Reference
[@heUnifiedView2022] : unified view of fine tune (PEFT) very good paper based on Mu Li’s recommendation
Introduction
Generative AI = Foundation Model + Fine tune
Foundation model 一般是 pre-trained network 使用 self-supervised learning with unlabelled big data.
Fine tune 則是少量 labelled data 作 fine tuning.
不過魔鬼就在細節裏。雖然 foundation model 基本大同小異。但是 fine tune 則是各顯神通。
本文討論三類的 fine-tune technologies.
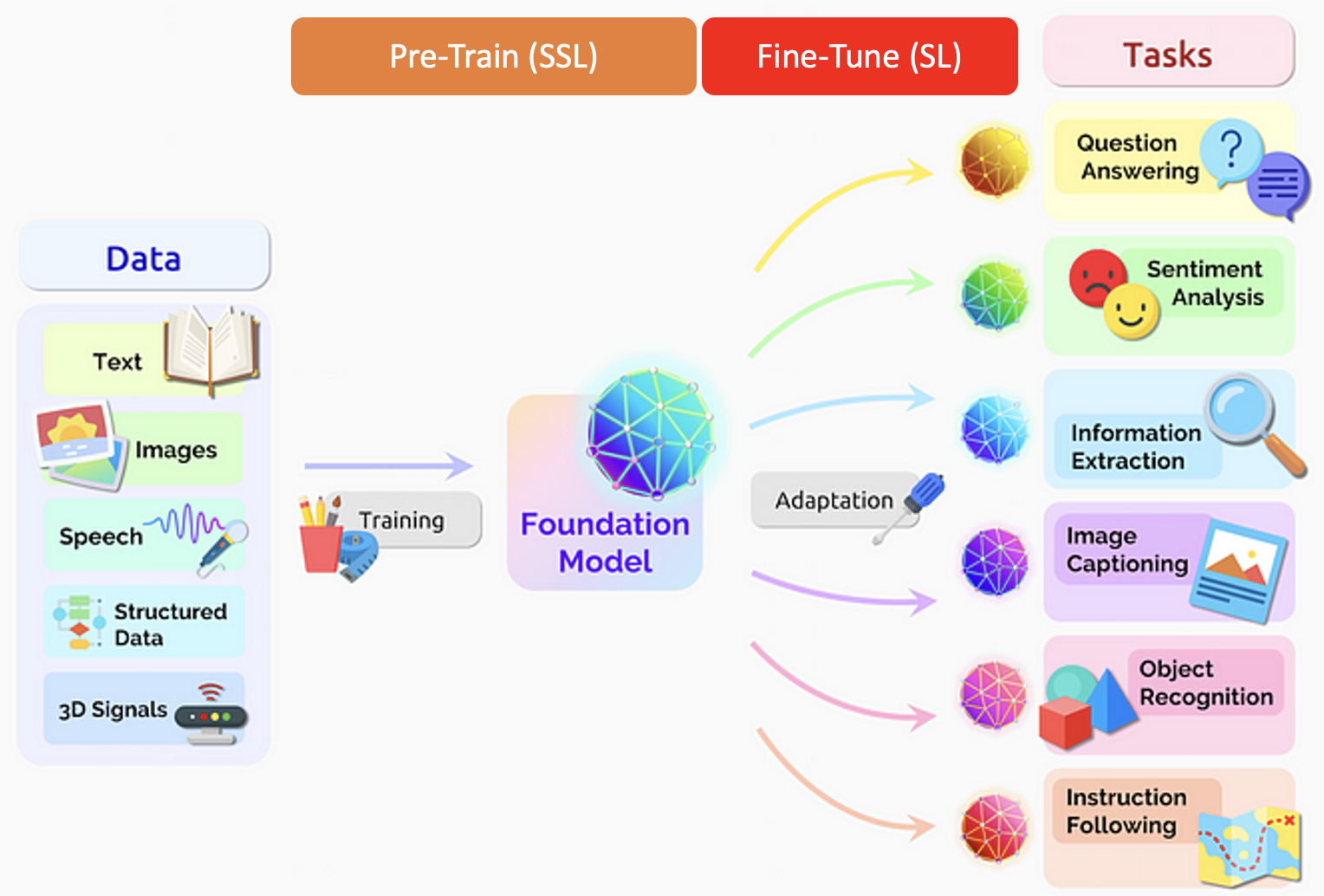
NLP 的 fine tuning 分為幾個 phases.
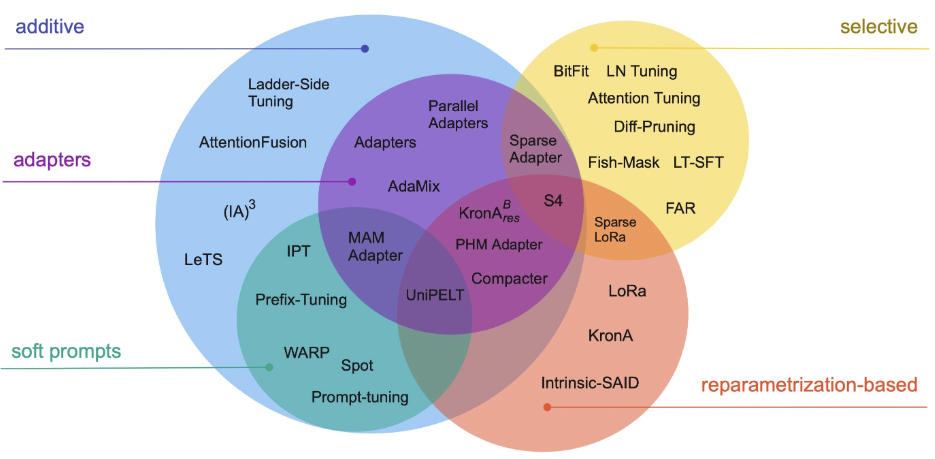
- Feature-based approach (additive)
- BERT (full fine tune): full fine tune 即是 duplicate 原來的 LLM model (非常大)。再用 pre-trained 的 weights 做為 initial values. Full fine tune 就是用少量的 label data for downstream tasks. 明顯的缺點:運算量和 memory 都非常大!
- Prompting:
- Adapter:
- LoRA (reparameter):
| Full fine tune | Prompt | Adapter | LoRA | |
|---|---|---|---|---|
| Model | BERT | GPT | GPT | GPT |
| Memory | 100% of orig network | 0% or very small | 10%? | 5%? |
| Computing | ||||
| Initial weight | Pre-train | Pre-train weight | Pre-train weight | Pre-train weight |
| Position | FF? |
Prompt是什麼
首先來看什麼是Prompt,沒有找到權威定義,引用一些論文中的描述來說明什麼是Prompt。
Users prepend a natural language task instruction and a few examples to the task input; then generate the output from the LM. This approach is known as in-context learning or prompting.
By: # Prefix-Tuning: Optimizing Continuous Prompts for Generation
簡單來說,用戶用一段任務描述和少量示例作為輸入,然後用語言模型生成輸出。這種方法就叫做in-context learning或prompting。Prompting也有另一種偏概率的解釋:
Prompting is the approach of adding extra information for the model to condition on during its generation of Y .
By: # The Power of Scale for Parameter-Efficient Prompt Tuning
舉個PET中的示例來說明什麼是Prompt,假設我們要對一句話Best pizza ever!進行情感分類,可以在這句話後面加上一句模板:
Best pizza ever! It was ___.
那麼基于前面這句話填空的結果,模型預測為great的概率要遠高於bad。因此我們可以通過構造合適的Prompt把情感分類問題變成完形填空問題,從而可以很好地利用預訓練模型本身的潛力。
關於Prompt為什麼好使,PET中有如下解釋:
This illustrates that solving a task from only a few examples becomes much easier when we also have a task description, i.e., a textual explanation that helps us understand what the task is about.
Pretrain-finetune與Prompt-tuning的主要區別在於前者通過finetune讓模型更好地適應下游任務,而後者則是通過設計Prompt來挖掘預訓練模型本身的潛能。
為什麼用Prompt
現在的NLP模型都很大,下游任務也繁多,finetune的範式就需要對每個任務都使用一個特定的模型拷貝。解決這個問題的直觀方案是輕量的finetune,即在finetune階段只調整少量的參數,而保持大多數參數不可訓練。
將這種做法做到極致就是Prompt,比如GPT3可以不經過finetune而完成多種下游任務。也就是說,Prompt是一種很好的Few-shot learning甚至Zero-shot learning的方法。
Prompt重在挖掘預訓練模型本身的潛力,甚至在某些情況下可以超越之前finetune的SOTA。
此外,因為Prompt對原模型的改動較小甚至不改,可以比較輕量地實現個性化而無需每用戶一個大模型,serving開銷顯著變小。
怎麼用Prompt
那下面的問題就在於,如何找到合適的Prompt?
此處將不同方案使用的模板列出,保持與原文一致的符號標記。
離散式模板
制定離散式Prompt的模板需要對模型本身有一定的理解,而且考慮到模型的不可解釋性,就需要對Prompt的模板進行不斷的試驗,所謂“有多少人工就有多少智能”。
這種離散型模板也叫做hard prompt。
PET
# Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
PET通過構造自然語言式的模板,將一些文本任務轉換成完形填空任務,比如第一節中的示例。
PET提供的模板花樣比較多,不同任務對應不同的人工設計模板,大概長這個樣子,其中a和b是輸入文本:
It was ___. a
a. All in all, it was ___.
a ( ___ ) b
[ Category: ___ ] a b
AutoPrompt
# AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
AutoPrompt本質上也是一種自然語言式的模板,但它的模板看起來通用性更強,分為三部分,原句,Trigger Tokens [T]和預測Token [P]。
{sentence} [T][T] . . [T] [P].
在標註數據集上,通過最大化預測準確率的方法自動搜索最優的Trigger Tokens [T]。此方法的直覺是,通過標註數據搜索與任務相關的模板關鍵詞知識 (auto knowledge probing)。並在之後通過這些尋找到的Trigger Token作為自動模板,將模型泛化。
連續向量模板
尋找像自然語言一樣的離散模板比較困難,於是有一些後續改進的工作。實際上,Prompt不一定是離散的,甚至不一定是自然語言,Prompt可以是一個embedding,可以通過訓練在連續向量空間中搜索得出。
這種連續型模板也叫做soft prompt。
Prefix-Tuning
# Prefix-Tuning: Optimizing Continuous Prompts for Generation
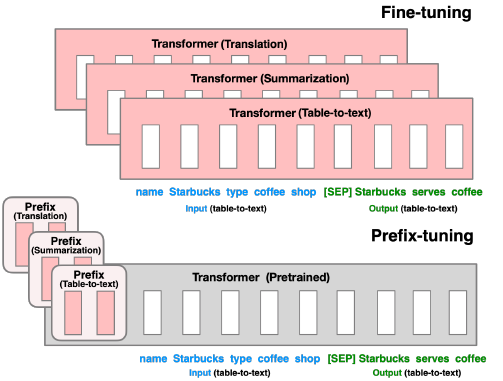
Prefix-Tuning固定了語言模型本身的參數,只在每層加入一個Prefix Vector,也就是一個Prefix Matrix,僅訓練這一小部分連續並任務相關的參數即可提升一些文本生成任務(NLG)的效果。把這些virtual token對應的向量看做prompt。Prefix-Tuning的模板形式:
Autoregressive Model: [T] x y
Encoder-Decoder Model: [T] x [T'] y
其中x是輸入的source,y是target。
同時,在實驗中也有一個關於表達力的比較,看起來連續的向量比離散的關鍵詞模板更富有表達力 (expressive):
discrete prompting < embedding-only ablation < prefix-tuning
P-Tuning
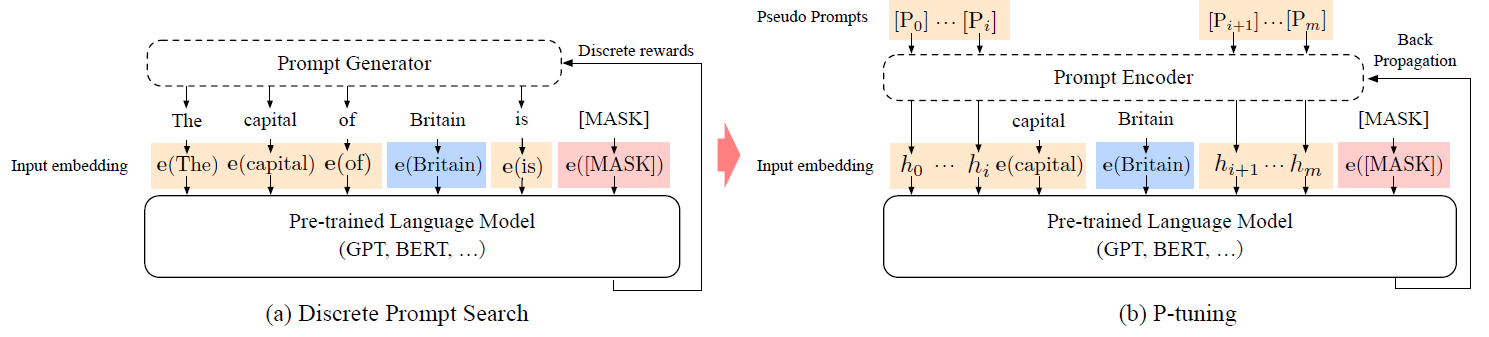
P-Tuning的思路其實與Prefix-Tuning非常類似,都是希望通過少量標註數據學習一個連續向量模板,主要區別在於P-Tuning更關注NLU。
To automatically search prompts in the continuous space to bridge the gap between GPTs and NLU applications.
即P-Tuning通過自動搜索Prompt,讓GPT這樣的autoregressive model很好地完成NLU的任務。具體地來看下P-Tuning的模板形式:
[h(0)]...[h(i)]; e(x); [h(i+1)]...[h(m)]; e(y)
其中,h(i)就是Prompt,e是embedding函數,x是sentence tokens,y是target。
還有個值得注意的點,Prefix-Tuning和P-Tuning在訓練搜索模板時都採用了reparametrize的方法,因為它們遇到了優化不穩定的問題:
Empirically, directly updating the P parameters leads to unstable optimization and a slight drop in performance.
By: Prefix-Tuning
In the P-tuning we propose to also model the h(i) as a sequence using a prompt encoder consists of a very lite neural network that can solve the discreteness and association problems.
By: P-Tuning
說句題外話,之前有許多關於BERT適合NLU而GPT適合NLG的說法和對應的解釋,這篇論文是否推翻了這些推斷? :-)
Prompt Tuning
# The Power of Scale for Parameter-Efficient Prompt Tuning
本文發表在EMNLP 2021,是對之前一些工作的總結和改進。與Prefix-Tuning的主要區別在於,前者對模型的每層都加入了prefix vector,而本文提出的方案,僅僅在輸入層這一層加入一些額外的embedding,因而更加parameter-efficient。雖然進行tuning的參數更少,但模型效果不錯,並且文中有一些有意思的insights:
如何初始化prompt vector?
Conceptually, our soft-prompt modulates the frozen network’s behavior in the same way as text preceding the input, so it follows that a word-like representation might serve as a good initialization spot.
從直觀上說,因為這種加prompt的方式類似於在輸入層添加一些token,因此將這些prompt vector初始化成詞表中的word embedding vector相比于隨機初始化是更好的做法。
prompt的長度選擇?
簡單來說,越短越好,越長訓練的成本越高。後面的實驗證明20就差不多,更長的prompt對性能提升效果有限。
The parameter cost of our method is EP, where E is the token embedding dimension and P is the prompt length. The shorter the prompt, the fewer new parameters must be tuned, so we aim to find a minimal length that still performs well.
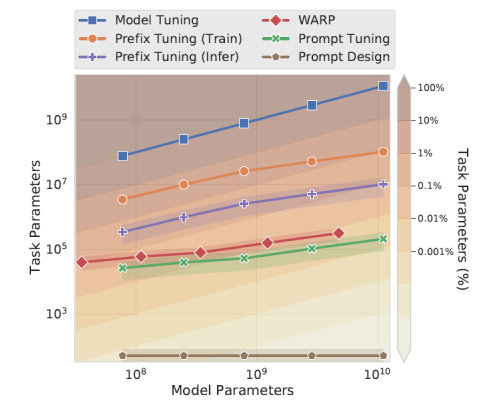
從上面模型參數數量對比來看,Prompt Tuning比Prefix Tuning更勝一籌,個人覺得本文最大的貢獻在於發現了只要初始化方法得當,僅在輸入層加入少量參數做prompt tuning就夠了。
本質上,連續prompt模板就是在原有LM上增加了少量參數,並通過小樣本僅學習這些參數調優取得更好性能的方法。 與直接添加參數相比,這些參數具有模板的形式(雖然不是自然語言形式),所以取得了更好的效果。
Adapter
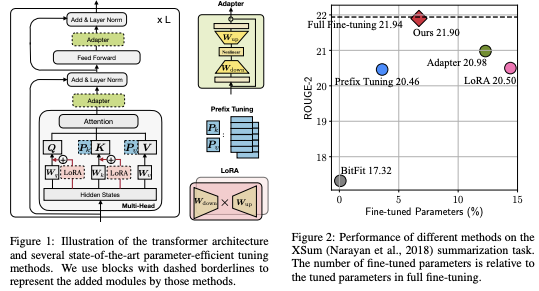
Adapters在NLP中的應用源於這篇 ICML2019 文章:Parameter-Efficient Transfer Learning for NLP adapters 。
Adapter-based tuning requires training two orders of magnitude fewer parameters to fine-tuning, while attaining similar performance.
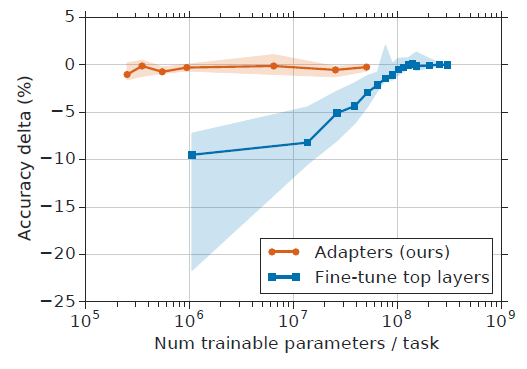
從上圖來看,Adapters可以在訓練小兩個量級參數的情況下達到與finetune基本一致的性能,這也是Adapter出現的主要動機。
Adapter 模組結構
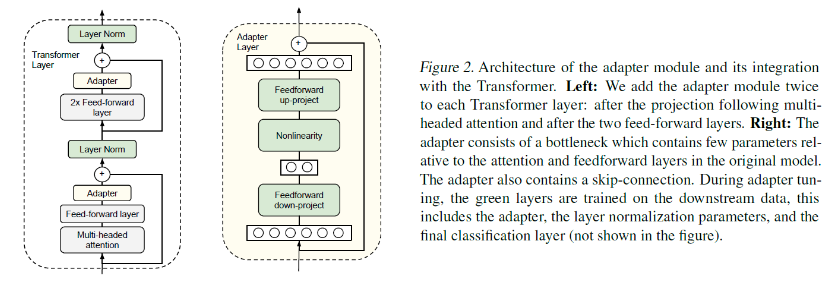
Adapter的結構並不複雜,僅在Transformer的結構上增加了兩個網絡層:
-
左圖解釋了如何將Adapter加入到Transformer結構中,即在Multi-headed Attention與Feed-forward模組之後,Layer Norm之前各加入一個Adapter層。
-
右圖解釋了加入的Adapter模組的內部結構:Feed-froward down-project + Nonlinearity + Feed-froward up-project,對進入Layer Norm之前的輸入進行了先先降維再升維,保持輸入輸出相同。
-
圖中綠色部分是待訓練的參數,可以看到包括了Layer Norm,原因在於加入Adapter結構之後, Layer Norm的輸入也發生了很大的變化,所以需要一併訓練。
Adapter模組為什麼也要引入殘差連接?
這裡給出瞭解釋:為了保證在模型初始化時的輸入輸出與原始模型一致。
The adapter module itself has a skip-connection internally. With the skip-connection, if the parameters of the projection layers are initialized to near-zero, the module is initialized to an approximate identity function.
Adapter引入的參數量?
新引入的參數量可以很容易計算,原始輸入維度為d,中間降維後的維度為m,則一個Adapter加上偏置後的總參數量:md + d + md + m = 2md + d + m。這裡m « d,因此每個任務引入的新參數量很少。實踐中,大概只引入原模型參數量的0.5 - 8%。
Adapter為什麼設計成這樣?
文章中沒有給出詳細的說明,從實驗部分來看,作者做了大量實驗來尋找parameter-efficient的模型架構。效果好就完了~
Adapter-Tuning與Prompt-Tuning的區別
Adapter是在Transformer中增加了額外的網絡層。對於連續型的Prompt,以Prefix-Tuning為例,是在Transformer的每層增加了額外的prefix vector,利用attention機制來發揮作用。用不太嚴謹的話來說,Adapter-Tuning像是縱向的參數擴展,而Prefix-tuning像是橫向的參數擴展。相對而言,Prompt-Tuning訓練的參數量更小。
源引Prefix-Tuning中的一段話:
Recall that prefix-tuning keeps the LM intact and uses the prefix and the pretrained attention blocks to affect the subsequent activations; adapter-tuning inserts trainable modules between LM layers, which directly add residual vectors to the activations.
LoRA: Low-Rank Adaptation
之前我們談到 Adapters 與 Prompting 都是輕量級的訓練方法,所謂 lightweight-finetuning。今天來看一下另一種輕量級訓練大語言模型的方法:
LoRA: Low-Rank Adaptation of Large Language Models 。
首先來看finetune大規模語言模型的問題:
An important paradigm of natural language processing consists of large-scale pretraining on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example – deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive.
已有方案的問題
為解決finetune大規模語言模型的問題,已有多種方案,比如部分finetune、adapters和prompting。但這些方法存在如下問題:
- Adapters引入額外的inference latency (由於增加了層數)
- Prefix-Tuning比較難於訓練
- 模型性能不如finetuning
Adapter引入Inference Latency
顯然,增加模型層數會增加inference的時長:
While one can reduce the overall latency by pruning layers or exploiting multi-task settings, there is no direct ways to bypass the extra compute in adapter layers.

從上圖可以看出,對於線上batch size為1,sequence length比較短的情況,inference latency的變化比例會更明顯。不過個人認為,絶對延遲的區別不大。 :-)
Prefix-Tuning難於訓練
與Prefix-Tuning的難於訓練相比,LoRA則更容易訓練:
We observe that prefix tuning is difficult to optimize and that its performance changes non-monotonically in trainable parameters, confirming similar observations in the original paper.
模型性能不如Full Finetuning
預留一些sequence做adaption會讓處理下游任務的可用sequence長度變少,一定程度上會影響模型性能:
More fundamentally, reserving a part of the sequence length for adaptation necessarily reduces the sequence length available to process a downstream task, which we suspect makes tuning the prompt less performant compared to other methods.
LoRA
先看看LoRA的motivation:
We take inspiration from Li et al. (2018a); Aghajanyan et al. (2020) which show that the learned over-parametrized models in fact reside on a low intrinsic dimension.
We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”, leading to our proposed Low-Rank Adaptation (LoRA) approach.
雖然模型的參數眾多,但其實模型主要依賴low intrinsic dimension,那adaption應該也依賴于此,所以提出了Low-Rank Adaptation (LoRA)。
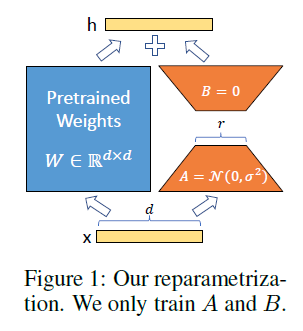
-
Initial 為 0, or mean = 0 所以不會干擾原來的 big model.
-
LoRA的思想也很簡單,在原始PLM旁邊增加一個旁路,做一個降維再升維的操作,來模擬所謂的
intrinsic rank。訓練的時候固定PLM的參數,只訓練降維矩陣A與升維矩陣B。而模型的輸入輸出維度不變,輸出時將BA與PLM的參數疊加。用隨機高斯分佈初始化A,用0矩陣初始化B,保證訓練的開始此旁路矩陣依然是0矩陣。具體來看,假設預訓練的矩陣為 $W_o \in {\R}^{d\times k}$ ,它的更新可表示為:
\[W_o + \Delta W = W_o + B A, \quad B \in {\R}^{d\times r}, A \in {\R}^{r\times k}\]其中 low rank: $r \ll \min(d,k)$
這種思想有點類似於殘差連接,同時使用這個旁路的更新來模擬full finetuning的過程。並且,full finetuning可以被看做是LoRA的特例(當r等於k時):
This means that when applying LoRA to all weight matrices and training all biases, we roughly recover the expressiveness of full fine-tuning by setting the LoRA rank r to the rank of the pre-trained weight matrices.
In other words, as we increase the number of trainable parameters, training LoRA roughly converges to training the original model, while adapter-based methods converges to an MLP and prefix-based methods to a model that cannot take long input sequences.
LoRA也幾乎未引入額外的inference latency,只需要計算 $W = W_o + BA$ 即可。
LoRA與Transformer的結合也很簡單,僅在QKV attention的計算中增加一個旁路,而不動MLP模組:
We limit our study to only adapting the attention weights for downstream tasks and freeze the MLP modules (so they are not trained in downstream tasks) both for simplicity and parameter-efficiency.
總結,基于大模型的內在低秩特性,增加旁路矩陣來模擬full finetuning,LoRA是個簡單有效的方案來達成lightweight finetuning的目的。