![]()
1 | |
1 | |
The default version of TensorFlow in Colab will soon switch to TensorFlow 2.x.
We recommend you upgrade now
or ensure your notebook will continue to use TensorFlow 1.x via the %tensorflow_version 1.x magic:
more info.
1 | |
Generate a sin wave with no noise
First, I create a function that generates sin wave with/without noise. Using this function, I will generate a sin wave with no noise. As this sin wave is completely deterministic, I should be able to create a model that can do prefect prediction the next value of sin wave given the previous values of sin waves!
Here I generate period-10 sin wave, repeating itself 500 times, and plot the first few cycles.
1 | |
1 | |
Create a training and testing data. Here, the controversial “length of time series” parameter comes into play. For now, we set this parameter to 2.
1 | |
1 | |
Simple RNN model
As a deep learning model, I consider the simplest possible RNN model: RNN with a single hidden unit followed by fully connected layer with a single unit.
- The RNN layer contains 3 weights: 1 weight for input, 1 weight for hidden unit, 1 weight for bias
- The fully connected layer contains 2 weights: 1 weight for input (i.e., the output from the previous RNN layer), 1 weight for bias In total, there are only 5 weights in this model.
Let $x_t$ be the sin wave at time point $t$, then Formally, This simple model can be formulated in two lines as: \(\begin{aligned} h_{t}=\tanh \left(x_{t}^{T} w_{1 x}+h_{t-1}^{T} w_{1 h}+b_{1}\right) \\ x_{t+1}=h_{t}^{T} w_{2}+b_{2} \end{aligned}\)
Conventionally $h_0=0$. Notice that the length of time series is not involved in the definition of the RNN. The model should be able to “remember” the past history of $x_t$ through the hidden unit $h_t$.
batch_shape needs for BPTT.¶
- Every time when the model weights are updated, the BPTT uses only the randomly selected subset of the data.
- This means that the each batch is treated as independent.
- This batch_shape determines the size of this subset.
- Every batch starts will the initial hidden unit $h_0=0$.
- As we specify the length of the time series to be 2, our model only knows about the past 2 sin wave values to predict the next sin wave value.
- The practical limitation of the finite length of the time series defeats the theoretical beauty of RNN: the RNN here is not a model remembeing infinite past sequence!!!
Now, we define this model using Keras and show the model summary.
1 | |
1 | |
Now we train the model. The script was run without GPU.
1 | |
1 | |
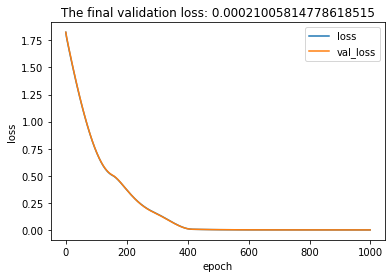
Plot of val_loss and loss.
The validation loss and loss are exactly the same because our training data is a sin wave with no noise. Both validation and training data contain identical 10-period sin waves (with different number of cycles). The final validation loss is less than 0.001.
1 | |
The plot of true and predicted sin waves look nearly identical
1 | |

What are the model weights?
The best way to understand the RNN model is to create a model from scratch. Let’s extract the weights and try to reproduce the predicted values from the model by hands. The model weights can be readily obtained from the model.layers.
1 | |
1 | |
What are the predicted values of hidden units?
Since we used Keras’s functional API to develop a model, we can easily see the output of each layer by compiling another model with outputs specified to be the layer of interest.
In order to use the .predict() function, we need to compile the model, which requires specifying loss and optimizer. You can choose any values of loss and optimizer here, as we do not actually optimize this loss function. The newly created model “rnn_model” shares the weights obtained by the previous model’s optimization. Therefore for the purpose of visualizing the hidden unit values with the current model result, we do not need to do additional optimizations.
1 | |
Plot shows that the predicted hidden unit is capturing the wave shape. Scaling and shifting of the predicted hidden unit yield the predicted sin wave.
1 | |

Obtain predicted sin wave at the next time point given the current sin wave by hand
We understand that how the predicted sin wave values can be obtained using the predicted hidden states from Keras. But how does the predicted hidden states generated from the original inputs i.e. the current sin wave? Here, stateful and stateless prediction comes into very important role. Following the definition of the RNN, we can write a script for RNNmodel as:
1 | |
Naturally, you can obtain the predicted sin waves $(x_1,x_2,…,x_t)$ by looping around RNNmodel as:
$x^∗{t+1},h{t+1} = RNNmodel (x_t,h_t)$
Here $x^∗_t$ indicates the estimated value of $x$ at time point $t$. As our model is not so complicated, we can readily implement this algorithm as:
1 | |
1 | |
In this formulation, x_stars[t] contains the prediction of sin wave at time point t just as df_test
1 | |
1 | |

You can see that the model prediction is not good in the first few time points and then stabilized. OK. My model seems to over estimates the values when sin wave is going down and underestimates when the sin wave is going up. However, there is one question: this model returns almost zero validation loss. The error seems a bit high. In fact the error from the prediction above is quite large. What is going on?
1 | |
1 | |
Let’s predict the sin wave using the existing predict function from Keras. Remind you that we prepare X_test when X_train was defined. X_test contains data as:
x1,x2x2,x3x3,x4…
1 | |
Notice that this predicted values are exactly the same as the ones calculated before.
1 | |
1 | |
As the prediction starts from x_3, add the 2 NaN into a predicted vector as placeholders. This is just to make sure that the length of y_test_from_keras is compatible with xtars.
1 | |
The plot shows that Keras’s predicted values are almost perfect and the validation loss is nearly zero. Clearly xstars are different from the Keras’s prediction. It seems that the predicted states from Keras and from by hand are also slightly different. Then question is, how does Keras predict the output?
1 | |
1 | |

Here, the technical details of the BPTT algorithm comes in, and the time series length parameter (i.e., batch_size[1]) takes very important role.
As the BPTT algorithm only passed back 2 steps, the model assumes that:
the hidden units are initialized to zero every 2 steps. the prediction of the next sin value (xt+1) is based on the hidden unit (ht) which is created by updating the hidden units twice in the past assuming that ht−1=0. x∗t,ht=RNNmodel(xt−1,0)xt+1,−=RNNmodel(xt,ht) Note that the intermediate predicted sin x∗t based on ht−1=0 should not be used as the predicted sin value. This is because the x∗t was not directly used to evaluate the loss function.
Finally, obtain the Keras’s predicted sin wave at the next time point given the current sin wave by hand.
1 | |
1 | |
1 | |
Now we understand how Keras is predicting the sin wave.
In fact, Keras has a way to return xstar as predicted values, using “stateful” flag. This stateful is a notorious parameter and many people seem to be very confused. But by now you can understand what this stateful flag is doing, at least during the prediction phase. When stateful = True, you can decide when to reset the states to 0 by yourself.
In order to predict in “stateful” mode, we need to re-define the model with stateful = True. When stateful is True, we need to specify the exact integer for batch_size. As we only have a single sin time series, we will set the batch_size to 1.
1 | |
1 | |
Assign the trained weights into the stateful model.
1 | |
Now we predict in stateful mode. Here it is very important to reset_state() before the prediction so that h0=0.
1 | |
1 | |
1 | |
Now we understand that xstars is the prediction result when stateful = True. We also understand that the prediction results are way better when stateful = False at least for this sin wave example.
However, the prediction with stateful = False brings to some awkwardness: what if our batch have a very long time series of length, say K? Do we always have to go back all the K time steps, set ht−K=0 and then feed forward K steps in order to predict at the time point t? This may be computationally intense.