Reference
Cohere 在 natural language processing 出了幾篇介紹的文章都非常有幫助。
[@serranoWhatAre2023] : excellent introduction of embedding
[@serranoWhatSemantic2023] : excellent introduction of semantic search
Introduction
NLP 最有影響力的幾個觀念包含 embedding, attention (query, key, value). 之後也被其他領域使用。例如 computer vision, ….
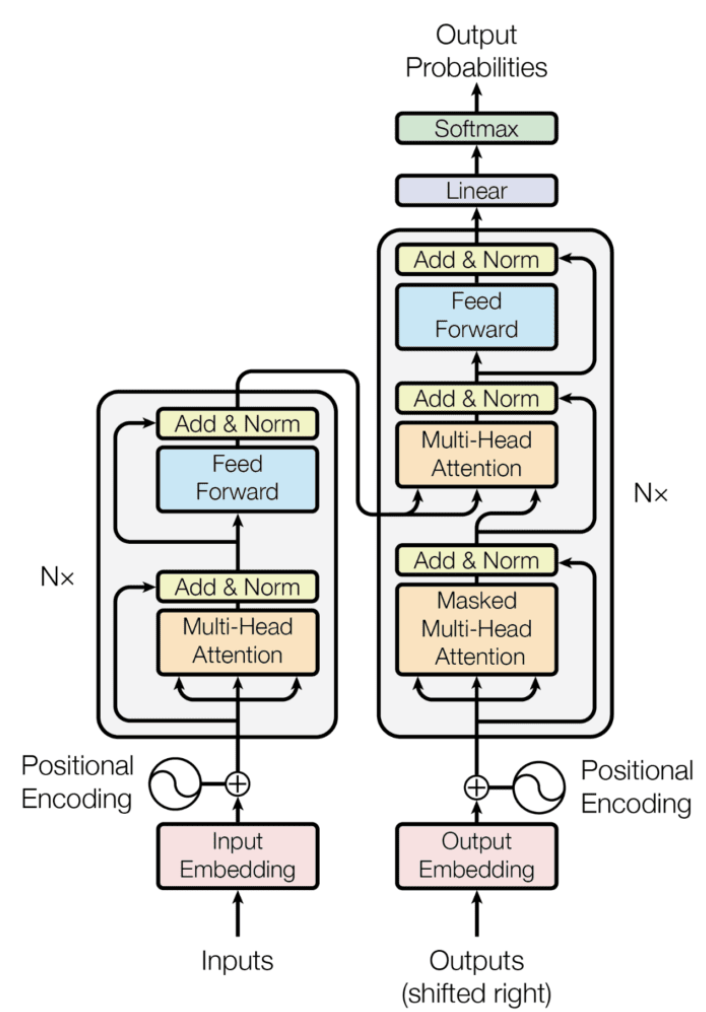
Embedding 並非 transformer 開始。最早是 starting from word2vec paper.
QKV: query, key, value 這似乎最早是從 database 或是 recommendation system 而來。從 transformer paper 開始聲名大噪,廣汎用於 NLP, vision, voice, etc.
attention: 特別是 self-attention, 然後才是 cross-attention. 雖然在 RNN 已經有 attention 的觀念,但是到 transformer 才發揚光大。 RNN 其實已經有時序的 attention, 在加上 attention 似乎有點畫蛇添足。Transformer attention 是 spatial attention, 並且範圍更大。

Token and Embedding
Bit token
Byte token
Byte-pair embedding
Reduce the size of the embedding
Query, Key, and Value
The terms “query”, “key”, and “value” used in the attention mechanism have their origin in information retrieval and database management systems. The concept has been applied to Recommendation System and Transformer Model used in natural language processing.
在注意力機制中使用的查詢 (query)、鍵 (key) 和值 (value) 這些詞語,源自於資訊檢索 (information retrieval) 和數據庫管理系統 (database management system, e.g. SQL - Structured Query Language)。這個概念也被應用於自然語言處理中使用的推薦系統和Transformer模型中。
Information Retrieval and Database
In information retrieval, a “query” refers to the user’s request for information, while the “key” refers to the index used to retrieve relevant information from a database. The “value” is the actual information retrieved by the query using the key.
In natural language processing, the “query” can be seen as the input that the model receives, such as a sentence or a sequence of words. The “keys” and “values” are representations of the input used by the model to compute the attention scores. The “keys” can be seen as a set of learned representations of the input, while the “values” can be seen as the actual input features that are used to compute the output of the model.
In the attention mechanism, the “query” is used to compute the relevance of each “key” with respect to the input, and the “values” are used to compute the weighted sum of the relevant “values”. This process allows the model to focus on the most relevant parts of the input when generating the output.
Recommendation System
In a recommendation system, “query” typically refers to the current user or their current behavior, while “key” and “value” refer to the items in the system that the user might be interested in.
The idea is that the recommendation system uses the user’s behavior (query) to search for items in the system that match or are similar to the user’s interests (key), and then returns those items (value) as recommendations.
This is often done using techniques like collaborative filtering, content-based filtering, or a combination of both.
One example of a paper that discusses the use of “query”, “key”, and “value” in recommendation systems is “Collaborative Filtering for Implicit Feedback Datasets” by Yifan Hu, Yehuda Koren, and Chris Volinsky, which was published in the Proceedings of the 2008 Eighth IEEE International Conference on Data Mining.
Attention Mechanism in Transformer Model
The use of the terms “query”, “key”, and “value” in the context of attention mechanism originated from the seminal paper “Attention is All You Need” by Vaswani et al. (2017), which introduced the Transformer architecture. In this architecture, the attention mechanism is used to compute the contextual representation of each input element by attending to all other elements in the sequence.
In the Transformer, the attention mechanism is formulated as a mapping from a set of queries, represented by a sequence of vectors, to a set of values, represented by another sequence of vectors. The keys are also represented by a sequence of vectors, which are used to compute the attention weights between the queries and values. Specifically, the attention weights are computed by taking the dot product between the queries and keys, and then applying a softmax function to obtain a probability distribution over the values. The resulting attention weights are then used to compute the weighted sum of the values, which gives the contextual representation of each query.
The use of the terms “query”, “key”, and “value” in the attention mechanism reflects their respective roles in this process: the queries are the vectors that are being attended to, the keys are used to compute the attention weights, and the values are the vectors that are being attended over. This formulation has since become a standard way of describing attention mechanisms, and has been applied in a variety of neural network architectures for natural language processing, computer vision, and other domains.
QKV 直觀意義和對應的數學:
直觀的有意義在前,對應的數學在冒號後。
-
(Character, Word, Sentence level, C/W/S) Embedding attention: scaled dot-product similarity, or cosine similarity
-
Attention weight: softmax
- (C/W/S) Embedding similarity: Weighed sum of attention
- Multi-level (C/W/S) and multiple (word ambiguity) embeddings similarity: Mutli-head attention learning
- False correlation: Negative samples/embedding
Vector Based QKV
-
(Character, Word, Sentence level, C/W/S) Embedding attention: scaled dot-product similarity,
-
Attention weight: softmax
-
(C/W/S) Embedding similarity: Weighed sum of attention
-
Multi-level (C/W/S) and multiple (word ambiguity) embeddings similarity: Mutli-head attention learning
QKV 其他的數學模式?
Manifold
前面的 vector QKV 可以視爲歐式空間。Manifold 可以想象就是非歐 (曲率) 空間。另一種類似的手法就是 kernel space.
對我而言,
- Manifold 是 local 近似歐式空間,但是 global 是曲率空間
- Kernel 是 local 曲率空間,global 類似歐式空間
- 當然兩者可以合在一起變成 local and global 都是曲率空間
然而歐式空間的計算非常友好,例如 matrix, dot-product 都有快速平行的運算。只有高維度的 softmax 計算比較麻煩一點。
曲率空間連算個距離都非常複雜。除非有特別的好處。不然把計算推到曲率空間只是自找麻煩。
假如曲率空間可以用比較低維度的計算,也許值得探索。
不過老實說,目前我看到的曲率空間用於 machine learning, 多半是理論階段。例如 information geometry. 數學, notation 上很精簡漂亮,但是離實用有一大段的距離。光看愛因斯坦的廣義相對論就知道,即使簡單的 boundary condition 的 manifold 都非常複雜。
Graph
Graph 從一個角度可以視爲更原始的幾何或是拓撲。乾脆用 connection 取代 metric. 當然我們還是可以在 connection 加上距離提供一些 metric information. 不過 graph 一般是非常 nonlinear.
如果 manifold 都有困難,使用 graph 豈不是更難? 而且好處在哪裏?
可能的好處
- text or language 的 embedding 好像用 graphic 描述更自然?或是更 compact?
- graphic 的數學可能完全不同,例如 random traverse, diffusion. 從 graph 也許更有物理意義?
這套 matrix 乘法 -> softmax -> linear combination .. 是否有類似的應用和數學 frame work?
應用: information retrieval, database management, recommendation system
數學 frame work: Graph?
- Embedding 不是向量,而是 nodes of graphs?
- Attention/Similarity 是用 neighborhood connection (or diffusion distance)
- Multi-level similarity : clustering?
Token and Embedding
Token 和 embedding 基本是 embedding 的 input 和 output 的關係。不過還是有差異。
Token 一般是 characters, words.
Embedding 則是 vector, 對應 words, sentences.
Q1: Token 和 embedding 是一一對應嗎? 好像只有在 words 可以一一對應。或是類似一一對應,e.g., beautiful and beautifully.
Q2: 如果 token 是 character, 顯然不是每一個 token 對應一個 embedding. 因為只有 26 個 embedding! 例如 beautiful 顯然不會和 “b”. 應該是一組 token (256, 512, 1024) tokens 對應 一個? (Vector length = 1024) 的 Embedding? 還是多對多?
這樣的顆粒好像又太粗?
Q3 最常見的似乎是 token 是 word, embedding 是 256/512/1024 tokens (sentence) 對應一個 embedding? 中間可以用
Word Embeddings Capture Features of the Word
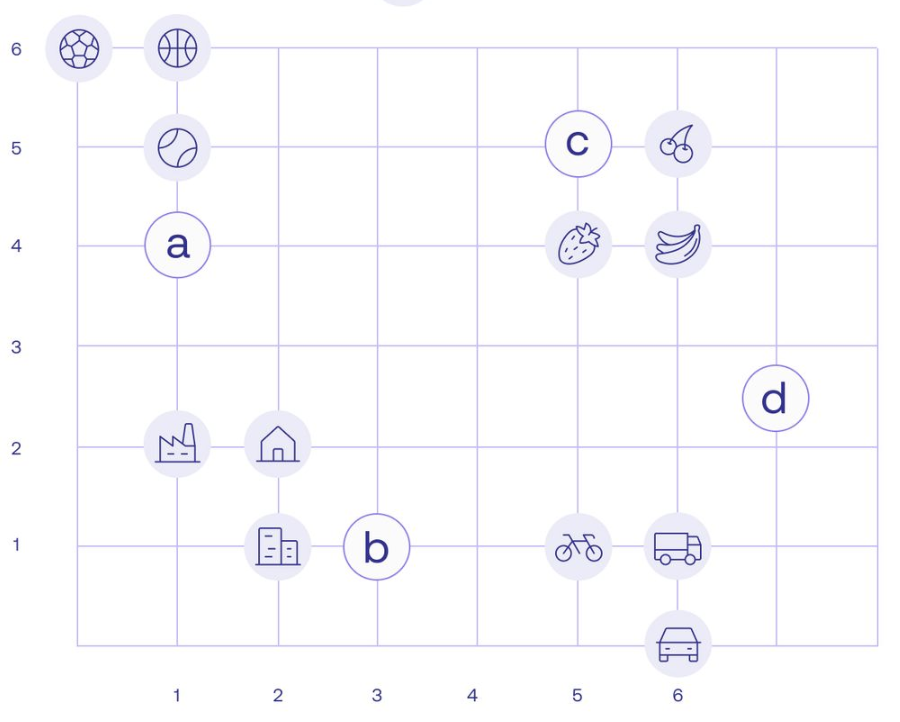
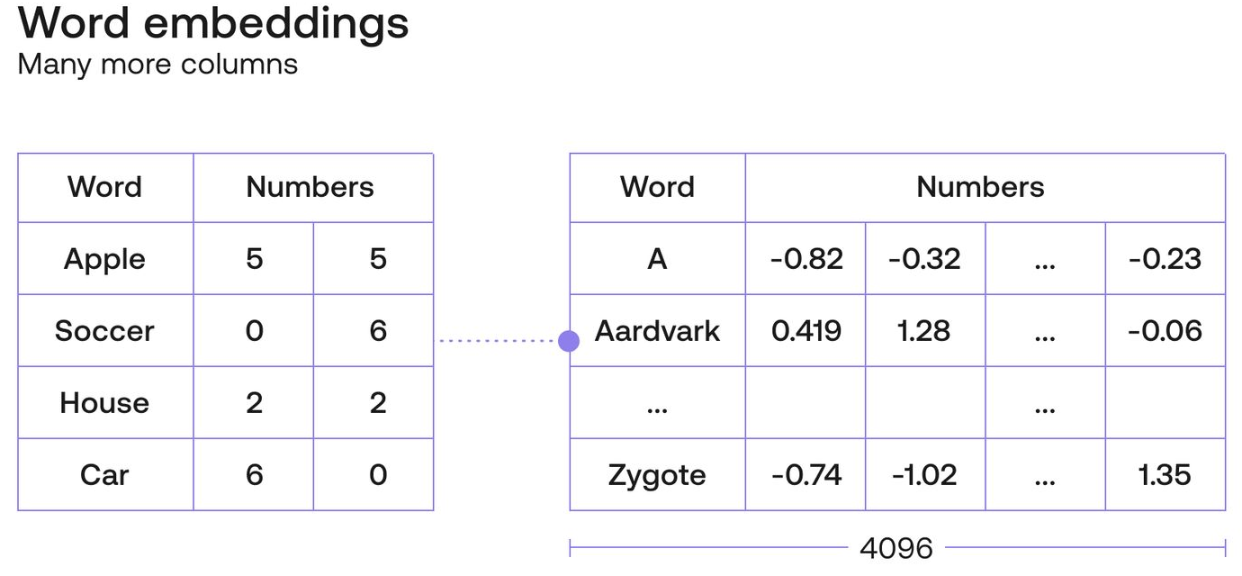
從簡單的 2D 例子延伸到 4096D 的 vector.
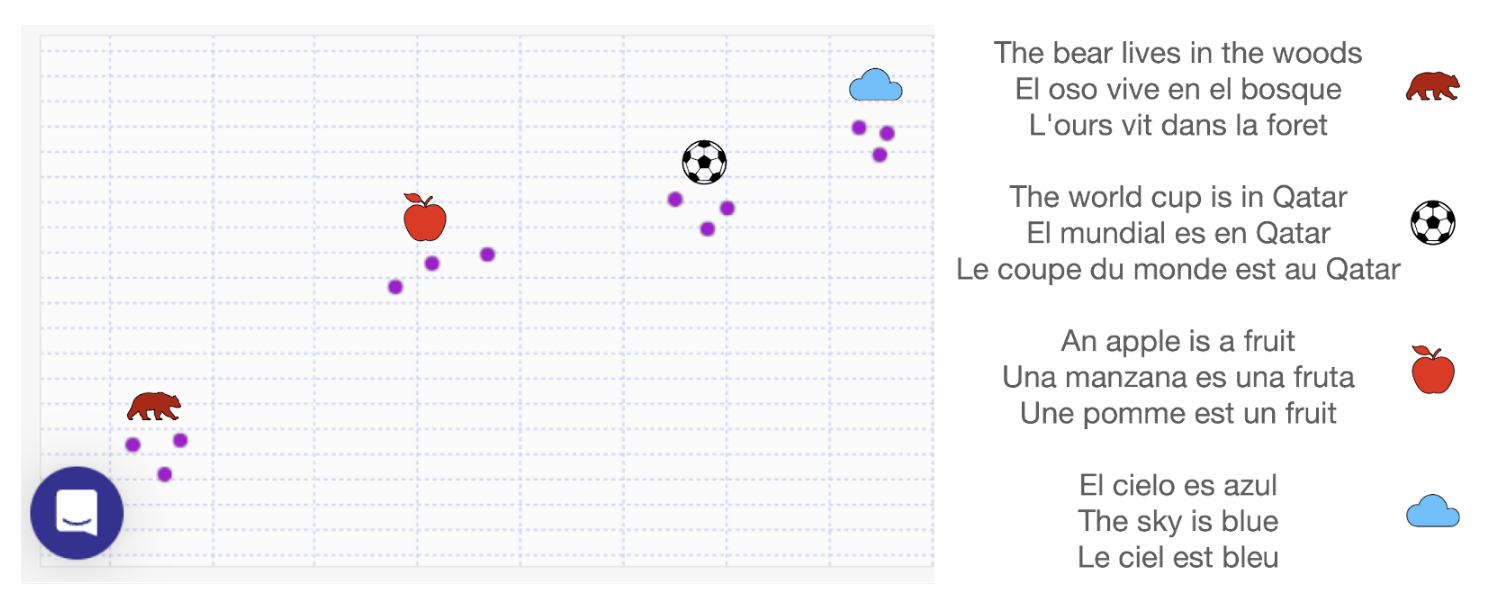
Sentence Embeddings
So word embeddings seem to be pretty useful, but in reality, human language is much more complicated than simply a bunch of words put together.
This is where sentence embeddings come into play. A sentence embedding is just like a word embedding, except it associates every sentence with a vector full of numbers, in a coherent way.
The Cohere embedding does just this. Using transformers, attention mechanisms, and other cutting edge algorithms, this embedding sends every sentence to a vector formed by 4096 numbers, and this embedding works really well.

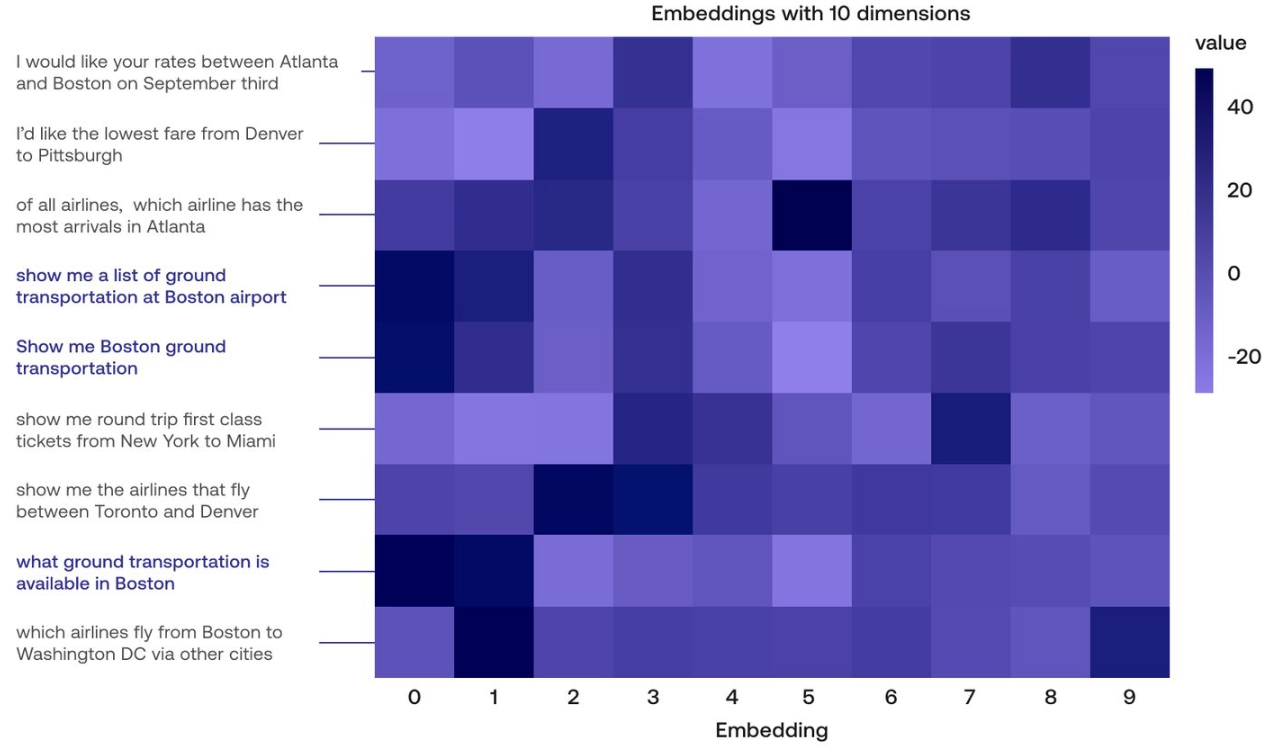
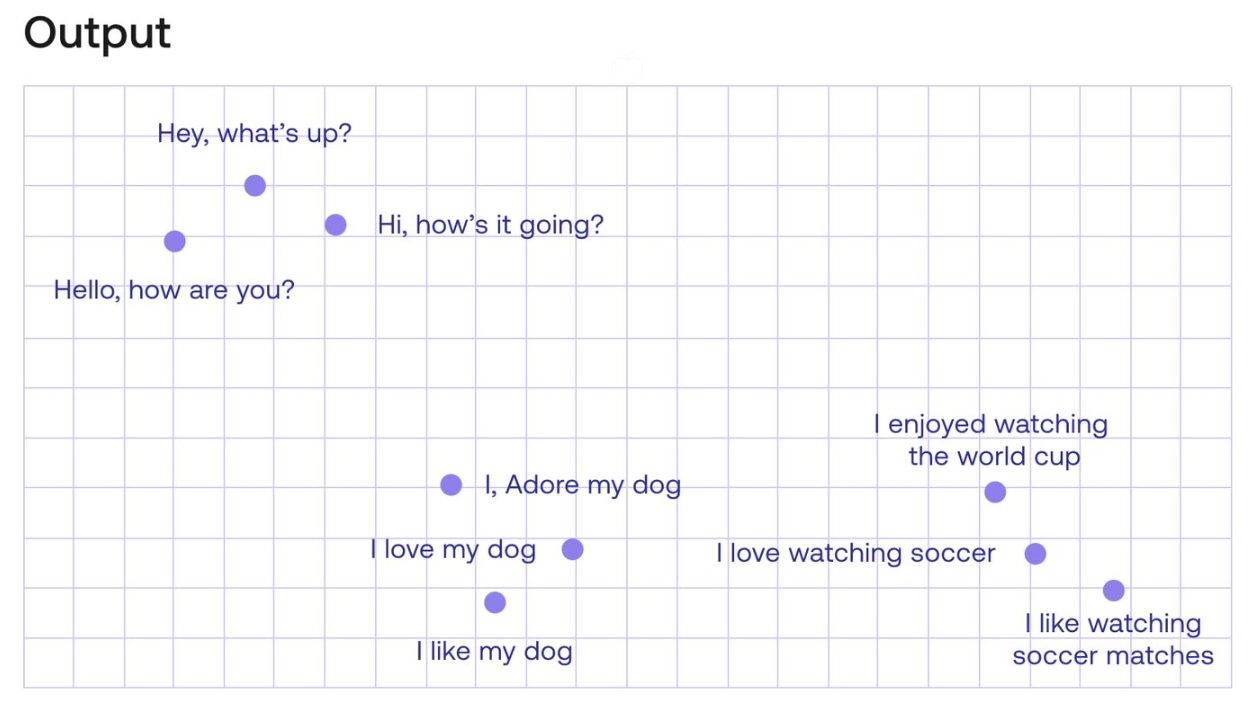
Multilingual Sentence Embeddings
Sentence embedding 似乎對 multilingual 更有意義。因為 character 最少共同意義 (例如中文和英文完全不同),words 比較有共同性 (Apple 和蘋果)。但是在 sentence level 基本是共同的。
NLP Sematic Search and Classification Task
| Computer Vision | Voice | NLP | |
|---|---|---|---|
| Classification | dog, cat, very mature | sound scene | sentiment analysis, Q & A |
| Detection | bounding box | special sound, instrument | Q & A with start/end index |
| Recognition | Face recognition | Voice ID | Author ID? |
| Speech recognition | Figure caption? (img to text) | ASR (voice to text) | Translation? (text to text) or summary? |
| De-noise | De-noise | De-noise | Fill in empty |
| Super resolution | SR | SR | x (somewhat GAI) |
| MEMC | Inpainting, insert sequence | make voice more clear | x (somewhat GAI) |
| Chat | text to image | text to music/speech | Dialog, or generative AI (text-to text) |
Reference
Serrano, Luis. “What Are Word and Sentence Embeddings?” Context by Cohere. January 18, 2023.
https://txt.cohere.ai/sentence-word-embeddings/.
———. “What Is Semantic Search?” Context by Cohere. February 27, 2023.