Google 是目前語音識別的 leader. 主要使用 RNN-T (Recurrent Neural Network Transducers) model. RNN-T 是 sequence-to-sequence model 的一種,沒有用到 attention mechanism. 另外一般的 sequence-to-sequence model 需要輸入完整的 input sequence, 才會產生 output sequence (e.g. 翻譯)。 RNN-T 可以連續處理 input samples and stream output symbols. 這對於 real-time speech recognition 非常重要。
RNN-T 的 input 是 phonemes, output 則是 characters of the alphabet.
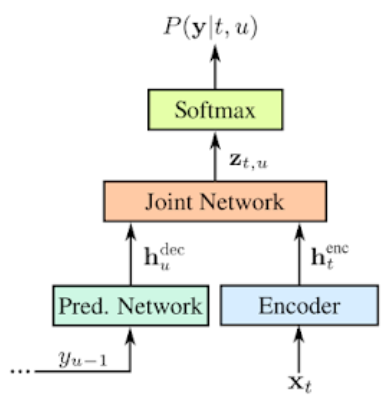
一個 modified version with attention 如下 (Google 2017) with better WER (word error rate).

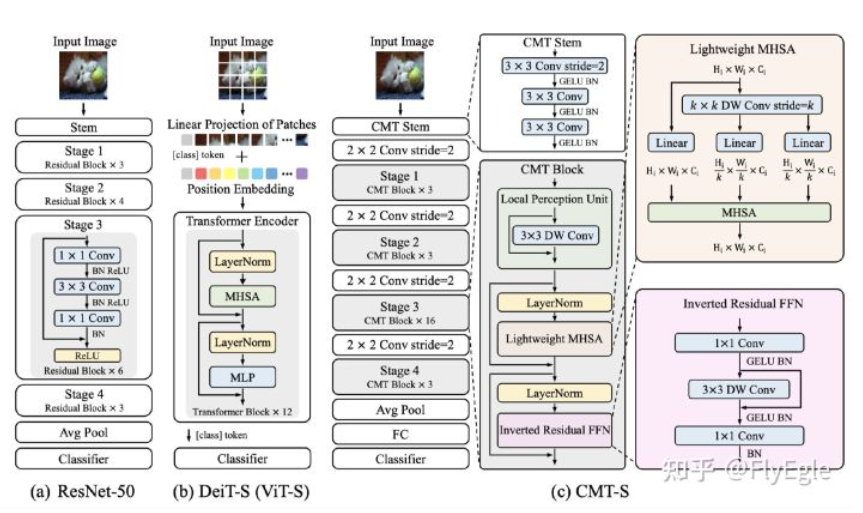
更進一步的是用 transformer base ASR - Conformer (Google 2020). Conformer是Google在2020年提出的語音識別模型,基於Transformer改進而來,主要的改進點在於Transformer在提取長序列依賴的時候更有效,而卷積則擅長提取局部特徵,因此將卷積應用於Transformer的Encoder層,同時提升模型在長期序列和局部特徵上的效果,實際證明,該方法確實有效,在當時的LibriSpeech測試集上取得了最好的效果。完全捨棄 recurrent model.

Attention Mechanism
Spectrum
| Pure Transformer | Transformer+CNN | CNN+Attention | Pure CNN | |
|---|---|---|---|---|
| attention on image patch | attention on image/feature patch | CNN layer+attention | CNN layer | |
| feature is from CNN | 後面的layer 比較有用 | |||
| 三大問題: 1. image patch receptive field 2. position embedding 3. reduce attention computation |
Con Only local attention! No global attention |
|||
| Pro No need for position embedding |
||||
| Ex. | ViT, Swin | DeiT-S (ViT-S) | ResNet-50 |
通過如上三個階段的計算,即可求出針對Query的Attention數值,目前絕大多數具體的注意力機制計算方法都符合上述的三階段抽象計算過程。
總結 attention: \(\operatorname{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\top}}{\sqrt{d_{k}}}\right) \boldsymbol{V}\) where $\boldsymbol{Q} \in \mathbb{R}^{n \times d_{k}}, \boldsymbol{K} \in \mathbb{R}^{m \times d_{k}}, \boldsymbol{V} \in \mathbb{R}^{m \times d_{v}}$ 。如果忽略 activation function softmax,事實上這就是三個矩陣相乘,最後的結果是 $n\times d_v$ 的矩陣。所以我們可以認爲:這是一個 attention layer, 將 $n\times d_k$ 的序列 Q 編碼成一個新的 $n\times d_v$ 的序列。
###
Vision Transformer
是否能把 transformer 作爲 vision backbone network, 類似 CNN 在 vision backbone network 的角色。可以用於 vision 底層 task 如 detection, segmentation, 甚至 quality enhancement;以及中高層的 vision task 像是 classification, image caption, 等等。
CNN 的優點是:computation efficiency, low level feature extraction (filter-like building block), translation equivariant for low level vision。藉著 bottom up to increase the receptive field and pooling to offer scaling invariant and translation invariant.
| CNN in Vision | Transformer in Vision | Transformer in NLP | |
|---|---|---|---|
| Low level vision translation equivariant |
Yes | Need to solve | No need |
| Low level vision scale equivariant |
CNN Pyramid | No need | |
| High level translation invariant |
feature pyramid+FC layer | Yes | |
| High level scale invariant |
feature pyramid+FC layer | NO | |
| High level Permutation sensitive |
Position embedding | Position encoding | |
| Vision charateristics | best fit for vision spatial locality | No constraint by vision locality |
本文主要討論 transformer 用於 vision. 有兩種類型: (I) pure transformer, Vision Transformer or ViT; (II) combined CNN + attention (本文不討論).
Why introduce transformer or attention to vision? (1) better performance for classification, detection, segmentation, or quality; (2) vision + NLP tasks such as vision caption, etc.
CNN Pro and Con
| CNN | Transformer/Attention | |
|---|---|---|
| Receptive field | small, need deep layers | Wide, use FC layer |
| Feature | local feature | long range feature |
| Scope | bottom up | Top down |
combine feature extraction and …?
Pure transformer
Transformer + CNN
Self Attention Module (Type II, Use CNN feature map, 本文不討論)
Straightforward:
- image or feature patch patch use for self-attention
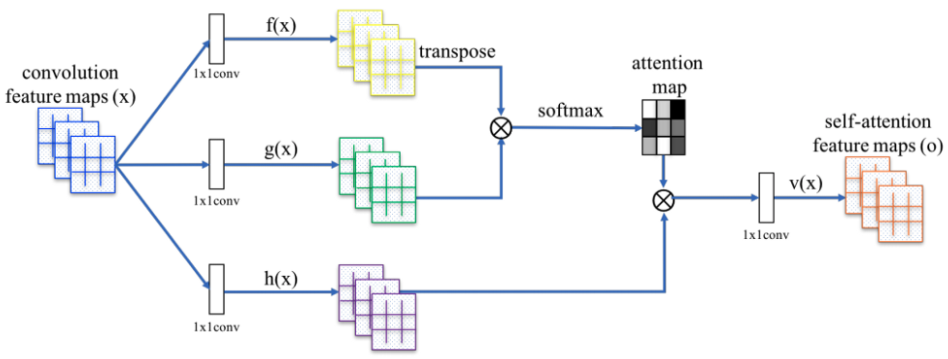
- Feature patch use for self-attention
三部曲:
- image
- Image pyramid (spatial pyramid) for scaling invariant
- Image + feature pyramid (CNN) for scaling invariant and receptive field
Transformer Pro and Con
Separate feature extraction and …?