Source
- Good YouTube Example https://www.youtube.com/watch?v=xEgUC4bd_qI
- Good YouTube using Llamaindex and LangChain LangChain vs. LlamaIndex - What Framework to use for RAG? (youtube.com)
Introduction [[2023-12-22-LLM_RAG|RAG]], [[2024-08-18-Vector_v_Graph_RAG|RAG2]]
Two common ways to implement RAG
- LangChain: Pure Vector RAG
- LlamaIndex: Mainly Vector RAG, but embedded node and relationship for Graph RAG
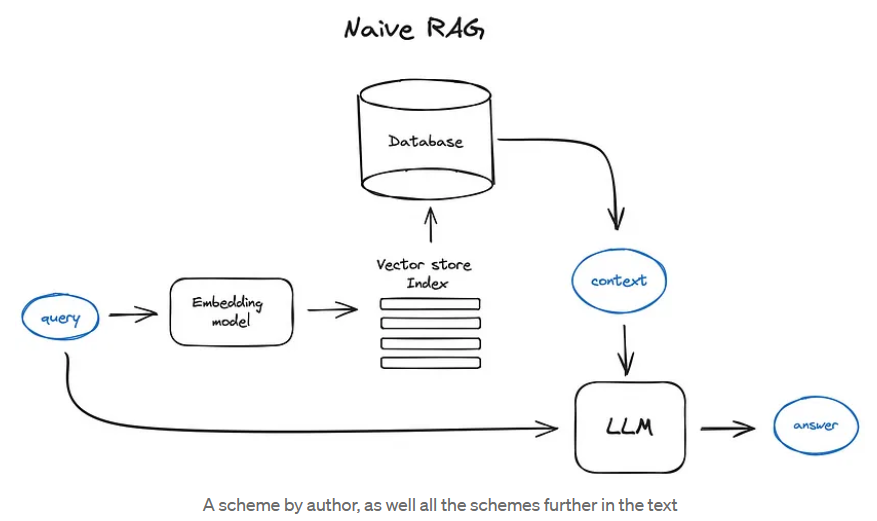
Naive RAG 簡要流程如下:
Indexing phase: 先將文本分割成塊,然後使用某個 Transformer 編碼器模型 (一般是 BERT) 將這些塊嵌入為向量,接著將所有這些向量放入索引中,最後你為大型語言模型(LLM)創建一個提示,告訴模型根據我們在搜索步驟中找到的上下文來回答用戶的查詢。
Query phase: 我們使用相同的編碼器模型 (BERT) 將用戶的查詢向量化,然後對該查詢向量在索引中執行搜索,找到前-k 個結果,從數據庫中檢索相應的文本塊,並將它們作為上下文輸入到 LLM 的提示中。
哪一個是正確的?embedding 是在數據庫之前還是之後?
在檢索增強生成(RAG)系統的上下文中,正確的順序是將文本塊 embedding 在到數據庫(或索引)之前。以下是過程的分解:
- 分塊: 將文本分割成可管理的塊。
- 嵌入: 使用 Transformer 編碼器模型將這些塊嵌入為向量。
- 索引: 將這些向量存儲在索引或數據庫中,以便高效檢索。
- 查詢處理: 當用戶提交查詢時,使用相同的編碼器模型將其向量化。
- 搜索: 對該查詢向量在數據庫中索引的向量執行搜索,以找到前 k 個結果。
- 檢索和提示: 從數據庫中檢索相應的文本塊,並將它們作為上下文輸入到 LLM 的提示中。
![[Pasted image 20240815222426.png]]
LlamaIndex Code
LangChain Code
Appendix A: English Snip
Navie RAG case in brief looks the following way: you split your texts into chunks, then you embed these chunks into vectors with some Transformer Encoder model, you put all those vectors into an index and finally you create a prompt for an LLM that tells the model to answers user’s query given the context we found on the search step. In the runtime we vectorise user’s query with the same Encoder model and then execute search of this query vector against the index, find the top-k results, retrieve the corresponding text chunks from our database and feed them into the LLM prompt as context.
Whic one is correct? Embedding before or after database?
In the context of a Retrieval-Augmented Generation (RAG) system, the correct sequence is to embed your text chunks before storing them in a database (or index). Here’s a breakdown of the process:
- Chunking: You split your texts into manageable chunks.
- Embedding: You use a Transformer Encoder model to embed these chunks into vectors.
- Indexing: You store these vectors in an index or database for efficient retrieval.
- Query Processing: When a user submits a query, you vectorize it using the same Encoder model.
- Search: You execute a search of this query vector against the indexed vectors in your database to find the top-k results.
- Retrieval and Prompting: You retrieve the corresponding text chunks from your database and feed them into the LLM prompt as context.
So, to answer your question: embedding occurs before storing data in the database/index.