Reference
https://zhuanlan.zhihu.com/p/601044938
Github of Karpathy
Introduction
前文提到 GPT network. 本文用實際的 code example 來說明。我們用 Karpathy 的 nanoGPT 為例。
Karpathy 是 OpenAI 的 cofounder (2015-2017), 前 Tesla AI 總監 (2017 - 2023),李飛飛高徒。2023/1 發佈的NanoGPT,是他2年前 MiniGPT 的升級版。2023/2 Karpathy 再度加入 OpenAI.
據作者介紹,代碼簡單易讀,2個僅300行代碼的檔案。
現已基于OpenWebText重現 GPT-2 (124M),在單個8XA100 40GB節點上,訓練時間為38小時。
OpenAI GPT2 checkpoint 可以得到 GPT baselines 如下 (using OpenWebText dataset):
| Model | Params | Train loss | Val Loss |
|---|---|---|---|
| GPT2 | 124M | 3.11 | 3.12 |
| GPT2-medium | 350M | 2.85 | 2.84 |
| GPT2-large | 774M | 2.66 | 2.67 |
| GPT2-xl | 1558M | 2.56 | 2.54 |
| NanoGPT | 10.65M | 1.21 莎士比亞 data |
1.22 莎士比亞 data |
| NanoGTP | ? | 3.11 2.85 w/ finetune finetuneOpenWebText |
3.11 2.85 w/ finetune finetuneOpenWebText |
NanoGPT
發佈檔案裡面包含一個約300行的GPT模型定義(檔案名:model.py),可以選擇從OpenAI加載GPT-2權重。
還有一個訓練模型PyTorch樣板(檔案名:train.py),同樣也是300多行。
作者補充道,代碼並不難,很容易就能滿足大家需求——無論是從頭開始訓練新模型,還是基于預訓練進行微調(目前可用的最大模型為1.3B參數的GPT-2)。
Training
Karpathy 提供 quick start for training the model.
Shakespear Datasets
Default 使用 bfloat16 and pytorch2.0. 我的 GTX-1080 GPU (8GB) 和 driver 不支持 bfloat16 和 CUDAx 所以改成 float32 和 pytorch2 = False.
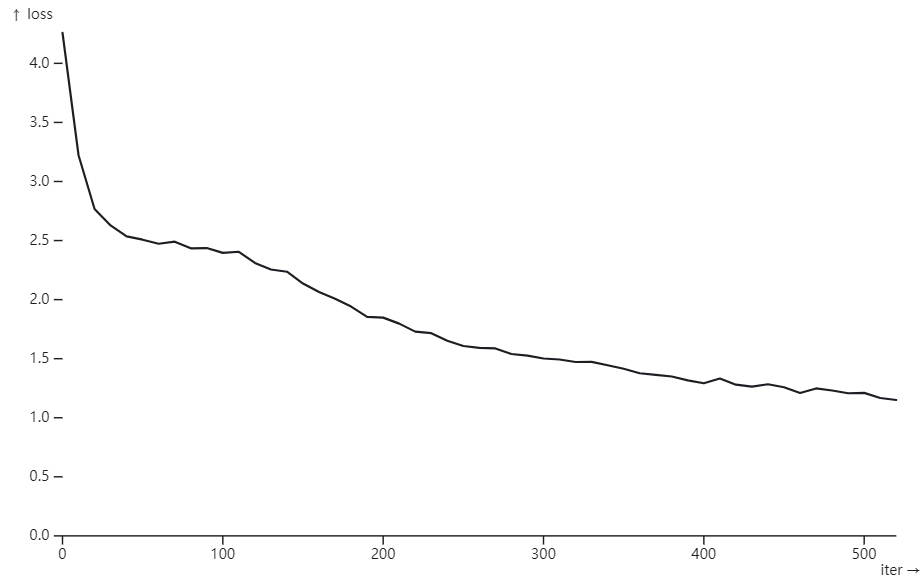
在 train 3 個小時后 : step 500, val loss: 1.4640
iter 490: loss 1.2073, time 17068.56ms, mfu 0.85% step 500: train loss 1.0899, val loss 1.4640
Karpathy 使用 A100 GPU (40GB) 只用了 3min (60X) 就得到 validation loss: 1.4697.
- BF16 比 FP32 理論上快了 2X.
- Pytorch 2.0 比 Pytorch 1.13 快了 1.5X?
- A100 比 GTX-1080 快了 20X??
使用 Simon Willison 的 “Plot loss from nanoGPT” Plot loss from nanoGPT / Simon Willison Observable (observablehq.com)
Appendix
Appendix A: Model.py
我們先 review GPT 作為 transformer decoder 的 block diagram.

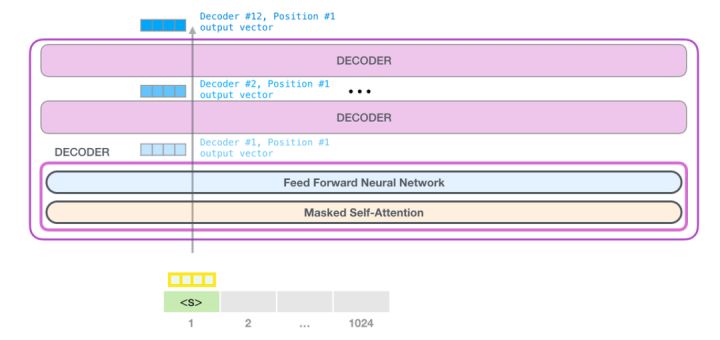
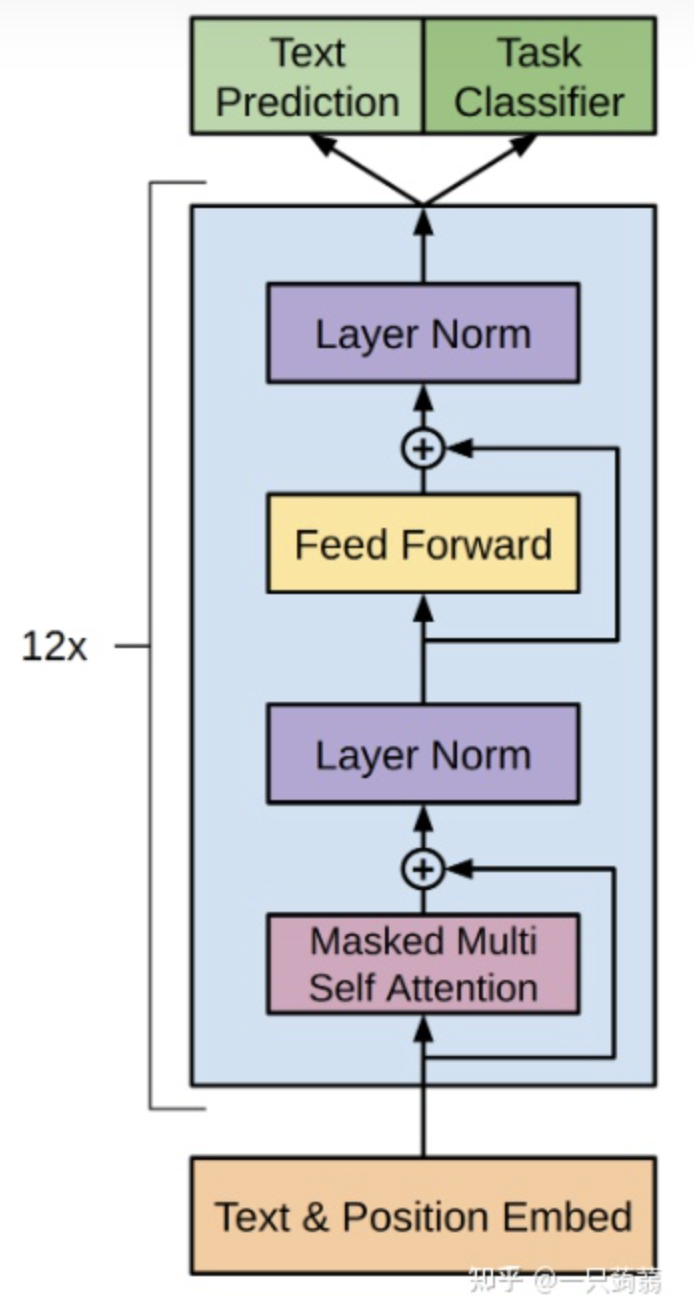
比較詳細的 block diagram:
- 12 個 stacking decoders
- 每個 decoder 包含 masked multi-head self attention + layer norm + feed forward + layer norm.
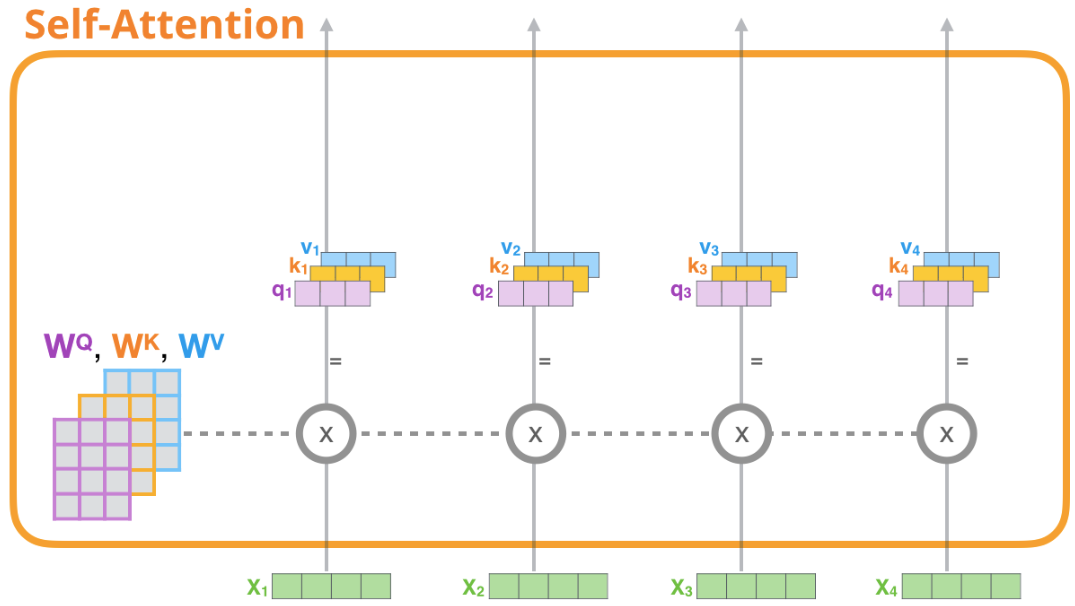
Self Attention Layer
這一部分就是圖中Masked Multi Self Attention的實現,也是transformer中的核心機制。
這裡的multi-head採用的是把Q,K,V切分成n_head份來實現的。
比較有趣的是mask的部分,tril是得到一個矩陣的下三角矩陣,把一個全1的矩陣放進去就可以得到mask矩陣。而register_buffer可以將一個張量註冊為一個buffer。這意味著這個張量不會被計算梯度,也不會對模型的參數進行更新,可以節省內存,提高計算效率。
1 | |
Feed-Forward Layer
Feed Forward的部分,這裡用到了gelu,似乎是一種類似relu但是更強一些的激活函數。
1 | |
一個transformer decoder block的實現,即圖上被藍色包圍的部分
值得一提的是,這裡的實現和圖上有一定區別,圖上是Attention->Layer Norm->Feed Forward->Layer Norm的順序,而這裡實現的是LayerNorm->Attention->LayerNorm->Feed Forward的順序。
這個Block的輸入的shape和輸出的shape都是(batch_size, suquence_length, embedding_dimensionality)
1 | |
下面就是GPT模型實現的部分
__init__部分中實現了input和output的embedding的參數共享。
具體來說,wte (text embeddings) 的weight是一個大小為(vocab_size, embedding_size)大小的矩陣,而Linear層 (y = x AT + b) 的weight就是A矩陣,為了實現dimension從in_feature到out_feature的轉換,A矩陣的形狀需要是(out_feature, in_feature),剛好就是shape為(vocab_size, embedding_size)的一個矩陣,所以這裡直接賦值,就是淺拷貝,實現了參數共享。
1 | |
接下來就是GPT class的forward函數,target表示目標輸出的label,根據有沒有傳進來決定要不要計算loss。
x[:, [-1], :]和x[:,-1,:]的區別就是後者會只剩下兩個維度,不保留第二維,但是前者會保留第二維,大小為1。
1 | |
下面是generate的實現,生成max_new_tokens長度的文本。
temperature是預測概率的一個超參,通常來說高溫度會使得模型預測的概率分佈更加平均,更加不確定,低溫度會使得模型預測的概率分佈更加偏斜,更加確定。 將 logits[:,-1,:] 除以 temperature 的作用就是將預測概率分佈降溫,使得預測更加不確定,可以生成更加多樣的文本。這個操作可以看成對模型預測的結果加上一些雜訊, 增加生成文本的多樣性。
1 | |
下面是from_pretrained的代碼,從huggingface的GPT模型中加載weight。
這裡比較有意思的是對一個tensor進行copy_的操作也會被記錄在計算圖上,因此需要使用with torch.no_grad()
1 | |
下面的代碼用來配置並返回optimizer,指定在一些權重上衰減或者不衰減。
權重衰減(weight decay)是一種正則化技巧,主要用於防止過擬合。在訓練過程中,權重衰減會使得模型的權重變得更小,從而減少模型的複雜度。
在這個代碼中,作者將模型中的參數分為兩組,一組是需要權重衰減的參數,另一組是不需要權重衰減的參數。參數的分組依據是:
- 偏置項(bias)參數不需要權重衰減,因為偏置項不參與計算,而且往往很小,所以不需要權重衰減來降低其複雜度。
- 層歸一化(LayerNorm)權重參數也不需要權重衰減,因為它的作用是對輸入數據進行標準化,不會對模型的複雜度產生影響。
- 嵌入(Embedding)參數也不需要權重衰減,因為權重衰減可能會抹除詞向量之間的關係,從而降低模型的性能。
- 其它權重參數需要權重衰減。
1 | |
下面的代碼是減少block size的,因為from pretrained的GPT預設block size為1024,這個函數可以減少block size,目前的block size只在self attention的mask矩陣bias,wpe中用到,所以只用改這幾個位置。
1 | |
Appendix B: Train.py
train.py沒有明顯的模組,我按照功能把代碼聚集到一起來寫。
下面這一塊是log相關的部分,代碼中用到的工具是wandb,一個類似tensorboard的可視化工具,使用的方法就是用init初始化project,把需要記錄的log用log的函數記錄。
1 | |
這一部分是分散式訓練的相關代碼,用到了DDP來實現
STEP 1:這裡用到了RANK和LOCAL_RANK這兩個環境變數,在DDP中,會給多進程中的每個進程分配獨特的rank和local rank值。rank表示當前進程在分散式集群中的進程編號(就是說不是系統的pid,而是對當前這個程序的所有進程編號),而local_rank表示當前進程在當前機器上的編號。(這裡提一下環境變數,每個進程有自己獨立的環境變數,在創建的時候都繼承了全局環境變數和父進程環境變數)這樣設置rank和local rank的目的是為了讓每個進程能夠知道自己在分散式集群中的位置,方便在分散式訓練中進行通信和同步。
1 | |
STEP 2:把model放到DDP容器裡去
1 | |
STEP 3:在訓練的時候如果使用了ddp,現在model是一個container,裡面的module才是我們的模型
1 | |
STEP 4:在訓練中,只需要在最後一個微步中同步梯度。官方的做法是使用model.no_sync()上下文管理器,但是這段代碼直接設置了model.require_backward_grad_sync變數,當micro_step等於gradient_accumulation_steps-1時,需要同步梯度。
if ddp:
model.require_backward_grad_sync = (micro_step == gradient_accumulation_steps - 1)
STEP 5:最後,調用了destroy_process_group()來銷毀進程組
if ddp:
destroy_process_group()
除此之外,如果是當前的process是master_process,還需要執行創建output dir,初始化wandb,記錄log,計算loss,保存checkpoint。
下面這些是混合精度計算的部分。
nullcontext() 是 PyTorch 的一個函數,用於在 CPU 上運行程序時返回一個空的上下文。這樣做的目的是為了避免在 CPU 上使用 autocast 函數導致的額外計算負擔。
torch.amp.autocast 函數是 PyTorch 的一個自動混合精度計算函數。它可以在運行時自動地切換數據類型,以便在需要時使用高精度,並在不需要時使用低精度。這可以提高程序的運行效率。
1 | |
下面是初始化模型的部分
1 | |
之後是對模型進行編譯,compile是PyTorch 2.0中新增加的一個功能,它可以將模型編譯成一種新的形式,以提高運行速度。
1 | |
下面這段代碼實現學習率的變化
餘弦衰減是一種學習率調整策略,它的基本思路是在訓練的開始階段使用較大的學習率,然後在訓練的後期降低學習率。具體來說,它在訓練過程中會將學習率按照一個餘弦函數進行衰減,在訓練開始時學習率較大,在訓練後期逐漸降低到最小值。這樣做的好處是能夠在訓練開始時較快地接近最優解,並且在後期能夠防止過擬合。
1 | |
接下來是訓練的過程
1 | |