Foundation network: self-supervised learning
Fine-tune A: SFT (Supervised fine tuning)
RLHF: Reinforcement learning with human feedback.
Phase 1: Big Pre-trained foundation model using SSL (Self-Supervised Learning)
Phase 2: 少量 labelled data using Supervised Fine-Tuning
Fine tuning 是複製

另外 RLHF!!
第一部:Pre-trained Model
Introduction
NLP 最有影響力的幾個觀念包含 embedding, attention (query, key, value). 之後也被其他領域使用。例如 computer vision, ….
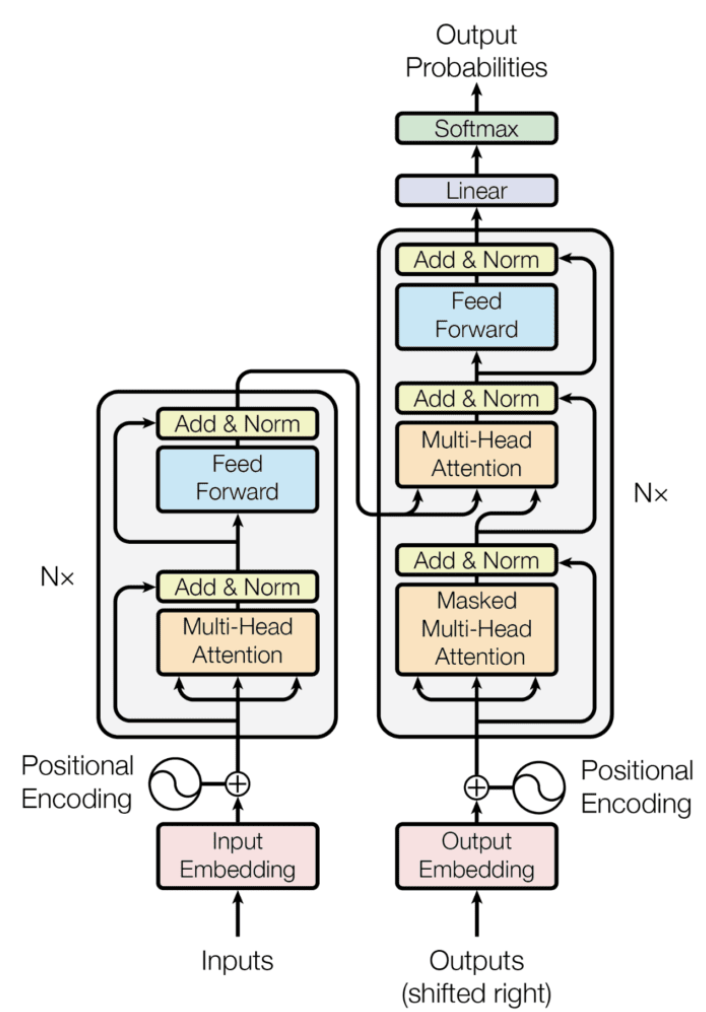
Embedding 並非 transformer 開始。最早是 starting from word2vec paper.
QKV: query, key, value 這似乎最早是從 database 或是 recommendation system 而來。從 transformer paper 開始聲名大噪,廣汎用於 NLP, vision, voice, etc.
Attention Flow and Interpretation
A. Linear Combination Interpretation
Step 1: Text to Token Embedding
- 1 個英文 word 大約對應 2 個 tokens. 這裡的 token embedding 基本是 (sub) word embedding, 而非 character 或是 sentence embedding.
- Token embedding 就是 vector. 每一個 token (sub-word) 都是一個 vector. 例如 GPT3 一次處理 512 tokens, vector 的 dimension 是 768. 也就是 token embeddings 是一個 512 x 768 的 matrix.

Step 2: 2nd token = attention weighted sum of “input token embedding”
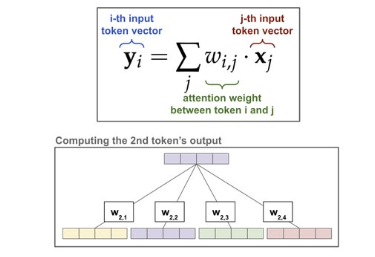
- Caveat: 事實上 input 不一定是 “input token embedding”. 一般更廣泛是用 value token. Value token 是 input token embedding 的 linear projection, 如下圖:
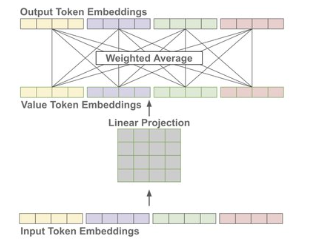
Step 3: 如何計算 attention weights?
-
產生 query token 和 key token. 兩者是相同 dimension.
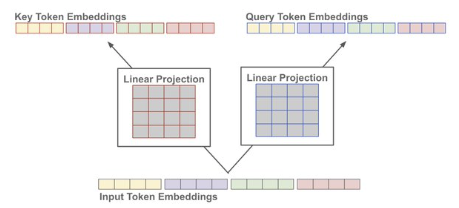
-
計算所有 query token 和 key token 的點積 similarity
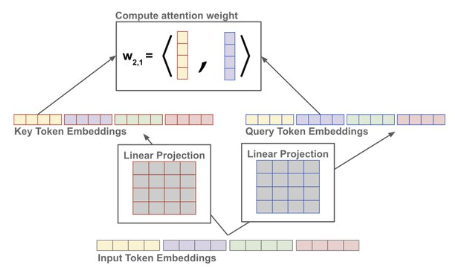
-
Normalized to [0-1] weights using softmax.
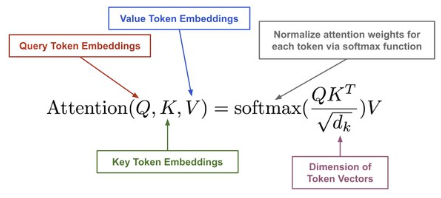
Question? 為什麼要 Q, K, V?
- Q, K 基本是一組。但是 V 可以分開提供更多的 flexibility. 例如 cross-attention 的 V 和 Q,K 是不同的 domain (例如Q/K 是英文, V 是法文)。
- Attention weights 都是計算,並沒有 learning!! 如何加上 learning? Multi-head attention!
Step 4: (Learnable) Feed-forward network
再做一個 feed-forward, 1 hidden layer with 4x parameters.
B: Matrix Multiplication Rationale (Good!)
先看不好的方法 for NLP
-
NLP 的問題是 input text string 一般是變動的,例如:“Hello, world”, 或是 “This is a test of natural language processing!”
- Input 是 text string, 切成 tokens ($\le$512). 儘量塞 sentence 或是 0 padding. 每個 token 是 768-dim (feature) vector. 也就是 (input) token embedding 是一個 arbitrary width ($\le$ 512) 2D matrix X. 最終希望做完 attention 運算還是得到同樣的 shape.
- Token size 不是固定 ($\le 512$) 有很多 implications:
- Need to use layer norm instead of group norm! 因爲不同 sample 的長度不同。
- 另外在 transformer for Computer vision 例如 ViT 應用:token length = 224x224/16x16 + 1 (CLS token) = 197!
- 如果 input-output 是 inter-token 和 inter-feature 的 fully-connected network, 顯然不可行!
- 因為是一個 $(512\cdot 768)^2 = 154$ B weights,同時 computation 也要 154 T operation!
- Input 是變動的長度, 所以固定的 154B weights 無法得到不同 width 的結果。

- 如果 input-output 只作用或處理在 embedding dimension (i.e shared weight for all input tokens!), 例如 1-dimension convolution, kernel 就是 1x768, channel length = 768. 假設 input 是 3-channel (e.g. RGB or KQV), parameter = 3 x 768^2 = 2M parameters. 顯然也不夠力。同時 each token 都是獨立處理,缺乏 temporal information!
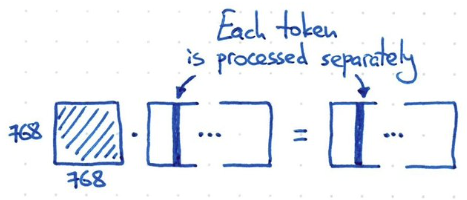
Catch
- 我們需要找一個方法介於 fully connected model and 1-d convolution network!!!
- Fully connect network size: (512x768)^2 = 154B
- 1-dimension network size: (768x768) < 1M
- 所以需要如同下面的方法!計算 $f(X) = X X^T X$. 假設 X 是 m x n -> (m x n) (n x m) (m x n) = m x n 得到和原來一樣的 shape!
- 此時 token 和 token 之間 interact, 但又不像 fully connected 這麼多 interaction!!! 這就是 attention 的原理!
- Rank = min(m, n)! 如果 width 很小,例如短句。或是 attention 範圍小。rank 就小。計算量就小,也避免 overfit!
- 問題是以下的方法,沒有任何 trainable parameter!!!!
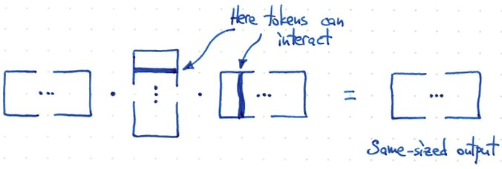
如何引入 Trainable Parameter?
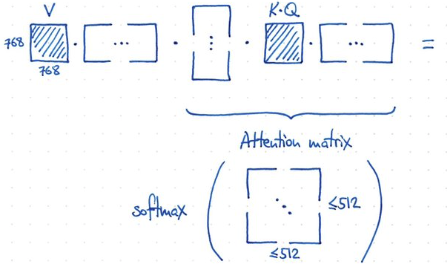
- 如何做到?非常容易! 重組 input 引入 V (value) matrix. 引入 K, Q matrix and similarity/attention matrix!!
- 使用 K, Q 計算 similarity matrix (512x512),then softmax for attention matrix. V 通過 attention matrix 得到 output!
- 因為 attention matrix 的遠小於 768! 所以有類似 low rank 的功效。
- V, K, Q 的 dimension:
- V: 768x768, K: 768x768, Q: 768x768. Total: 3 x (768x768)
- 最後再加上一個 MLP layer. Hidden layer 的 dimension 是 4x768!, 所以 parameter = 768^2 x 4 x 2? = 5M parameters!

- 一個 transformer block 的 parameter = V,K,Q x 768^2 = 3 x 768^2 = 2M param + 5 M= 7.1 M parameters
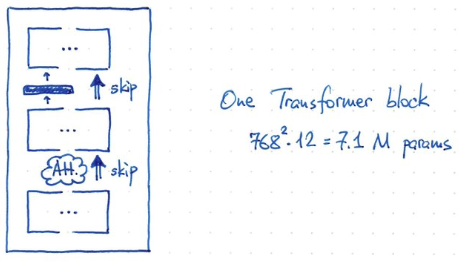
- BERT 有 12 blocks, giving ~ 85M parameters (再加上 25M for token embedding and position encoding, 30522 x 768 + 512 x 768 = 24M)
- BERT 的 inputs are sequences of 512 consecutive tokens!
- BERT 使用 uncased (not case sensitive) vocabulary size of 30522! GPT 是 case sensitive unicode of 50257.
- BERT 參數大約是 85M (12 block transformer) + 24M (embedding+position encode) = 110M

-
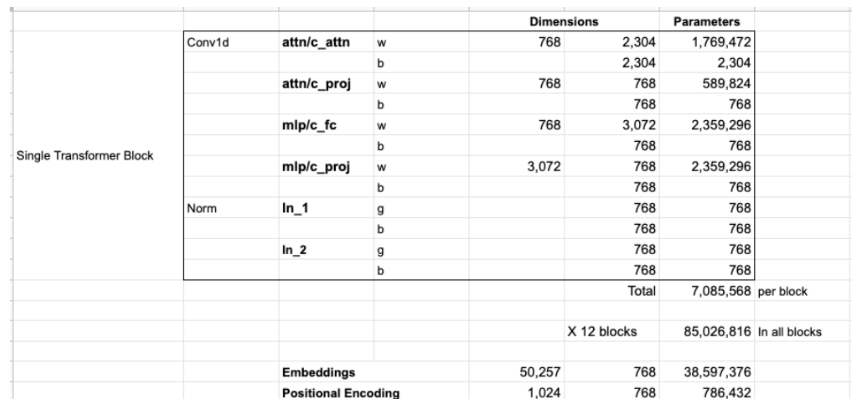
GPT2 : 以下是 Jay Alammar 對 GPT2 的參數估算,似乎一樣??? (2304 = 768x3 KQV, 3072=768x4 MLP)
- GPT2 的 inputs are sequences of 1024 consecutive tokens!
- GPT2 參數大約是 85M (12 block transformer) + 40M (embedding+position encode) = 125MB!!
- 爲什麽 token embedding 如此大, 38.6M? 不是因爲 token length 太長!而是支持 byte-level version of Byte Pair Encoding (BPE) for unicode characters and a vocabulary size of 50257.
-
-
Token length 的影響
-
BERT 的 max token length = 512; GPT2 的 max token length = 1024
-
注意每個 transformer block 的 7.1M parameters 數目和 token length 完全無關 (無論是 512 or 1024)!!!!
-
注意 token embedding 的參數大小和支持的字符集 (vocabulary) 有関 (BERT:32K or GPT:50K),和 token length 也無関!!!只有 position encode 的參數大小和 token length 有関 (512x768 or 1024x768) 不過對參數量的影響很小。
-
Token length 到底和什麽有関? transformer 内部計算的中間 result 會有 512 (or 1024)x768 matrix, 所以直接和計算量 (TOPS) 以及内存大小有關。但是和參數無關。、
-
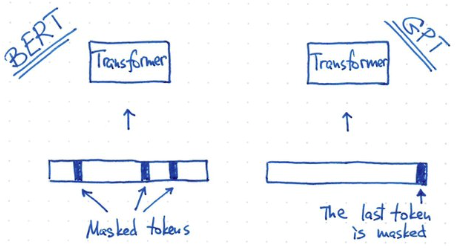
- 除了 token length 不同, BERT 和 GPT2 training 方式也不同: BERT 使用 masked token. GPT 使用 predicted token. 這也反應在他們的架構上: BERT 是 transformer encoder; GPT 是 transformer decoder.
-
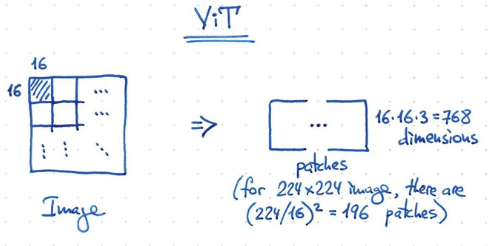
ViT 原理和 BERT 一樣, 都是 transformer encoder!
-
1-patch = 16x16x3 = 768 dimension. 224x224 image, 一共有 196 patches + 1 classification token = 197 tokens (<512 token).
-
ViT transformer 部分參數量和 BERT 一樣都是 85M。不過 embedding project 部分不同:
-
BERT embedding+position encoding: 30522 x 768 + 512 x 768 = 24M
-
ViT 是把 16x16(pixel)x3(RGB) = 768 重新 map 到 768 dimension, 所以只有 768x768+197x768=741120=0.75M. 所以 ViT 的全部參數基本就是 85+0.75~86M!
-
-
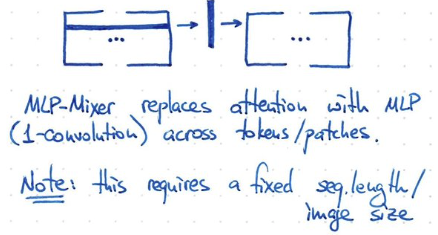
ViT 另一個簡化是使用 1-convolution 可以 work!! 也就是 shared weight!
- VIT 的大小:
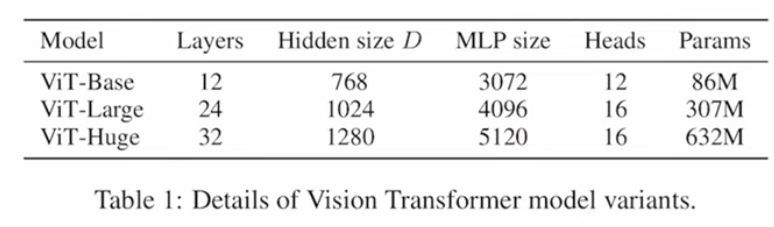
C: Information Retrieval Interpretation
Query (search) and Key (Title)
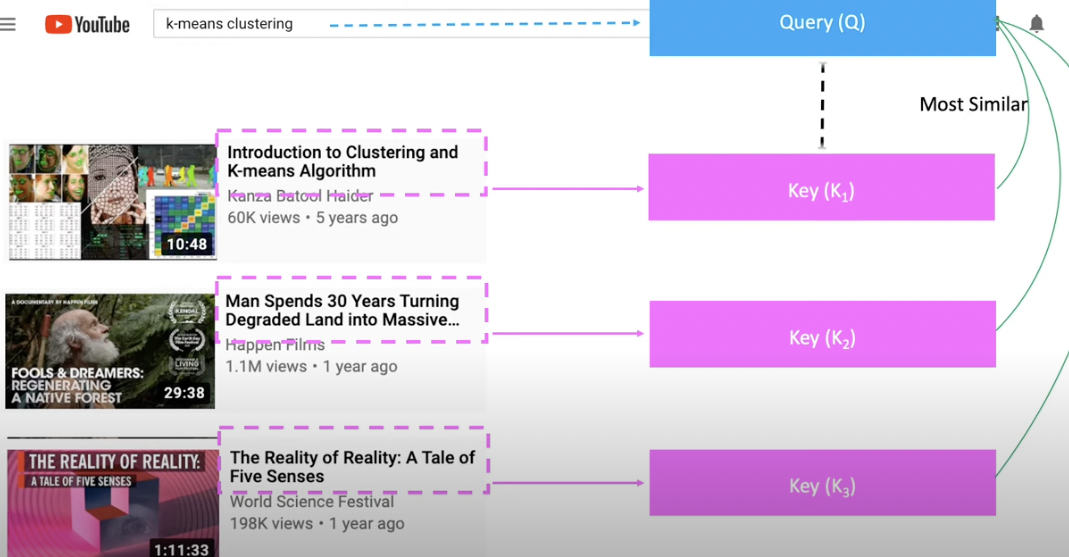
Once match, then value (content)
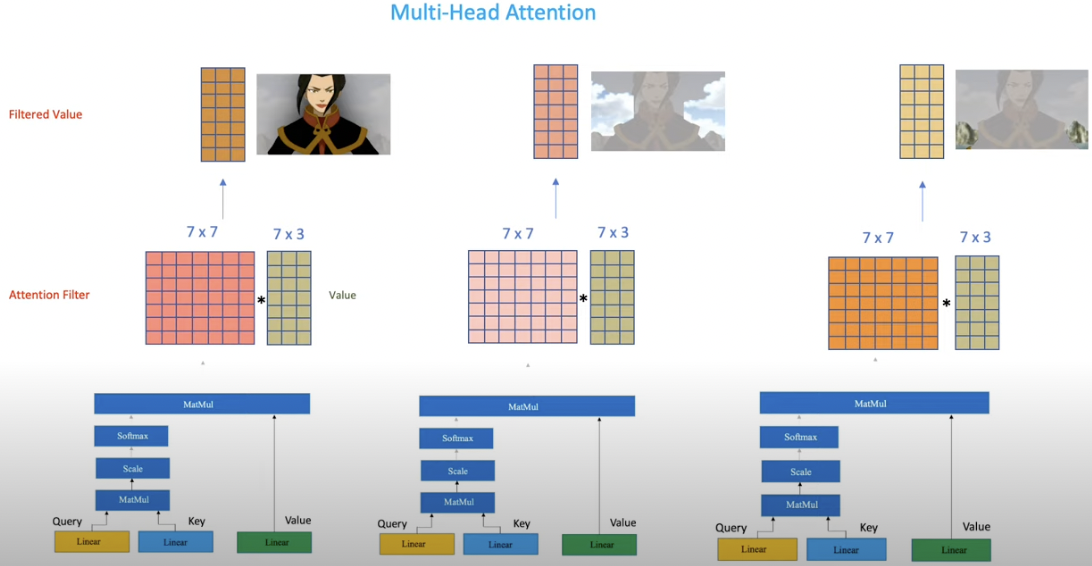
Multi-head attention