Why Parser
improve enginerring efficiency..
markdown issue to fix
Tokenizer, Lexiconer, and Parser
這三者有什麼不同?我們直接用例子說明。
Ex1: Input “I love the dog!”
最簡單的 tokenizer (e.g. Tensorflow Keras 附的 tokenizer) 基本只負責斷 token 的工作,不負責 token 的 attribute => [“I”, “love”, “the”, “dog”, “!”].
Lexiconer 則負責 token + attribute, 不負責判斷是否合乎 syntax (句法或文法) => [(“I”, subject), (“love”, verb), (“the”, article), (“dog”, object), (“!”, punctuation)]
Parser 則有各種 rules for syntax, 判斷 Lexiconer 的 attribute 順序是否合乎 syntax, 例如 => S-V-O OK. 但如果是 “I the dog love!” 則 NOT OK.
Ex2: Input: 21 * (32 + 4) + ab
Tokenizer => [“21”, “*”, “(“, “32”, “+”, “4”, “)”, “+”, “ab”]
Lexiconer => [(“2”, int), (“*”, op), (“(“, para), (“3”, int), (“+”, op), (“4”, int), (“)”, para), (“+”, op), (“ab”, var)]
Reference
一般會用 abstract syntax tree (AST) 來表示這個結果。
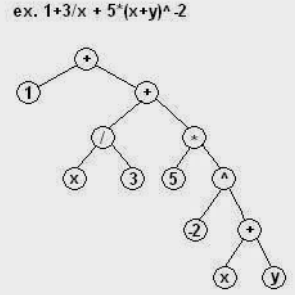
實務上很多 Tokenizer 已經包含 Lexiconer 的工作。好處是效率高,在 tokenize 順便決定 attribute. 壞處是這種 tokenizer 和 application 基本綁定。例如 markdown language 的 token attributes 和 javascript language 的 token attribute 顯然不同,也無法重覆使用。
Tokenizer:
Input: (unstructured or structured) string/text
Method: regular expression
Output: current tokens which includes
- Type: NUMBER, STRING
- Value: 43, “hello”
- and pointer of next token
Input: Token from to
Parser:
Input: “structured” string, i.e. following predefined syntax
Method: tokenizer + … + validation
Output: AST: abstract syntax tree. => validate if the string follow the pre-defined syntax
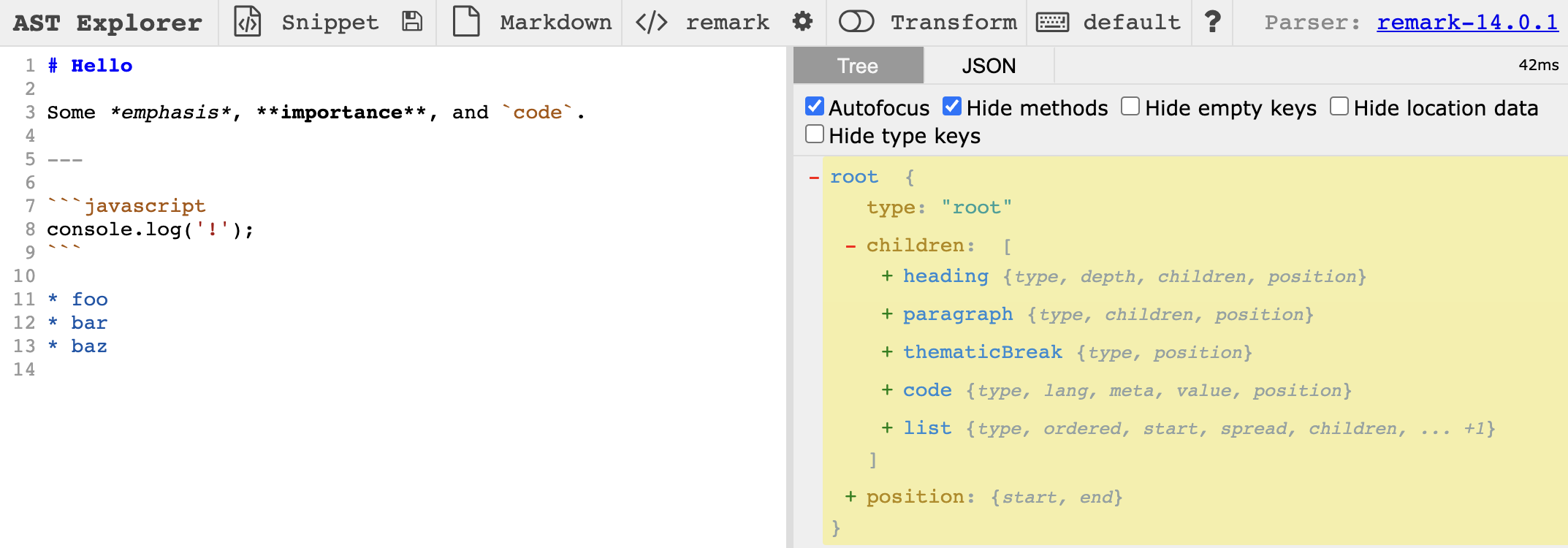
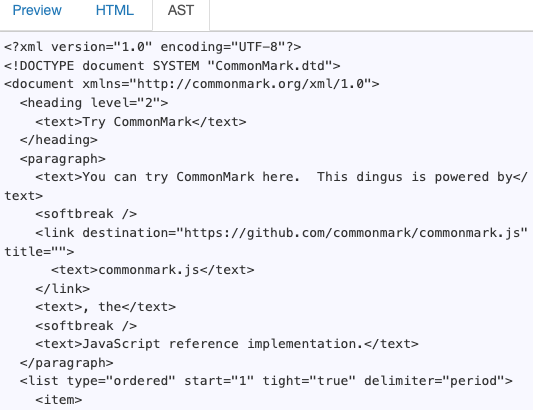
AST 可以參考 AST explorer 的 output. 以 markdown lanaguage 為例。
Either use interactive tree format 如下
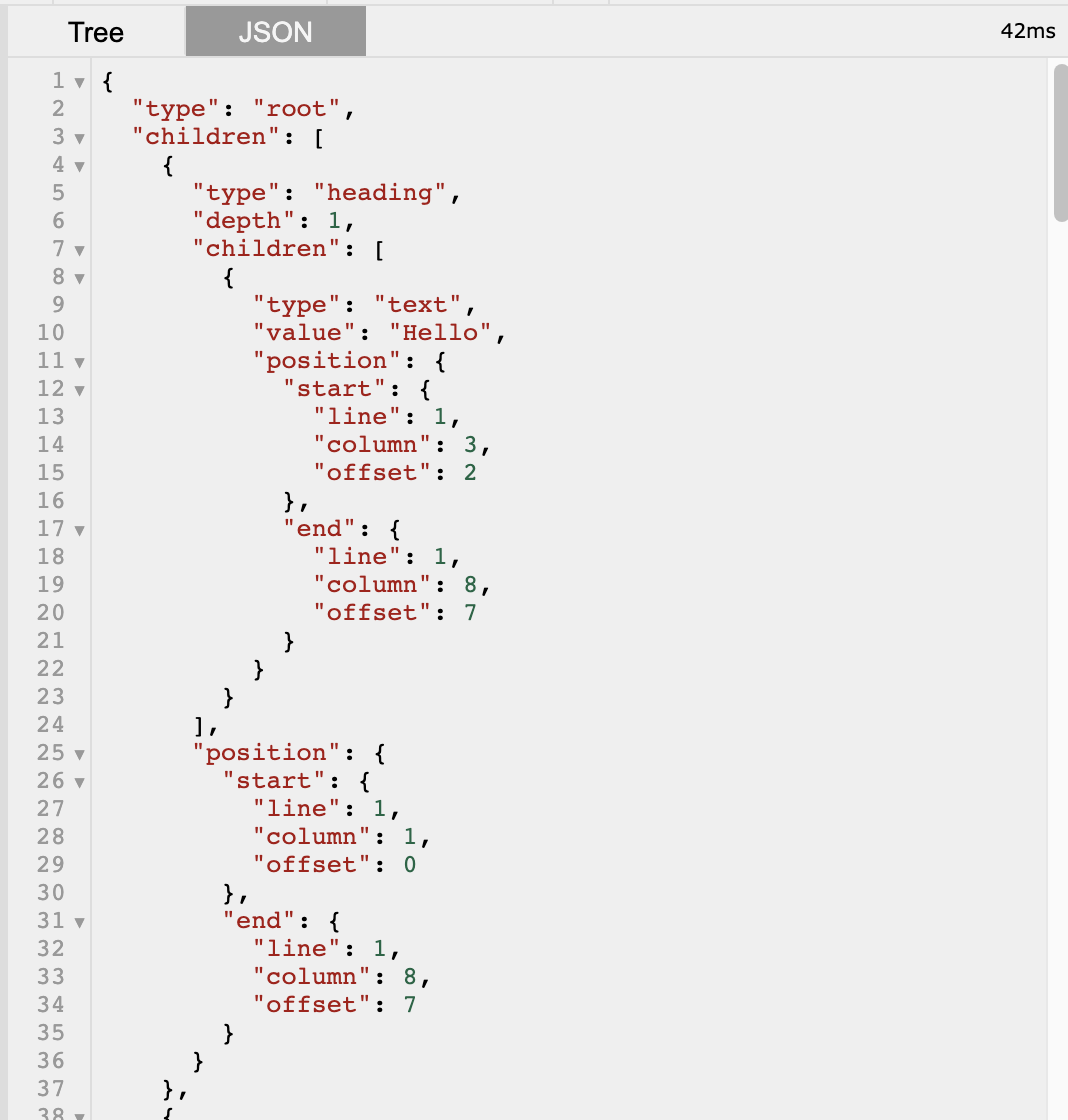
或是 JSON 格式輸出如下。JSON 格式只適合給 program, 應該不是給人看的。
Parser Step 1: Tokenizer
Input: (unstructured or structured) string of the program
Method: regular expression
Output: current tokens which includes
- Type: NUMBER, STRING
- Value: 43, “hello”
- and pointer of next token
Parser Step 2: Statement List
基本把 input string 切分為 multiple statements, 利用 delimiter 如 ;, enter, etc.
Interpreter (line-base)
前面所說的 tokenizer, lexiconer, parser 都是整個 text 為 input for processing.
從 char processing (tokenizer), 到 token processing (lexicon, parser) 都是如此。沒有 line 的觀念。
另一個 dimension 是從 interactive 的角度來看 parser.
如果是整個 text, e.g. from a file, 顯然不是 interactive.
Interactive 一般是以 line 為單位。
User 打完一行,馬上就會有反應。
所以 interpreter 基本是 line processing.
乍看之下只要把 tokenizer, parser 的 input 變成一行 input 就可以。很多應用這樣即可。
但實際應用可能更複雜,因為有些 operation 可能要多行完成。
Useful Parser
Online AST explorer
Pros
- 支持多種語言 (Markdown, Python, etc.)
- 支持 interactive mode (for human) and JSON (for machine)
Cons
- Only output AST (in JSON format)
- Cannot be modified?
Python package: mistune (new version 2.0.2; old version 0.8.4)
Pros
- Output renderer: AST (in XML format) or HTML
- Can modified the python problem to expand, e.g. support MathJax
Cons
- Only markdown
- No interactive mode, hard to debug
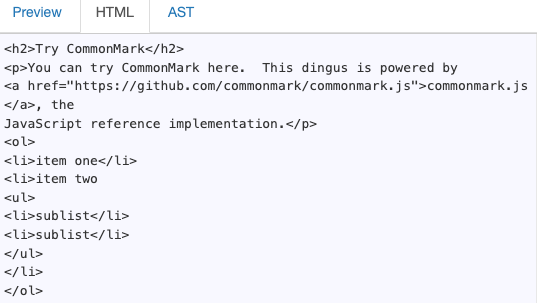
Mistune Example (https://spec.commonmark.org/dingus/)
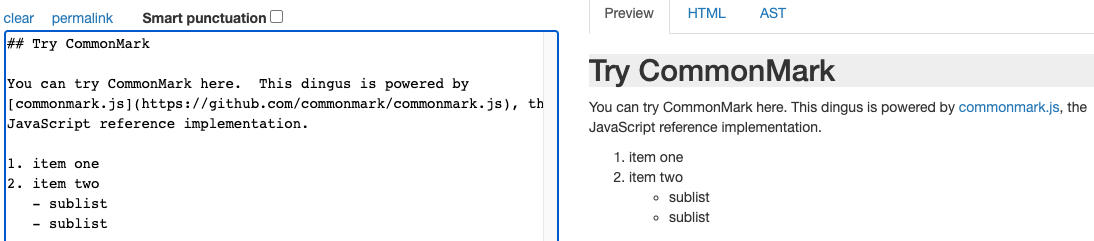
HTML output:
AST output (in XML format)
Parser When and How
Parser 最主要的用途是和 syntax 相關的應用:
- Syntax validation and formatting (beautified)
- Statistics: 例如多少 headlines, lists, formula, etc.
- Translation: e.g. from markdown to html
Tokenizer 最主要的用途是:
- find some keyword using regular expression and make modification based on the keyword, for example
- Remove comment starting with ##
- Replace wording such as 10.5pF to 10.5e-12 F
一個常見的問題是 multi-lines block processing,
- 例如 remove comment between /* …. */
- 或是 nested keywords such as { … { … } … } or begin … begin … end … end
似乎可以用 parser 處理,或是比較好的 tokenizer, 是全局的 string processing, 而非 line by line processing!
而且要可以處理 nested keywords.
其實. parser 的 tokenzier 基本就可以 handle 這個問題。
Mistune: Python’s “Markdown Parser”
Basic Usage
Mistune 的 render output 包含:HTML and AST
基本用法很簡單。就是把 markdown 轉換成 HTML 或是 AST.
v2.0.2: How to Use Mistune — Mistune 2.0.2 documentation
1 | |
v0.8.4: Mistune — mistune 0.8.4 documentation
1 | |
Customized Renderer
客制化可以從 customized renderer 著手。default renderer 是 mistune.Renderer. 有兩類修改。
- 使用 mistune built-in renderer function API, 見 appendix.
- 如果沒有在 built-in renderer function API, 則更深的客制化。
基本的 markdown 被 cover 在 inline 和 block level. 複雜一點的如 table, footnote, strikethrough 則可用 plugin (also built-in v2.0.2).
但是 math block, figure caption 等更複雜則沒有被 cover. 需要自己處理。
我們用兩個 built-in renderer function 的例子。
Ex1: Markdown to HTML: with code block highlight
Markdown 本身沒有顔色。在引用 code block 全部是黑色。當轉換成 html 希望有顔色 highlight, 如下圖 (e.g. C code):
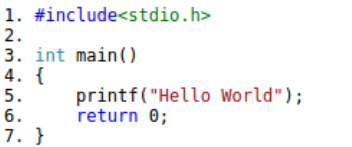
此時可以調用 mistune 的 block_code(self, code, language=None), 以及利用 pygments 完成。
1 | |
Ex2: Add figure caption with inline_html
Ex1: Add figure caption at inline html image <img
Appendix
Mistune 0.8.4 version
Mistune 2.0.2 version
| V0.8.4 | v2.0.2 | |
|---|---|---|
| Markdown to HTML | Mistune.Markdown() | Mistune.create_markdown() |
| Customized Renderer | mistune.Renderer | mistune.HTMLRenderer |
| Built-in Renderer function | API v0.8.x | API v2.0.x |
| Plug-in | strikethrough, table, footnote |
V2.0.2 built-in renderer function API
1 | |
V0.8.4 built-in renderer function API
block_code(self, code, language=None) # 就是 code block: ```lang xxx ```
block_quote(self, text) # 就是 block quote: > xxx
block_html(self, html)
header(self, text, level, raw=None)
hrule()
list(self, body, ordered=True)
list_item(self, text)
paragraph(self, text)
table(self, header, body)
table_row(self, content)
table_cell(self, content, **flags)
# Span level method names:
autolink(self, link, is_email=False)
codespan(self, text)
double_emphasis(self, text)
emphasis(self, text)
image(self, src, title, alt_text)
linebreak()
newline()
link(self, link, title, content)
strikethrough(self, text)
text(self, text)
inline_html(self, text) # 單行的 html, e.g. <img .... />
##
Example:
Ex1: Modified the math block between $$ … $$
Reference
Building a Parser from scratch from Dimitry Soshnikov
https://www.youtube.com/watch?v=0ZDPvdp2uFk&ab_channel=DmitrySoshnikov