本文是《The Illustrated GPT-2 (Visualizing Transformer Language Models)》第二部分。
文章目錄
自注意力 圖解Masked Self-attention GPT-2 的 Masked Self-attention
- 創建queries, keys和values 1.5 劃分注意力頭
- 注意力分數
- 求和 3.5 合併注意力頭
- 映射 projection
GPT-2 全連接神經網絡第一層 GPT-2 全連接神經網絡第二層:投影到模型維度
Part 2: Self-Attention Illustration
用前文的機器人守則的例子。下圖中表示的是使用自注意力處理輸入序列中的 “it” 單詞的時候。

接下來我們詳細介紹一下這一過程是如何實現的。
注意,接下來的圖解過程會用到很多 “向量” 來圖解算法機制,而實際代碼實現是使用 矩陣 進行計算的。這個分析過程是想讓讀者瞭解在處理過程中每個單詞發生了什麼,因此本文的重點是對單詞級(word-level)處理邏輯進行解析。
自注意力 (Self-Attention Without Masking)
我們從原始的自注意開始,它是在一個Transformer組件(encoder)中計算的。我們先來看看這個簡單的Transformer組件,假設它一次只處理四個tokens。
僅需三步即可實現自注意力:
-
為每個單詞路徑創建 Query、Key、Value vectors。
-
對於每個輸入token,使用其 Query 向量對其他所有的 token 的 Key 向量進行評分,獲得注意力分數。
-
將 Value 向量乘以上一步得到的注意力分數,之後加起來。
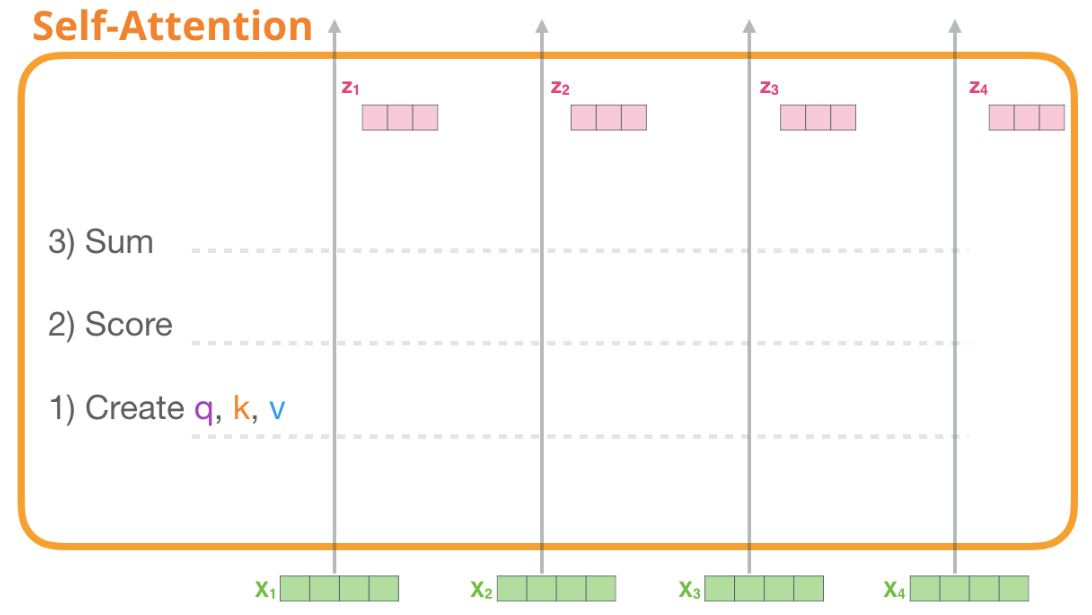
1- 創建Query、Key、Value Vectors
現在我們只關注第一個路徑, 我們需要用它的Query和所有的Key比較,這一步驟會為每個路徑都生成一個注意力分數。
先不管什麼是多頭自注意力,只考慮自注意力,也就是只有一個head的情況。自注意力計算的第一步就是要計算出每個路徑的Query、Key、Value三個向量。
-
看下圖是一次處理四個 tokens,每個 token 都有它單獨的路徑,第一路徑指的是 $X_1$ 這個 token。
-
對於每個 token 來說對應的 Query、Key、Value是三個向量,而在實際代碼計算中是使用整個輸入序列的矩陣。
-
獲得Query、Key、Value三個向量的方法是 每個單詞的表示向量和對應的權重矩陣 ($W^Q, W^K, W^V$) 做矩陣乘法。
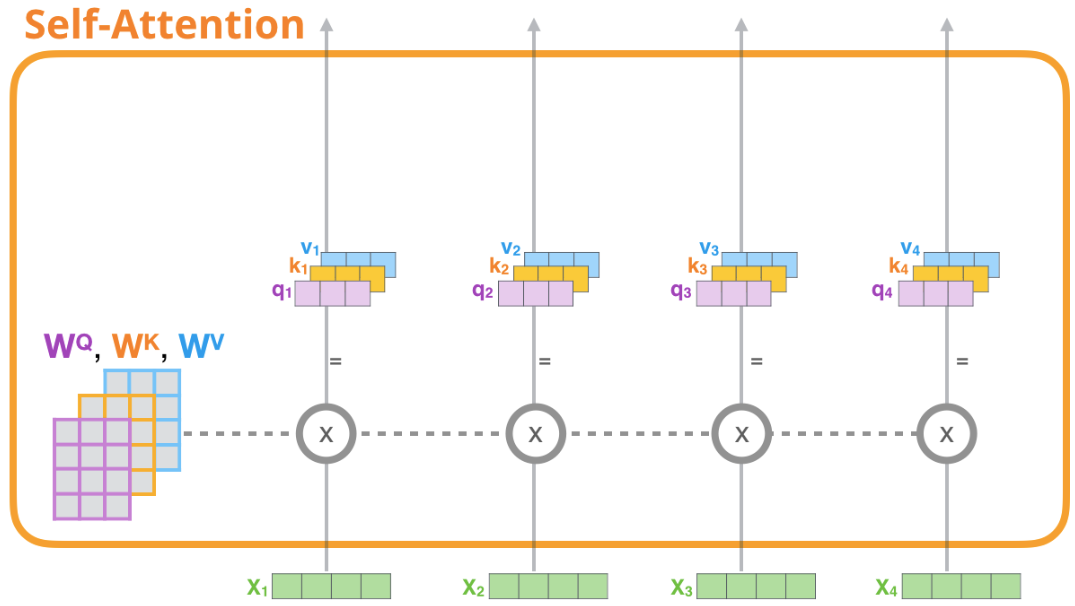
2- 計算注意力分數
現在我們已經有了Query、Key、Value三個向量。在第二步我們只需要用到 Query 和 Key 向量。因為我們關注的是第一個 token,所以我們將第一個 token 的 Query 和其他 token 的 key 向量做點乘,這樣計算會得到每一個 token 的注意力分數。

3- 求和
現在對於每個token,將上一步得到的注意力分數乘以Value向量。將相乘之後的結果加起來,那些注意力分數大的占比會更大。
對於Value向量,注意力分數越低,顏色越透明。這是為了說明乘以一個小數如何稀釋不同token的Value向量。
看下圖,注意力分數乘以每個Value向量,原作者用不同深淺的藍色的框框表示計算之後的結果。可以看到 $V_3$ 比較顯眼,$V_2$ 幾乎看不到了,然後將計算結果加起來得到 $Z_1$。這個 $Z_1$ 就是 $X_1$ 新的表示向量,這個向量除了單詞本身,還涵蓋了上下文其他 token 的信息。
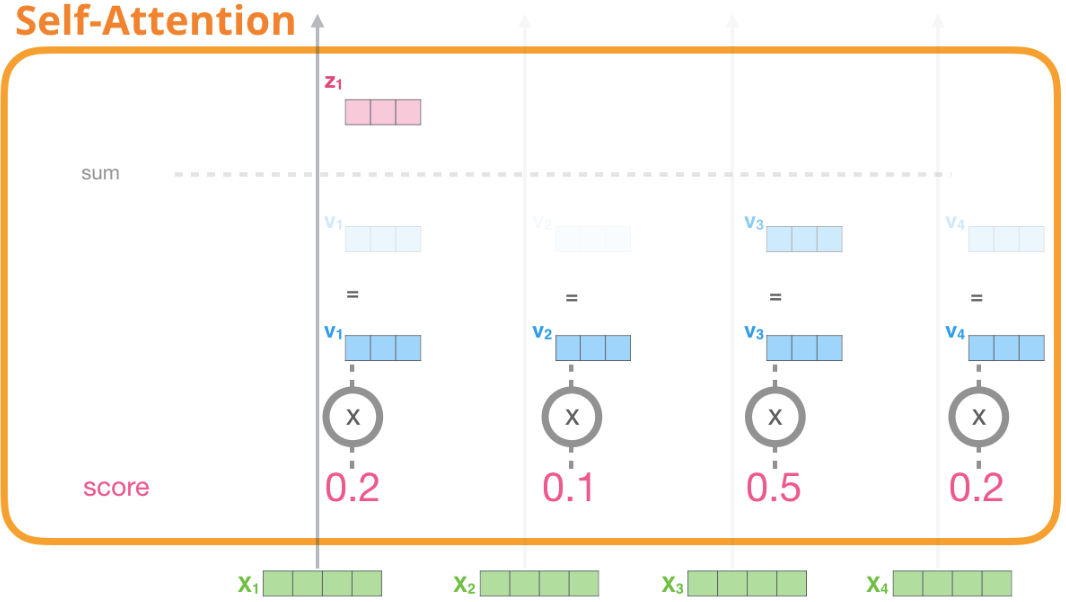
這一過程可以認為注意力分數就是表示不同單詞重要性的權重,而整個自注意力計算就是求所有token的加權和,這一過程可以引入其他token的表示,讓當前token獲得上下文信息。
之後我們對每個token都進行相同的操作,最終會得到每個token新的表示向量,新向量中包含該token的上下文信息。之後會將這些數據傳給Transformer組件的下一個子層(前饋神經網絡):
圖解 Masked Self-attention
現在我們已經瞭解了Transformer中普通的自注意力機制,讓我們繼續看看帶Masked自注意力。
Masked自注意力和普通的自注意力是一樣的,除了第二步計算注意力分數的時候有點差異。
假設模型只有兩個token作為輸入,我們當前正在處理第二個token。在下圖的例子中,最後兩個token會被屏蔽掉。這樣模型就可以干擾計算注意力分數這一步驟,它會讓未輸入的token的注意力得分為0,這樣未輸入的token就不會影響噹前token的計算,當前token的注意力只會關注到在它之前輸入的tokens。
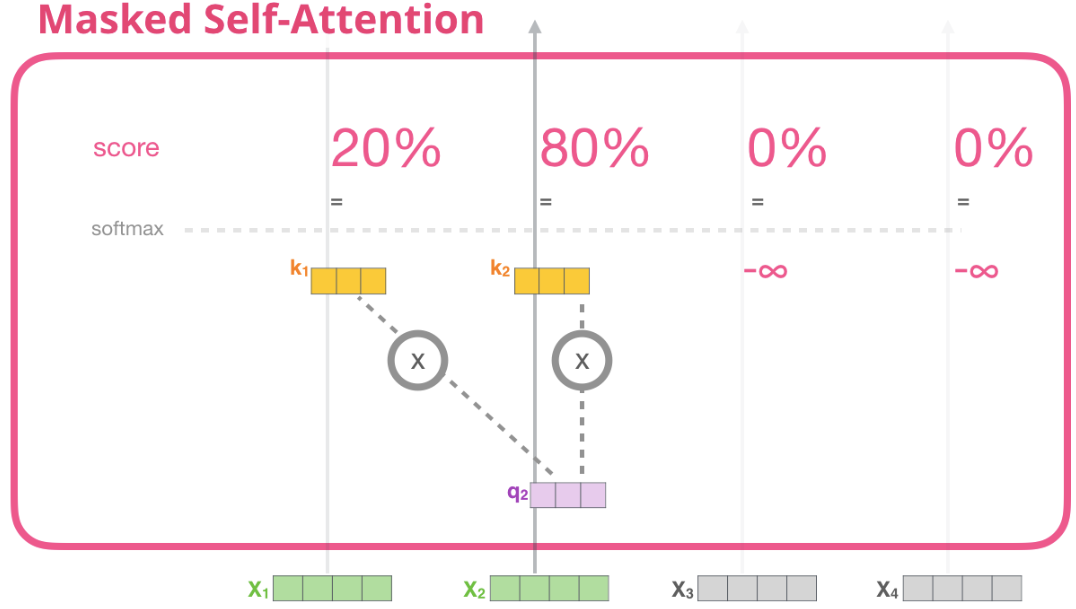
這種屏蔽通常以矩陣的形式實現,稱為注意力屏蔽(attention mask)。
還是假設輸入序列由四個單詞組成,例如robot must obey orders。在語言建模場景中,每個單詞需要一個步驟處理(假設現在每個單詞都是一個token),因此這個序列包含四個處理步驟。由於模型是按照批量(batch)進行處理的,我們可以假設這個模型的批量大小為4(batch_size = 4),然後模型將把整個序列作為一個batch進行處理。

假設現在每個單詞都是一個token。單詞 word 不一定等於 token,這是由分詞方式決定的。token無法直接計算注意力分數,因此我們需要用 tokens 對應的 Query 和 Key 進行計算。搞成矩陣乘法的形式,我們通過將Query向量乘以Key矩陣來計算注意力分數。
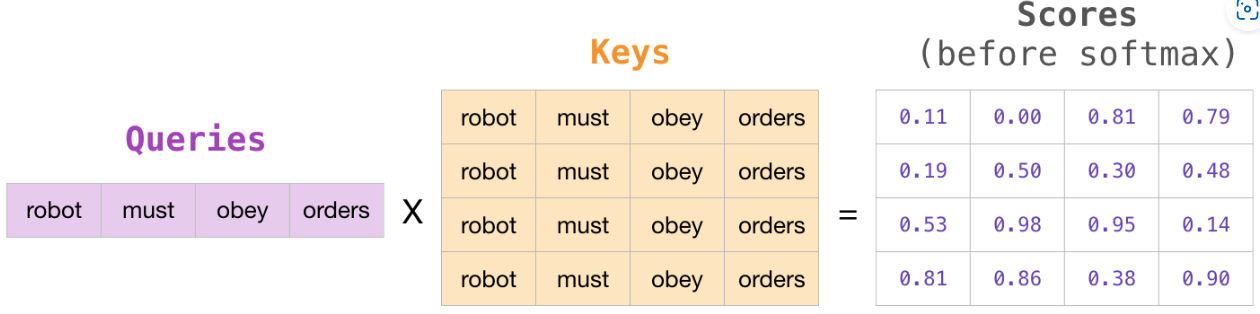
完成乘法運算後,我們要加上一個mask矩陣屏蔽掉當前還未輸入的詞,就是加一個上三角形矩陣,一般是將我們想要屏蔽的位置設置為 -inf 或一個非常大的負數(GPT-2 為 $-10^9$):

然後,對每一行進行 softmax 就會轉化成我們需要的注意力分數:

這個分數表的含義如下:
-
第一步:只輸入一個詞robot,當模型處理數據集中的第一個單詞時,也就是score矩陣的第一行,因為其中只包含一個單詞robot,所以它的注意力100%集中在這個單詞上。
-
第二步:輸入robot must,當模型處理第二個單詞must時(score矩陣第二行),48%的注意力會放在robot上,52%的注意力會放在must上。
-
以此類推……
GPT-2 的 Masked Self-attention
讓我們更詳細地瞭解一下 GPT-2 中的masked注意力。
Evaluation Time:每次處理一個 token。
使用訓練好的模型進行預測的時候,模型在每次疊代後都會增加一個新詞,對於已經處理過的token來說,重新計算之前路徑的效率很低。
因為一個訓練好的模型,每個組件的權重矩陣是固定的。每次增加一個token都要重新計算整個輸入序列的QKV的話會造成巨大的計算開銷。 比如a robot must obey the rule,如果第一次疊代時候只有a,僅需要計算它的QKV,第二次疊代時候是a robot,就需要計算二者的QKV。但是這樣就重複計算了a的QKV
GPT-2的高效處理方法如下:
假設我們處理輸入序列的第一個token “a”,(暫時忽略,依次為 query/key/value)。
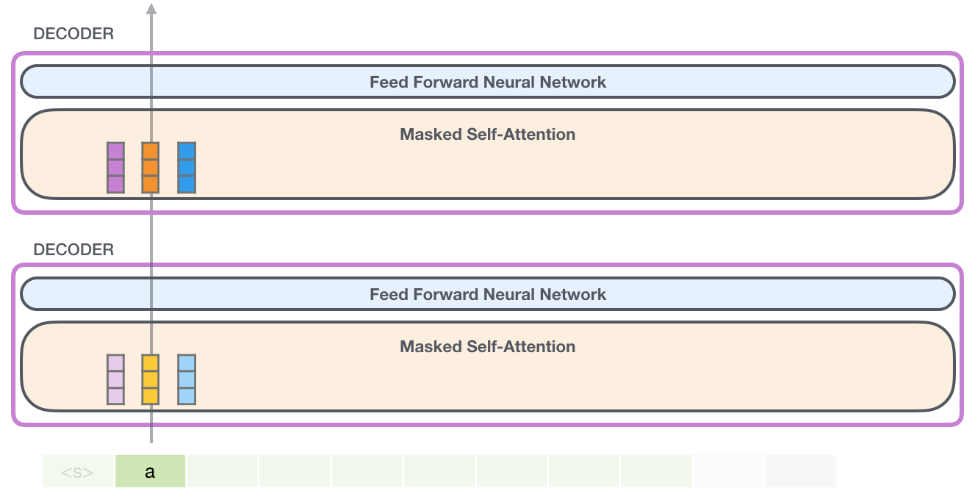
之後GPT-2會保留 “a” token 的 Key 和 Value 向量。以便之後使用。
- 注意,每個組件的自注意力層都有各自的Key和Value向量,不同的組件中 Key 和 Value 向量不共享:
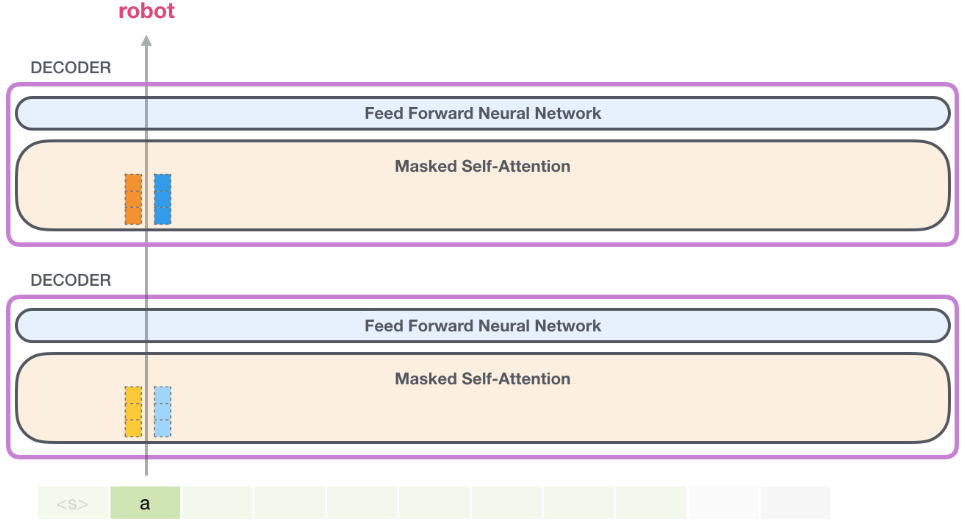
在下一次疊代中,當模型處理單詞 “robot” 時,它不需要為 “a” 重新生成 Query、Key、Value,而是直接用第一次疊代中保存的那些:

1) 創建 queries, keys, and values
讓我們假設這個模型正在處理單詞 “it”。如果我們討論的是最底層的decoder組件,那麼它接收的token的輸入是 it 的 embedding + 第 9 個位置的位置編碼:

Transformer中的每個組件之權重不共享,都有自己的權重。我們首先要和權重矩陣進行計算,我們使用權重矩陣創建 Query、Key、Value。
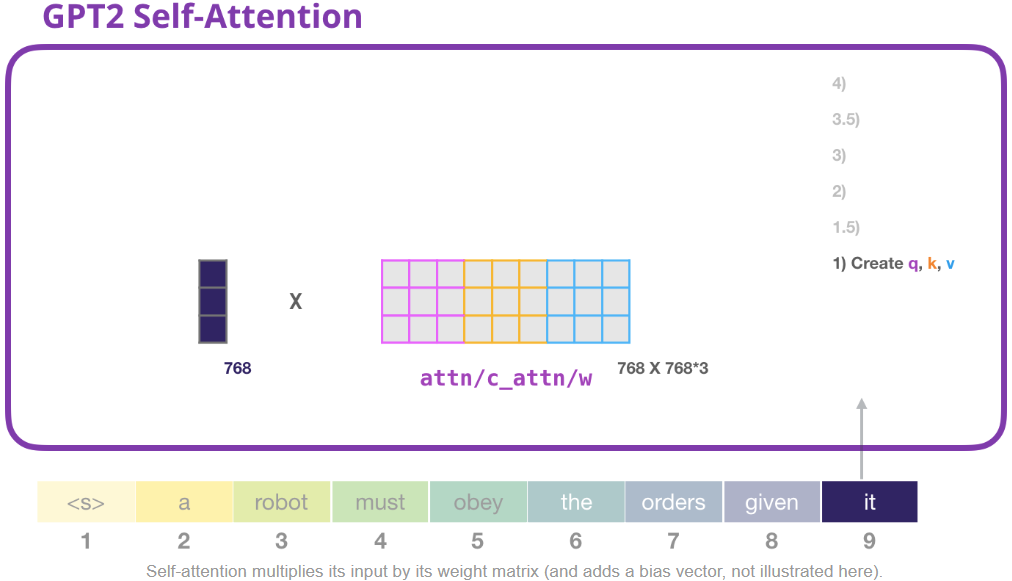
自注意力子層會將輸入乘以權值矩陣(還會加上bias,圖中沒表示出來),乘法會產生一個向量,這個向量是單詞it 的 Query、Key、Value 的拼接向量。
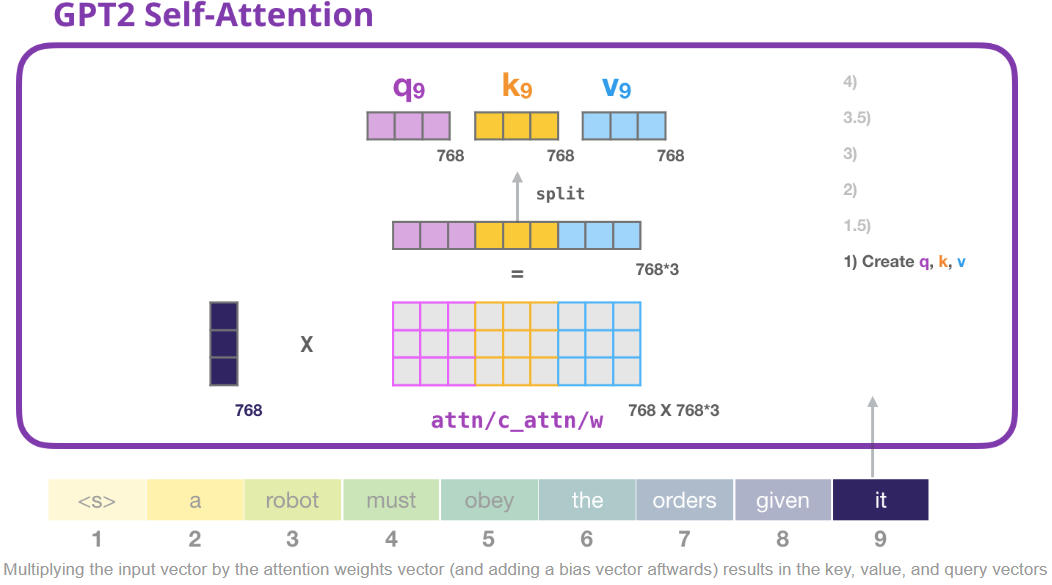
將輸入向量乘以注意力權重向量(然後添加一個偏差向量),就會得到這個token的Query、Key、Value向量。
1.5) 劃分注意力頭 (Splitting into attention heads)
在前面的例子中,我們只專注于自注意力,忽略了“多頭”(muti-head)的部分。現在説明什麼是“多頭”。 就是將原來一個長的Query、Key、Value向量按照不同位置截取並拆分成短的向量做多次的自注意力。
實際的做法是 reshape long vector into a matrix. Small GPT2 有 12 個 attention heads. 因此下圖的 row dimension 為 12 (12x64).
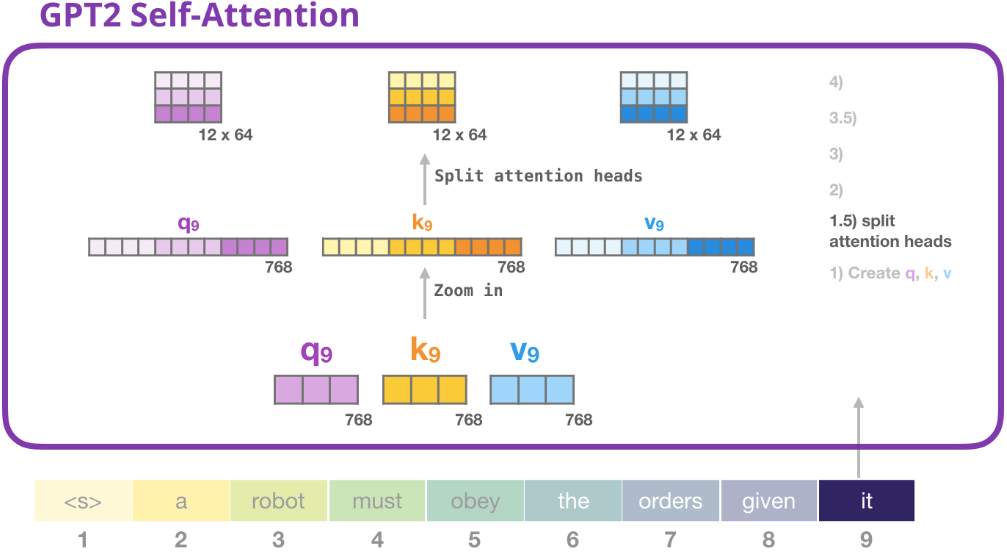
前邊的例子中我們已經瞭解了一個注意力頭怎麼計算,現在我們考慮一下多頭注意力,如下圖考慮有三個 heads (實際有 12 heads)。
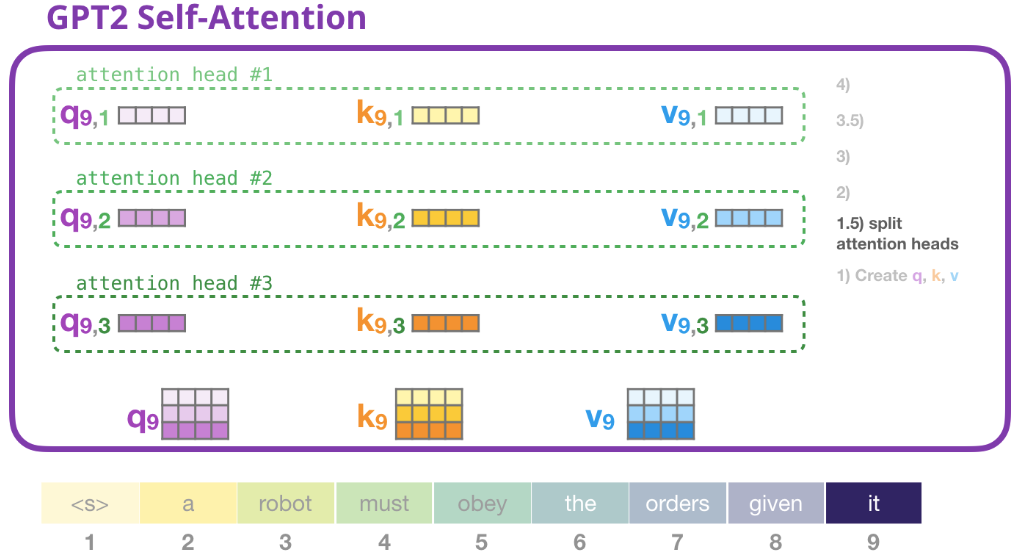
2) 注意力分數
現在我們可以開始打分了。我們這只畫出來一個注意力頭(head #1),其他的頭也是這麼計算的:
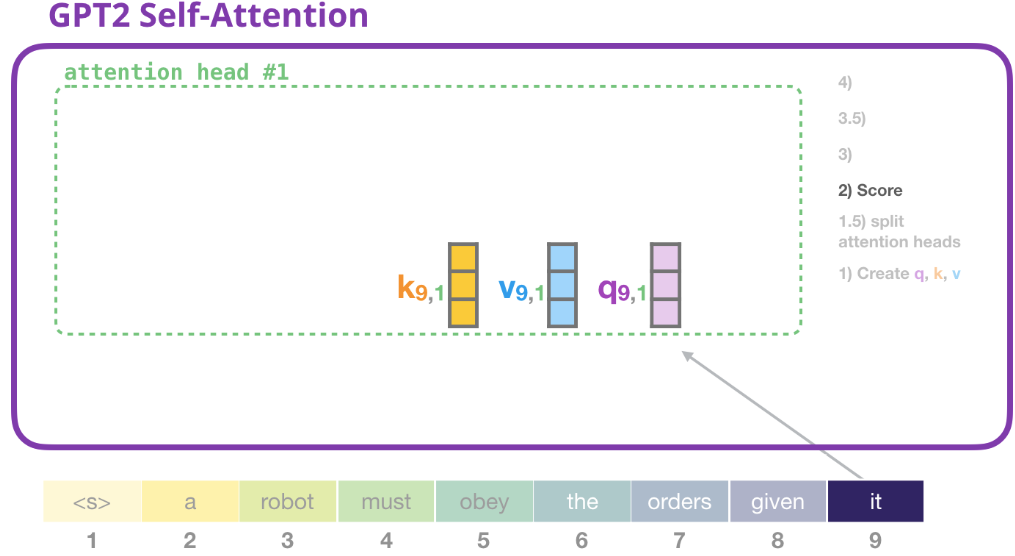
現在,該token 可以針對其他 token 的所有 Value 進行評分:
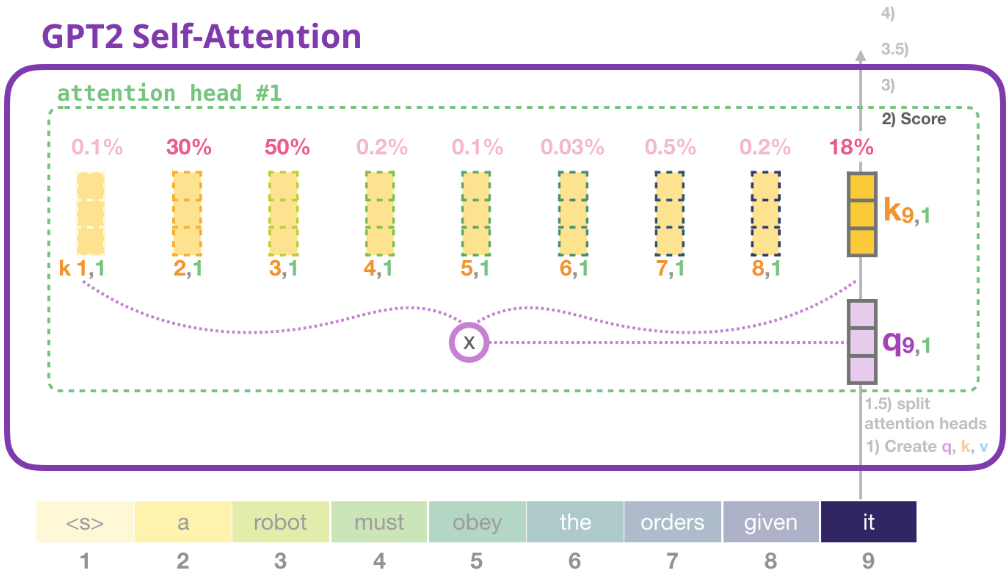
3) 求和
和前邊講的一樣,我們現在將每個Value與它的注意力分數相乘,然後將它們相加,產生head #1的自注意結果 $Z_9$:
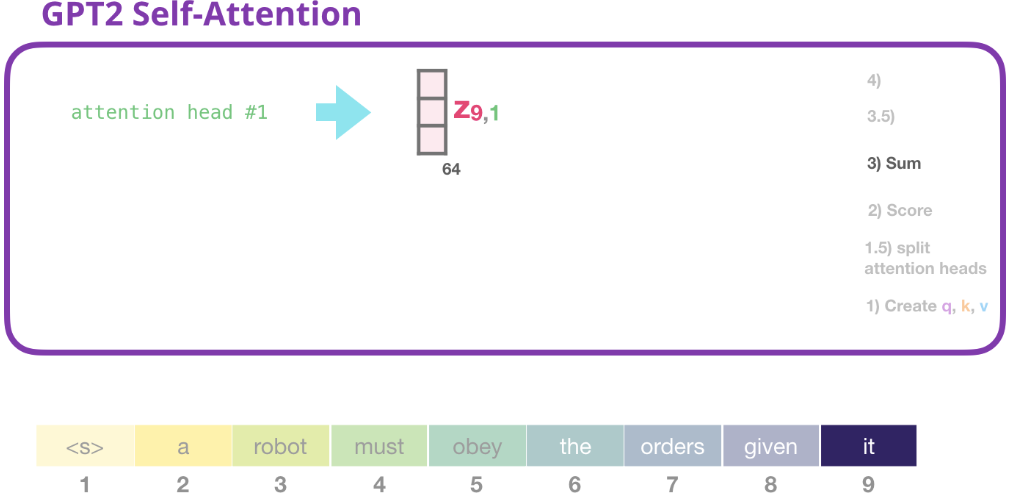
3.5) 合併注意力頭
不同的注意力頭會得到不同的 $Z_9$,我們處理不同注意力頭的方法是把這個 $Z_9$ 連接成一個向量:
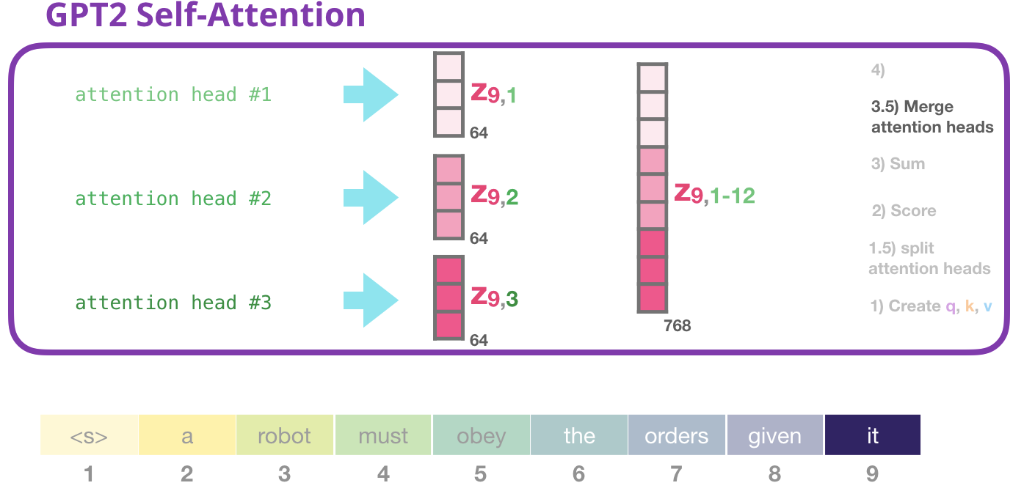
但是這個拼接結果向量還不能傳給下一個子層。我們需要把這個拼接向量再做一次魔改,得到另一個同類表示。
拼接向量再做一次projection(映射): 對於這句我存在一些疑問。因為我看了其他人對這篇文章的翻譯,如下圖,這個人說這裡的projection是因為維度不對,需要調整維度。這是錯誤的!!! 看下邊第4節可以知道這個projection並沒有改變維度、向量長度。至於為什麼這裡需要projection,第4節也進行瞭解釋。
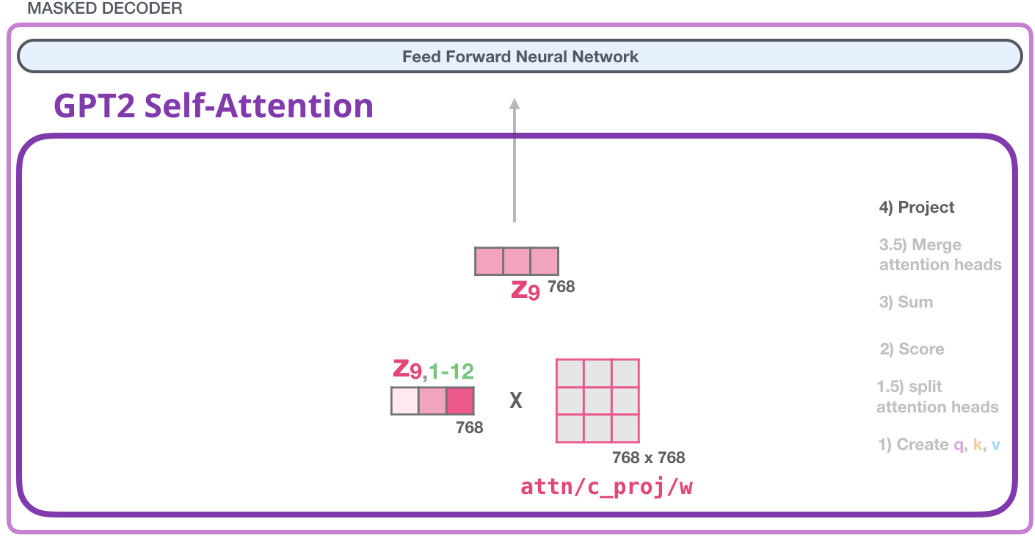
4) 映射 projection
我們要讓模型學習到 如何將自注意力的拼接結果更好地映射成前饋神經網絡可以處理的向量 。因此這裡要做一步映射。
在這就用到了我們的第二大權重矩陣,它將自注意力的拼接結果映射為自注意力子層的輸出向量:
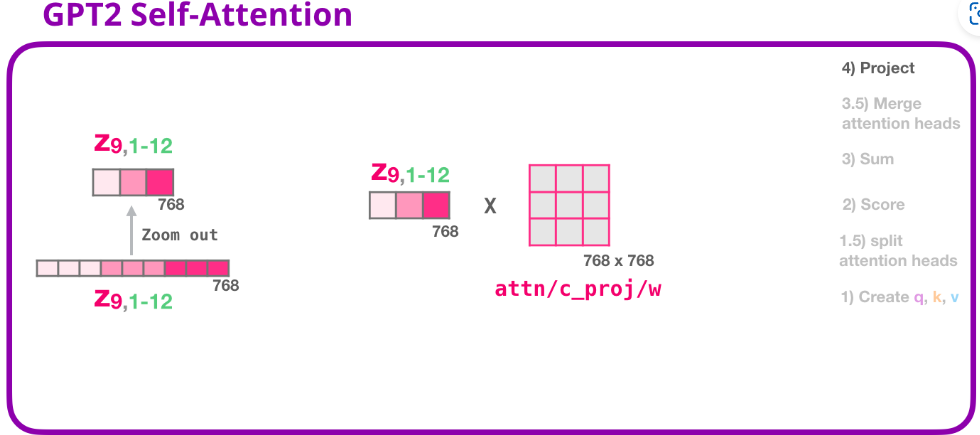
注意這裡的Zoom out意思是維度沒有變,只是用更少的格子來表示這個向量。
既然這有一個權重,那肯定模型訓練過程中要學啊,學這個權重矩陣的目的就是為了讓模型能把自注意力計算之後拼接的那個矩陣 映射到 前饋神經網更好處理的矩陣,個人認為這裡的projection就是做了一個平滑作用。
之後我們就產生了可以發送到下一層的向量:
GPT-2 全連接神經網絡 (Feed Forward NN):第一層
全連接神經網絡的輸入是自注意力層的輸出,用於處理自注意力子層得到的新 token,這個新的表示包含了原始 token 及其上下文的信息。
全連接神經網絡由兩層組成。第一層是把向量轉化到模型大小的4倍(因為GPT-2 small是隱狀態大小是768,所以GPT-2中的全連接神經網絡第一層會將其投影到768*4 = 3072個單位的向量中)。為什麼是四倍?因為原始Transformer的也是四倍,似乎可以足夠的表達能力,因此這裡就沒改。
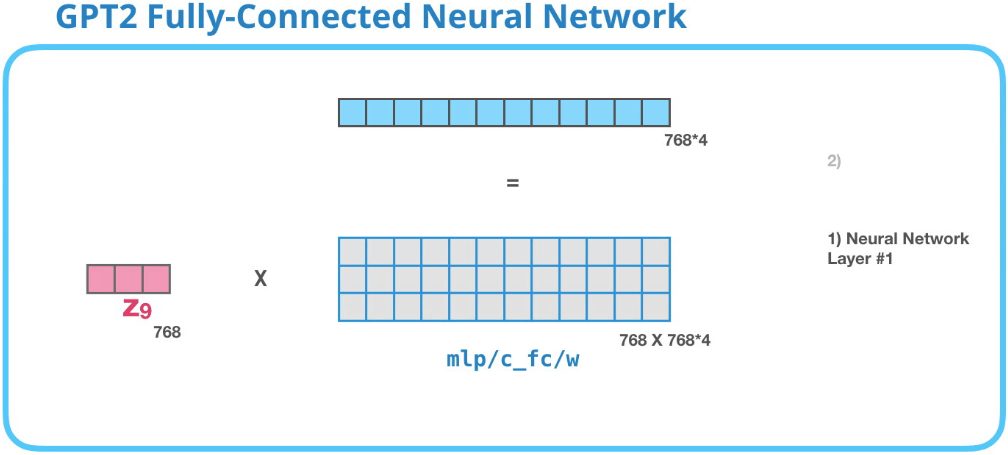
上圖沒畫出bias。
GPT-2 全連接神經網絡第二層:投影到模型維度
第二層將第一層的結果再投射回模型的維度(GPT-2 small為768)。這個計算結果就是一個完整的Transformer組件(decoder)對token的處理結果。
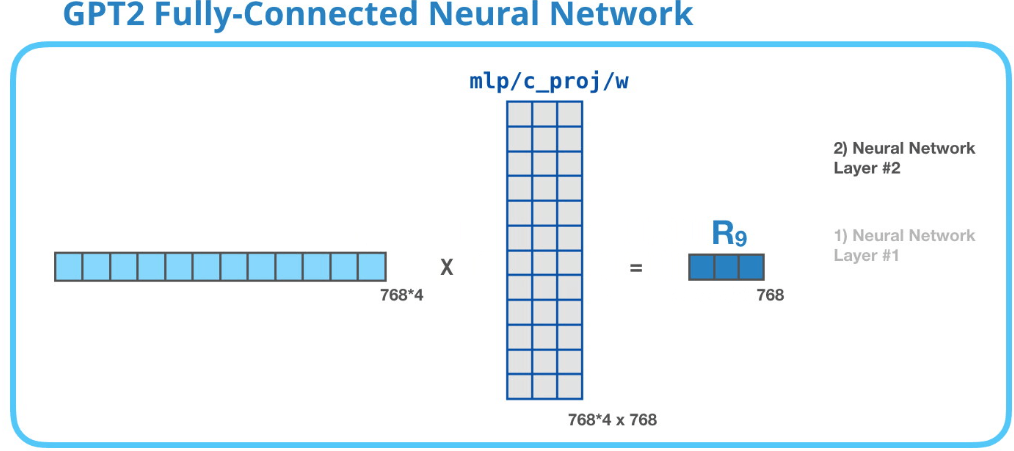
上圖沒畫出bias。
總結
輸入向量都會遇到哪些權重矩陣:
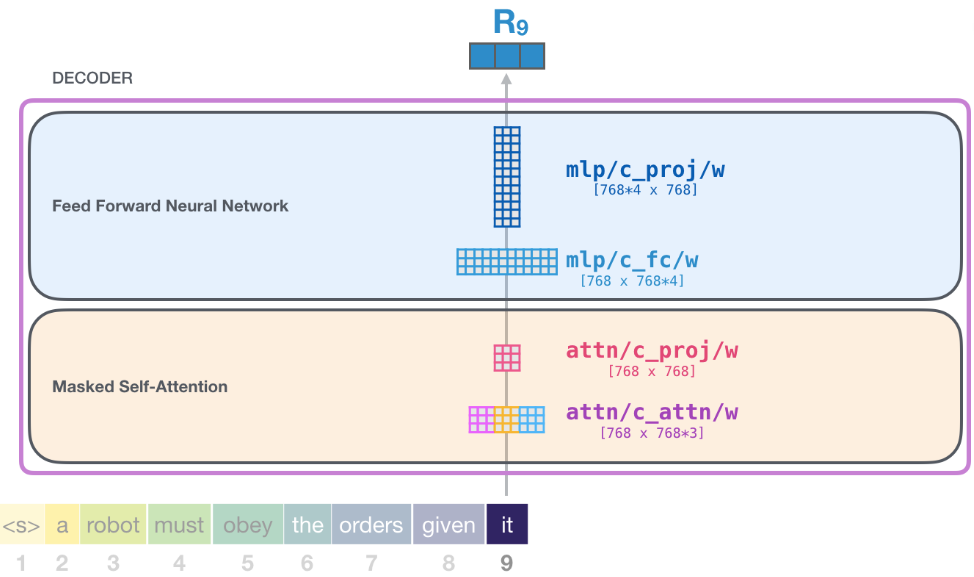
每個 Transformer 組件都有自己的權重。組件之間權重不共享!
另外,該模型只有一個token的嵌入矩陣和一個位置編碼矩陣:
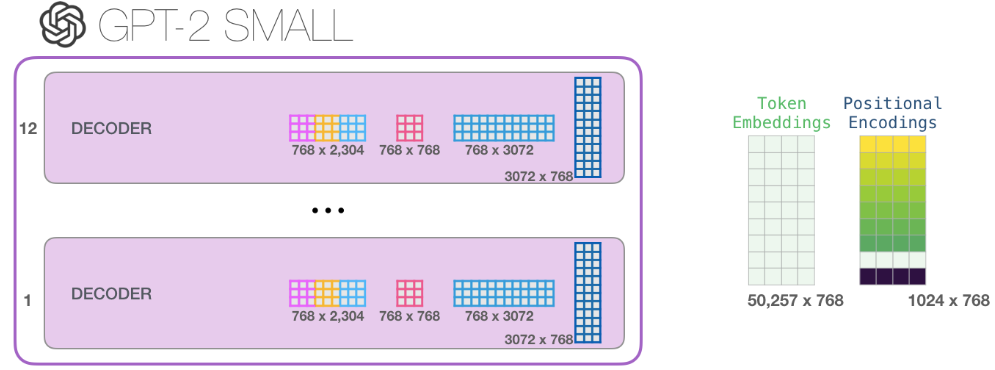
如果你想知道模型的所有參數,我在這進行了統計:
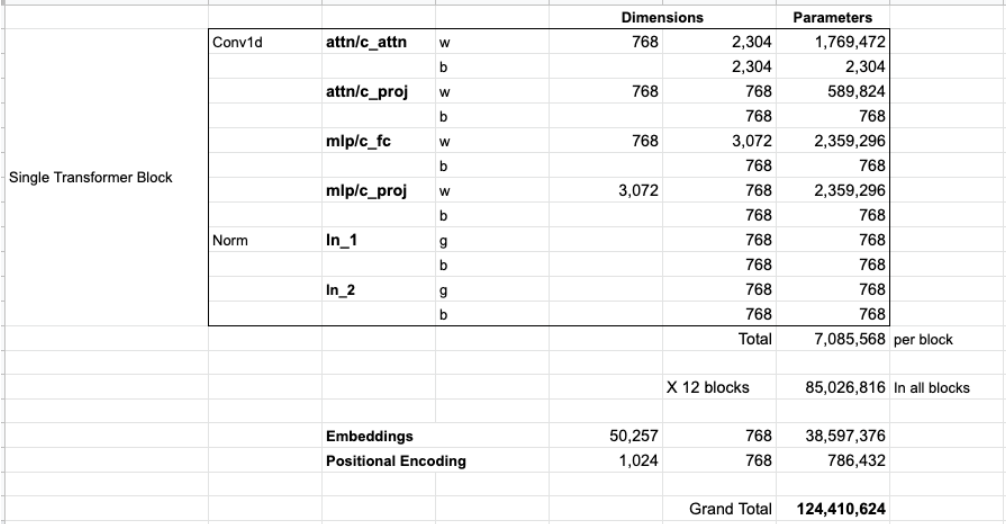
由於某種原因,它們加起來有124M的參數,但是實際GPT-2 small模型只有117M參數。我不知道為什麼,但這就是他們發佈的代碼中的參數數量(歡迎指正)。
上圖中作者對GPT-2 small的參數進行了統計,計算結果和 OpenAI 開源的GPT-2模型的參數量不一樣。 作者算的是124M,實際代碼中只有117M, 原因如下: OpenAI團隊說:“我們論文裡參數計算方法寫錯了。所以你現在可以看到GPT-2 small模型參數隻有117M……”
Part 3: Beyond Language Modeling
Decoder-only Transformer 對於語言建模以外也非常有用。很多其他的應用也利用同樣的結構。我們看幾個應用。
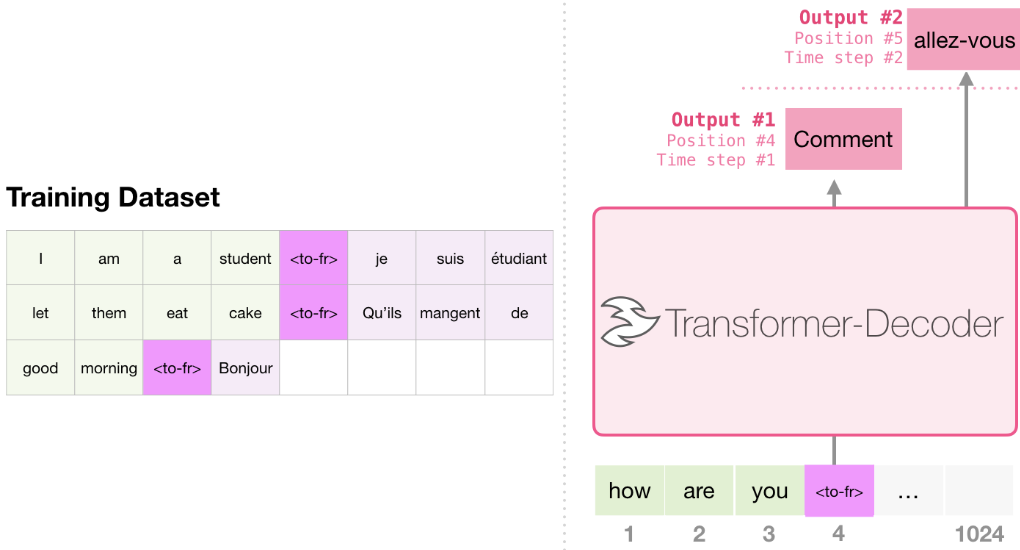
Machine Translation
和傳統的認知不同,事實上不需要 encoder 就可以完成 translation. 以下顯示 decoder-only transformer for translation:
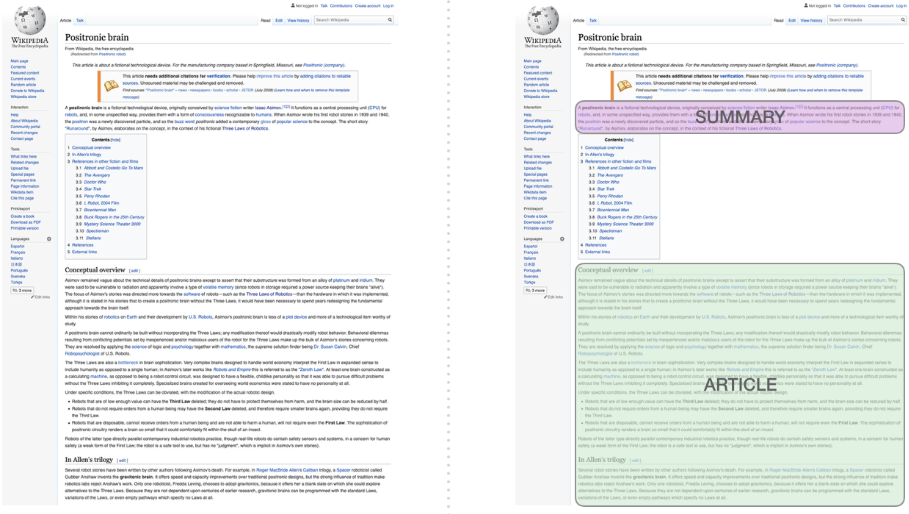
Summarization
事實上這是 decoder-only transformer 用來訓練的工作。Input 是 Wikipedia article (不含 table of contents 前的内容) 產生 summary. Wikipedia 的 summary 就是 training dataset 的 labels.
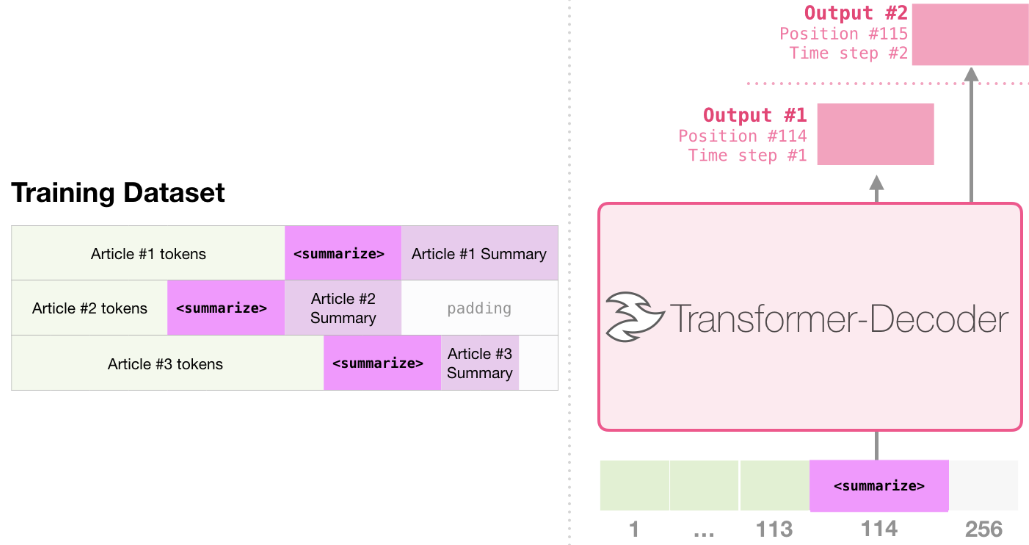
Transfer Learning
在 Sample Efficient Text Summarization Using a Single Pre-Trained Transformer paper 中,decoder-only transformer 先用語言模型 (SSL) pre-train, 在用 summarization 做微調 (fine-tune). 結果比 pre-trained encoder-decoder transformer 在有限的 data setting 結果好。
Music Generation
The Music Transformer 也還是用 decoder-only transformer 產生音樂可以表現 timing and dynamics. “音樂建模” 和 “語言建模” 基本原理相似。只要讓 model 本身用 SSL 學習音樂,最後取樣輸出。一般稱爲 “rambling”.
您可能很好奇在這種情況下如何表示音樂。請記住,語言建模可以通過作為單詞一部分的字元、單詞或標記的向量表示來完成。對於音樂表演(現在讓我們考慮鋼琴),我們必須代表音符,但也要表示速度(力度?)——衡量鋼琴鍵的力度。
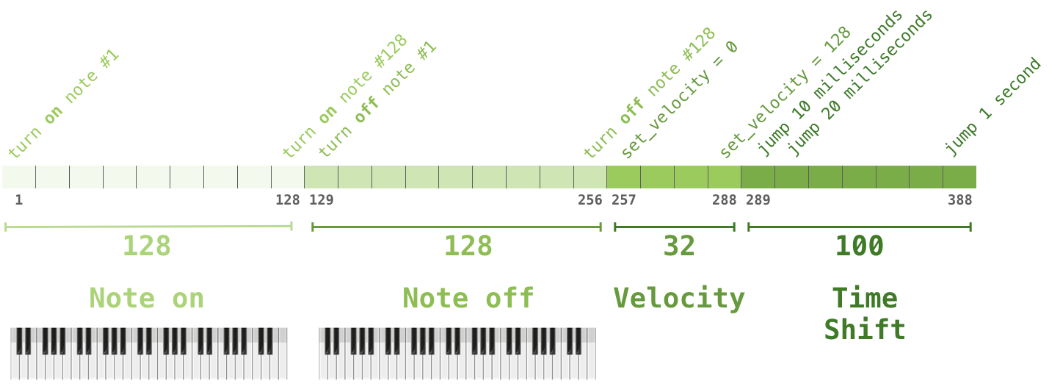
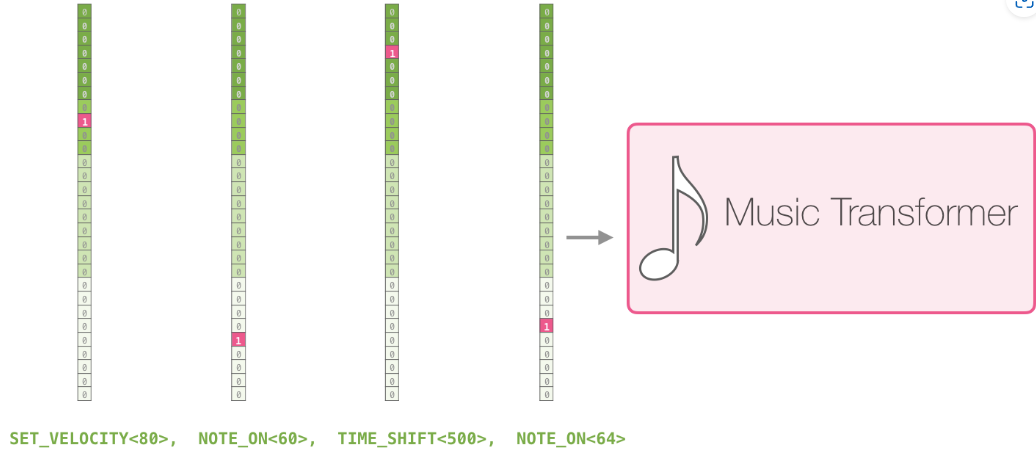
音樂演奏即使一連串的 one-hot vectors。MIDI 檔可以轉換為這樣的格式。本文具有以下範例輸入序列:

這些 one-hot vector 看起來如下:
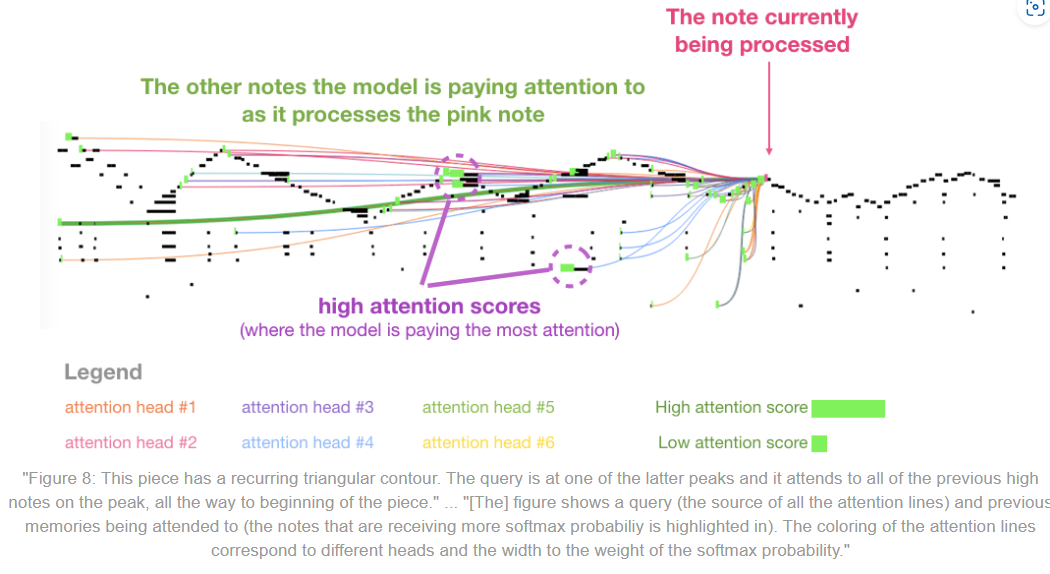
我喜歡在紙上展示 self-attention 在 music transformer 的視覺效果。我在這裡添加了一些註釋:
結論
到此結束了我們進入 GPT2 的旅程,以及我們對它的原始模型(decoder-onlyh transformer)的探索。希望從這篇文章中對 self-attention 有更好的理解,並且更瞭解 transformer 內部發生的事情。
Resource
- The GPT2 Implementation from OpenAI
- Check out the pytorch-transformers library from Hugging Face in addition to GPT2, it implements BERT, Transformer-XL, XLNet and other cutting-edge transformer models.