Source
- 【手撕LLM-KVCache】顯存刺客的前世今生–文末含代碼 - 知乎 (zhihu.com)
- 大模型推理性能優化之KV Cache解讀 - 知乎 (zhihu.com)
- The KV Cache: Memory Usage in Transformers https://www.youtube.com/watch?v=80bIUggRJf4&ab_channel=EfficientNLP
- [LLM]KV cache詳解 圖示,顯存,計算量分析,代碼 - 知乎 (zhihu.com)
KV Cache 原理
Without KV Cache: X: input[token_len, D:embed] Wq, Wk, Wv: [D:embed, D:embed] Q, K, V: [token_len, D:embed]
With KV Cache:
Attention layer: 第一次是 pre-fill phase, 和 without KV Cache 一樣。儲存 Cache_K and Cache_V. 接下來每次都只有一個 input token (from previous output), 和 KV caches 一起產生新的一個 output token. X: input[1, D:embed] Wq, Wk, Wv: [D:embed, D:embed] Q, K, V: [1, D:embed], K+Cache_K, V+Cache_V: [K+1, D:embed] softmax(Q . K+Cache_K) (V+Cache_V): [1, D] [D, K+1] [K+1, D] = [1, D]
FF layer: 和 KV cache 無關。
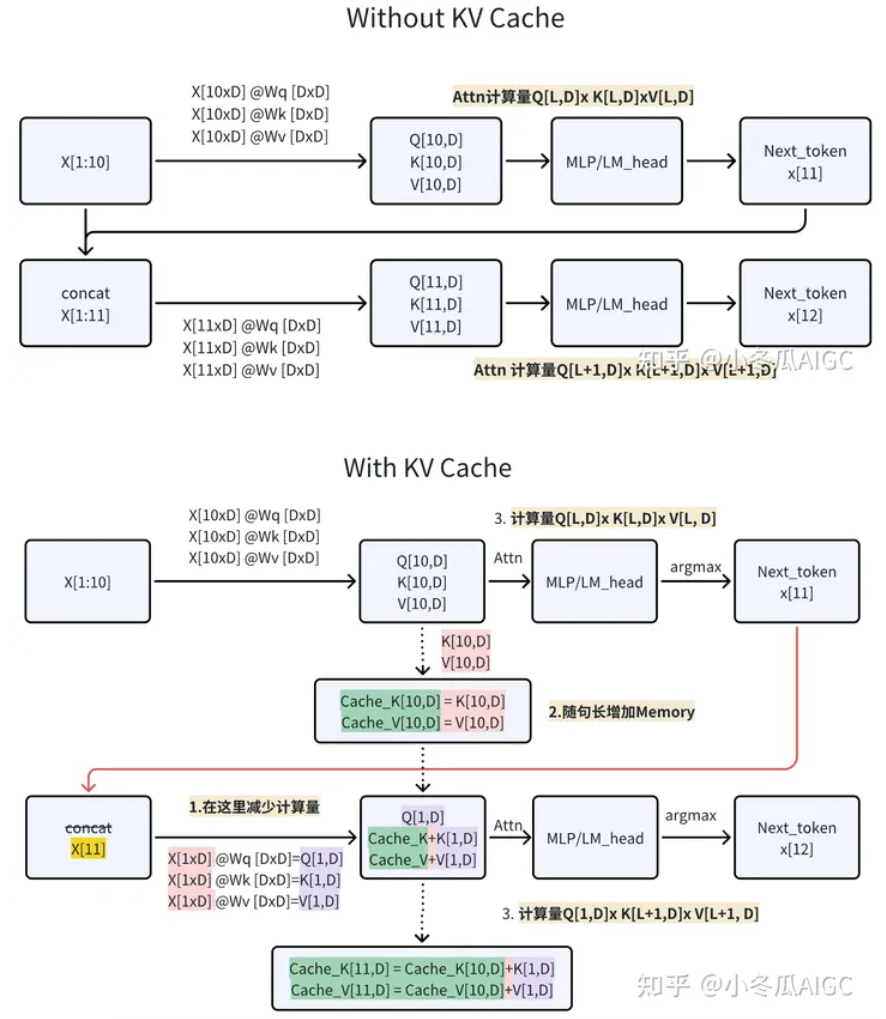
無 KV-Cache 的示意
1 | |
結果是
1 | |
有 KV-Cache 的示意
- KV Cache Initialization:
kv_cache = None: Before the loop, initialize the cache toNone. It will store the key-value pairs after the first pass through the model.
- Model Call with KV Cache:
logits, kv_cache = model(x, max_seq_length, input_pos, kv_cache=kv_cache): Pass thekv_cacheinto the model. On the first forward pass,kv_cacheisNone, but the model returns the computed keys and values and updateskv_cachewith these values for future iterations.- On subsequent passes, the
kv_cachecontains the keys and values for previously seen tokens, so the model only needs to compute new keys and values for the new token.
How KV Cache Works:
- Initial Pass: When generating the first token, the model calculates the attention for all tokens in the current sequence and stores the key-value pairs in
kv_cache. - Subsequent Passes: For each newly generated token, the model only computes the key and value tensors for that specific token. The cached key-value pairs are used for all previous tokens, thus reducing the amount of computation needed for the model’s attention mechanism.
To fully integrate KV caching, you’d need to modify the model itself to support this mechanism, ensuring it can accept and return cached keys and values for reuse during token generation.
1 | |
1 | |
有 KV-Cache 的實施例 (from NanoGPTplus)
- 此處 enable kv cache code 都放在 generate. 但需要 model 本身支持 kv_cache as input and output kv_cache. 下例會揭開黑盒子說明如何實現。
- 另外只用一個 token 也是放在 generate, 而不是 model 內部。
- 此處使用 Top-K Sampling instead of Greedy Sampling
檢查 idx, kv_cache, context 的 shape (dimension)
- idx : (batch, seq_len): batch =1 而且 seq_len 每次加 1.
- kv_cache: (k/v, batch, num_head , seq_len, head_dim) = (2, 1, 12, s, 64)
1 | |
PicoGPT 例子
A very simple picogpt sample code shows: with kv cache / without kv cache = 0.44 / 0.14 = 3X faster! (input, output) = (29, 100) tokens /ml_code/Cursor/nanogpt/nanogpt.py
/ml_code/Cursor/nanogpt/nanogpt.py
重點:
- 此處 enable kv cache code 放在 generate. 但需要 model 本身支持 kv_cache as input and output kv_cache. 下例會揭開黑盒子說明如何實現。
- 另外只選一個 token 是放在 forward, 而不是 generate。
- 此處使用 Top-K Greedy Sampling
1 | |