 attention matrix 得到 output!
- 因為 attention matrix 的遠小於 768! 所以有類似 low rank 的功效。
- V, K, Q 的 dimension:
- V: 768x768, K: 768x768, Q: 768x768. Total: 3 x (768x768)
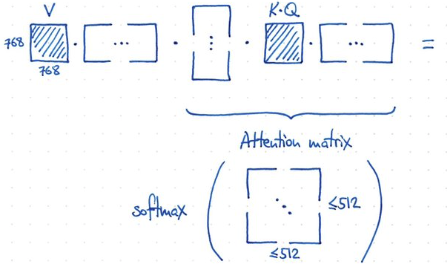
- 最後再加上一個 MLP layer. Hidden layer 的 dimension 是 4x768!, 所以 parameter = 768^2 x 4 x 2? = 5M parameters!

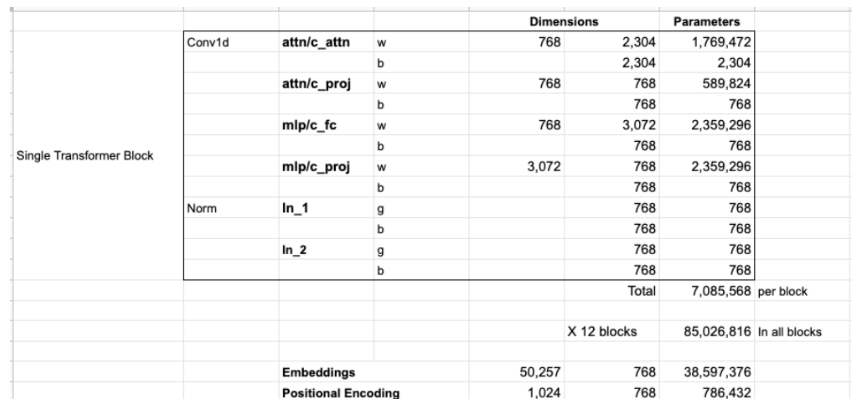
- 一個 transformer block 的 parameter = V,K,Q x 768^2 = 3 x 768^2 = 2M param + 5 M= 7.1 M parameters
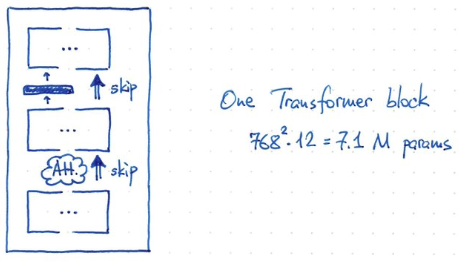
- BERT 有 12 blocks, giving ~ 85M parameters (再加上 25M for token embedding and position encoding, 30522 x 768 + 512 x 768 = 24M)
- BERT 的 inputs are sequences of 512 consecutive tokens!
- BERT 使用 uncased (not case sensitive) vocabulary size of 30522! GPT 是 case sensitive unicode of 50257.
- BERT 參數大約是 85M (12 block transformer) + 24M (embedding+position encode) = 110M

-
GPT2 : 以下是 Jay Alammar 對 GPT2 的參數估算,似乎一樣??? (2304 = 768x3 KQV, 3072=768x4 MLP)
- GPT2 的 inputs are sequences of 1024 consecutive tokens!
- GPT2 參數大約是 85M (12 block transformer) + 40M (embedding+position encode) = 125MB!!
- 爲什麽 token embedding 如此大, 38.6M? 不是因爲 token length 太長!而是支持 byte-level version of Byte Pair Encoding (BPE) for unicode characters and a vocabulary size of 50257.
-
-
Token length 的影響
-
BERT 的 max token length = 512; GPT2 的 max token length = 1024
-
注意每個 transformer block 的 7.1M parameters 數目和 token length 完全無關 (無論是 512 or 1024)!!!!
-
注意 token embedding 的參數大小和支持的字符集 (vocabulary) 有関 (BERT:32K or GPT:50K),和 token length 也無関!!!只有 position encode 的參數大小和 token length 有関 (512x768 or 1024x768) 不過對參數量的影響很小。
-
Token length 到底和什麽有関? transformer 内部計算的中間 result 會有 512 (or 1024)x768 matrix, 所以直接和計算量 (TOPS) 以及内存大小有關。但是和參數無關。、
-
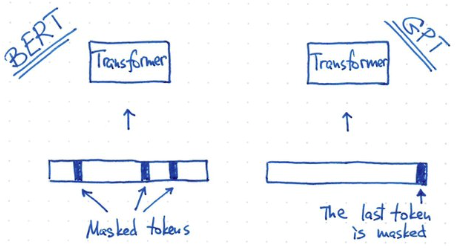
- 除了 token length 不同, BERT 和 GPT2 training 方式也不同: BERT 使用 masked token. GPT 使用 predicted token. 這也反應在他們的架構上: BERT 是 transformer encoder; GPT 是 transformer decoder.
-
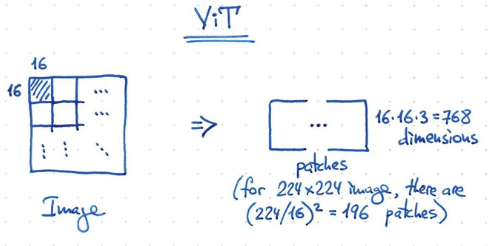
ViT 原理和 BERT 一樣, 都是 transformer encoder!
-
1-patch = 16x16x3 = 768 dimension. 224x224 image, 一共有 196 patches + 1 classification token = 197 tokens (<512 token).
-
ViT transformer 部分參數量和 BERT 一樣都是 85M。不過 embedding project 部分不同:
-
BERT embedding+position encoding: 30522 x 768 + 512 x 768 = 24M
-
ViT 是把 16x16(pixel)x3(RGB) = 768 重新 map 到 768 dimension, 所以只有 768x768+197x768=741120=0.75M. 所以 ViT 的全部參數基本就是 85+0.75~86M!
-
-
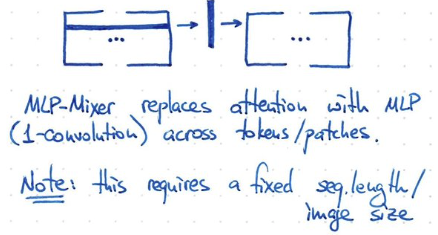
ViT 另一個簡化是使用 1-convolution 可以 work!! 也就是 shared weight!
- VIT 的大小: