Reference
Introduction
兩個原因探索推薦系統:(1) transformer 使用的 attention 機制 Query, Key, Value 似乎來自推薦系統; (2) Twitter open source 它的推薦系統 (4/1/2023)。
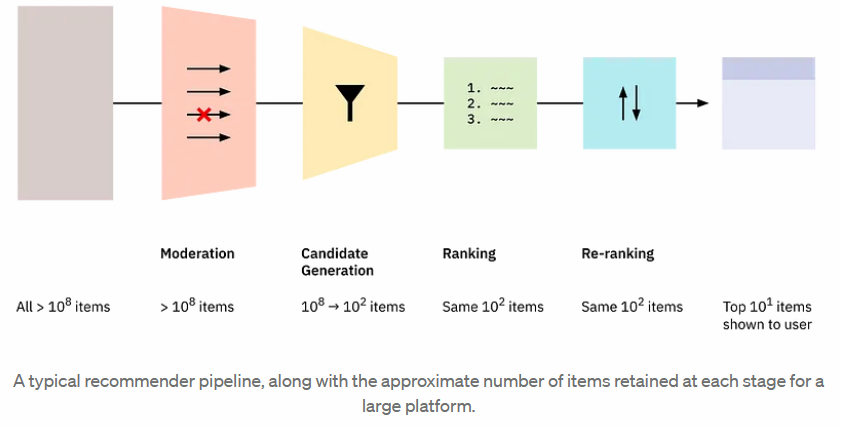
Phase 1: Filtering
我對於推薦系統還是停留在 phase 1: filtering.
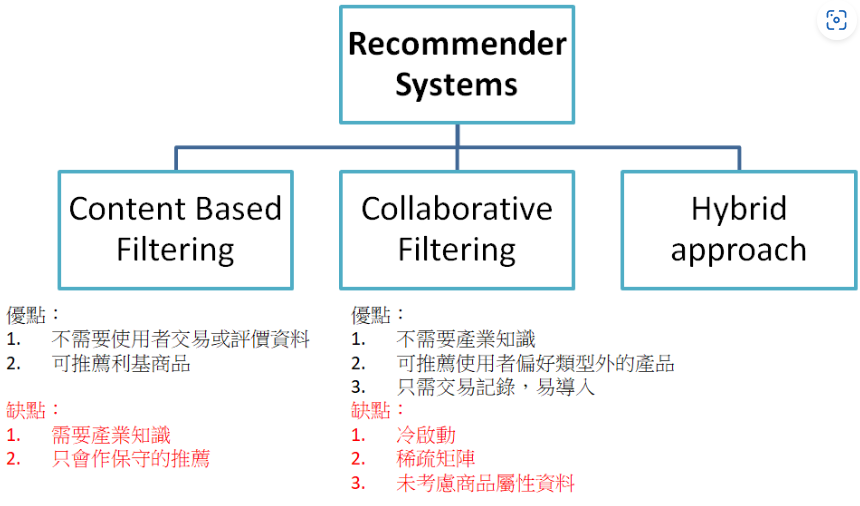
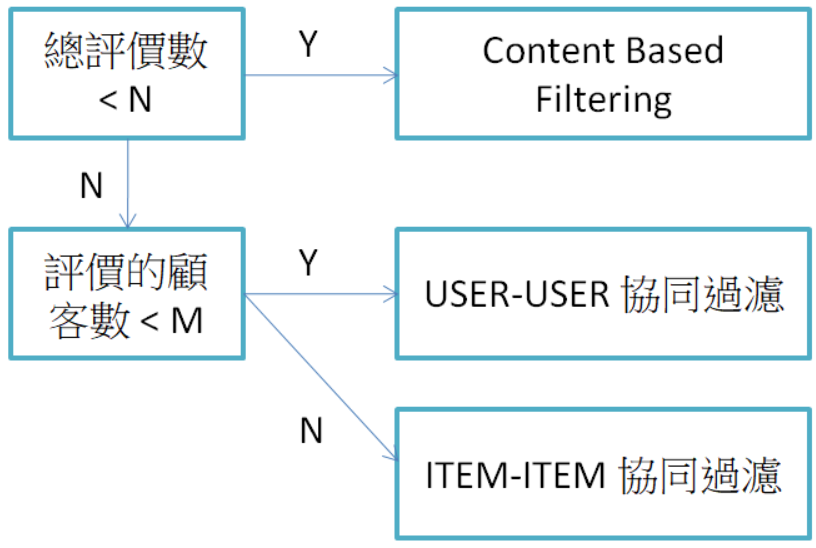
Hybrid approach 就是結合 content based filtering 和 collaborative filtering. (N 是網站的總評價數,M 是單項商品的總評價數)。
Collaborative filtering 則是利用 matrix SVD, 也就是利用 low rank 的特性。
Phase 2: Deep Learning 推薦系統
YouTube 在 2016 年有發表一個完整的架構,它主要是以兩個神經網路(Neural Networks)建構而成,有興趣的讀者可參閱『Deep Neural Networks for YouTube Recommendations』。
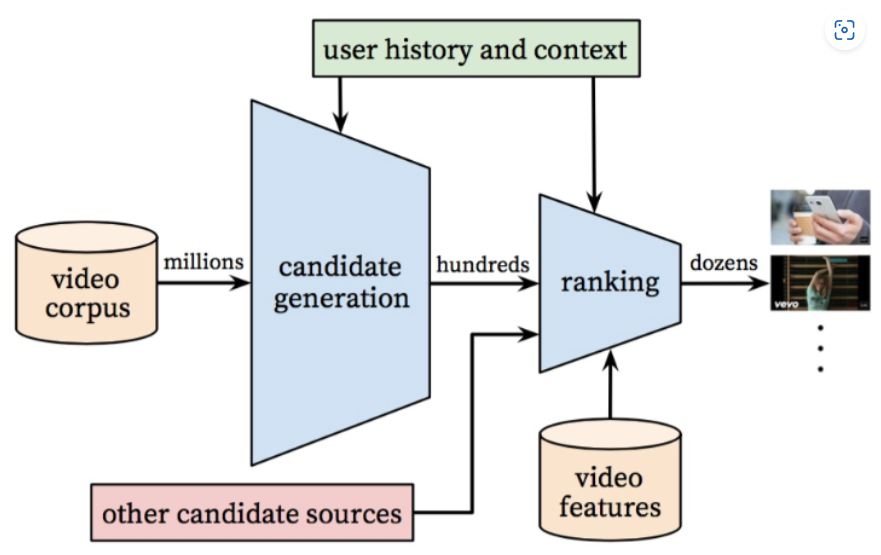
Figure: Recomendation system architecture demonstrating the “funnel” where candidate video are retrieved and ranked before presenting only a few to the user.
兩大神經網絡
該論文以算法的基本架構作為開篇,下面是作者的圖示:
基於 YouTube 用戶的個人觀看紀錄與觀看時長,加上相似用戶的瀏覽記錄,這稱作「協同過濾」 (collaborative filtering)。
本質上這就是兩個大的過濾器,各自有著不同的輸入。作者寫道:
該系統由兩大神經網絡組成,一個用於生成候選視頻,一個用來對其排名。
這兩個過濾器及其輸入內容,基本上決定了用戶在YouTubes上能看到的每一個影片:建議你播放的下一個、推薦給你的影片列表、你所瀏覽的影片列表……
第一個過濾器是候選生成器。論文中解釋,候選是基於用戶的 YouTube 活動記錄產生的,也就是用戶的觀看歷史與觀看時長。候選生成器還會考慮相似用戶的瀏覽記錄,這一點被稱為協同過濾。相似用戶是算法透過影片 ID、搜尋關鍵詞及相關的用戶統計訊息決定出來的。
候選生成器的通過率僅為屬百分之一,換言之,如果某個影片能從數百個中脫穎而出成為你的候選影片,它必定是跟你的觀看記錄有關,同時還有一個跟你相似的用戶已經看過它。
第二個是排名過濾器。該論文對排名過濾器進行了大量的深度解析,並列舉出不少有趣的因素。作者寫道,排名過濾器是這樣給影片排名的:
基於描述影片和用戶的豐富特徵,目標期望函數會給每個影片設定分數。根據分數排名,得分最高的影片將被展示給用戶。
由於觀看時長是 YouTube 為用戶設定的首要目標,我們只好假定這就是「目標期望函數」的意義。因此,考慮到各種不同的用戶輸入,該分數的意義就是某影片能夠轉化成用戶觀看時長的程度。但不幸的是,事情沒有那麼簡單。根據作者透露,該算法還會考慮很多其他的因素。
我們在排名過濾器中用到了數百種特徵。
如何對影片進行排名這一塊的數學原理非常複雜。論文既沒有詳述排名過濾器所用的數百項因素,又沒有提及他們是如何加權的。但它列舉了其中的三大主要因素:瀏覽記錄、搜尋記錄、觀看人數,以及包括新鮮程度在內的其他影片元素。
每一秒鐘都有大量的影片上傳到 YouTube。向用戶推薦這些最新上傳的新鮮內容,對 YouTube 來說極其重要。我們長期觀察的結果是,用戶喜歡新鮮的內容,即便有些內容跟他的關聯程度並不大。
論文中提到的比較有趣的一點,是算法並不總會受用戶所看的上一個影片的影響,除非你的觀看記錄極其有限。
我們會優先使用用戶的隨機觀看和關鍵詞搜尋記錄,然後才會考慮上一個觀看影片的數據。
在論文後面討論影片封面圖和標題的時候,他們提到了點擊率的問題:
舉例來說,用戶有很大的機率來觀看系統推薦的影片,但不太可能基於封面圖的選擇而去點擊其主頁……我們最終的排名會根據實時 A/B 測試的結果不斷調整,它大體上就是一個用於預測用戶觀看時長的簡單函數。
在這裡提出點擊率的問題其實並未出乎預料。為了能生成更多觀看時間,一個影片必須先讓人看到才成,其中最好的辦法就是做出一個很讚的縮略圖並相出一個很讚的標題。這讓很多影片上傳者都認為點擊率對於影片在算法中的排名極其重要。
但 YouTube 知道點擊率是可以人為衝上去的,所以他們也給出了應對之策。他們在論文中是這麼承認的:
通過點擊率進行排名往往會變相鼓勵誘導性的影片內容,用戶即便點進去也很少看完視頻,因而觀看時長更能反映出影片的好壞。
起碼這一機制還算鼓舞人心,作者接下來寫到:
如果用戶並未觀看最近推薦的影片,頁面下一次加載時模型就會自動降低該影片的排名。
這就說明,如果用戶沒有點擊特定的影片,該算法就不再將其推薦給相似的用戶。頻道推薦的情況也一樣,論文中的證據如下:
我們觀察到的最為重要的信號是用來描述用戶此前跟某個影片及其他相似影片的交互的……舉例來說,考慮一下用戶跟某個頻道已經被算法打分過的影片的交互記錄:該頻道有多少影片被該用戶看過?該用戶觀看同類話題的上一個影片是在什麼時間?此類描述用戶過往活動的數據特別強大……
此外,該論文還指出,算法在訓練時考慮了 YouTube 影片所有的觀看方式,包括那些推薦算法觸及不到的地方:
訓練數據生成自所有觀看方式的 YouTube 影片(包括內嵌在其他網頁中的那些),而非僅用我們自己所生成推薦影片。否則,新內容將很難登上推薦榜單,而推薦系統又將過於依賴過往影片的數據。如果用戶通過內容查找到的影片不同於我們的推薦,我們就需要能迅速通過推薦系統把該發現傳播給其他用戶。
最終,這一切又回到了算法所用的觀看時間。正如我們在論文開頭所看到的,該算法在設計之初就是一個「目標期望函數」,作者總結「我們的目標就是為了預測用戶的觀看時長」,「我們最終的排名會根據實時 A/B 測試的結果不斷調整,它大體上就是一個用於預測用戶觀看時長的簡單函數。 」
這也再一次說明了影片觀看時間之於算法的重要性,該算法的目的就是為了 YouTube 網站上能有更多、更長的影片以及更多、更長的用戶觀看時間。
一個簡單的回顧
講了這麼多,讓我們簡單回顧一下:
- YouTube 使用三個主要的觀看因素來推薦影片,它們是用戶的觀看歷史、搜尋記錄以及相關的用戶統計訊息。
- 推薦影片是透過候選生成器與排名過濾器的篩選出來的,這兩大過濾器決定了YouTube 如何讀取、篩選影片,如何生成推薦列表。
- 排名過濾器主要是基於用戶輸入的因素,其他因素還包括影片的「新鮮程度」和點擊率。
- 推薦算法的設計初衷是持續增加用戶在 YouTube 網站的觀看時長,其方法是持續把影片 A/B 測試的實時結果不斷反饋給神經網絡,從而使 YouTube 能不斷為用戶推薦它大體上就是一個用於預測用戶觀看時長的簡單函數。
幾個類似 concept
- embedding
- token
- query
YouTube 算法的實際案例
如果你還不明白,咱們就再舉一個例子
我們用一個實例來說明這個推薦系統具體是如何運作的:
比如說,小明很喜歡 YouTube,他有 YouTube 帳號相關的一切。每天瀏覽 YouTube 時,他都會在瀏覽器登錄。一旦登錄,YouTube 便給小明此次瀏覽的內容創建三個token:瀏覽記錄、搜尋記錄以及關於他的統計訊息。小明可能壓根就不知道這三種數據的存在。
然後輪到候選生成器上場了。YouTube 拿這三個 token 的值跟觀看記錄類似於小明的用戶進行對比,由此篩選出小明可能會喜歡的數百個影片,過濾掉 YouTube 影片庫中數以百萬計的其他內容。
接下來,基於影片和小明的相關性,這些影片被排名算法排序。排序時該算法會考慮這樣一些問題:小明有多大的可能會打開這個影片?這個影片有沒有可能讓小明在 YouTube 上打發更多時間?這個影片的新鮮程度如何?小明最近在 YouTube 上的活動程度如何?還有數百個其他的問題。
經過 YouTube 算法的讀取、篩选和推薦後,排名最高的影片將被推薦給小明。之後小明看與不看的選擇數據都會反饋給神經網絡,以供算法後續使用。影片被點開,並吸引小明在 YouTube 上打發更多時間的目標,則一直持續下去。那些小明沒有點開的推薦影片,等他下次登錄網站時則有可能通不過候選生成器。
總結
Deep Neural Networks for YouTube Recommendations 這篇論文讀起來很棒,它第一次讓人從源頭直擊 YouTube 推薦算法的內幕!!我們希望能接觸到更多的論文,以便在為這個平台製作內容的時候能做出更好的選擇。這也是願意花時間來寫這些內容的根本原因。畢竟,更適合該平台的內容就意味著更多的瀏覽量、更高的收入,從而讓我們能有更多的資源來為數以十億計的用戶製作出品質更高、更有吸引力的內容。
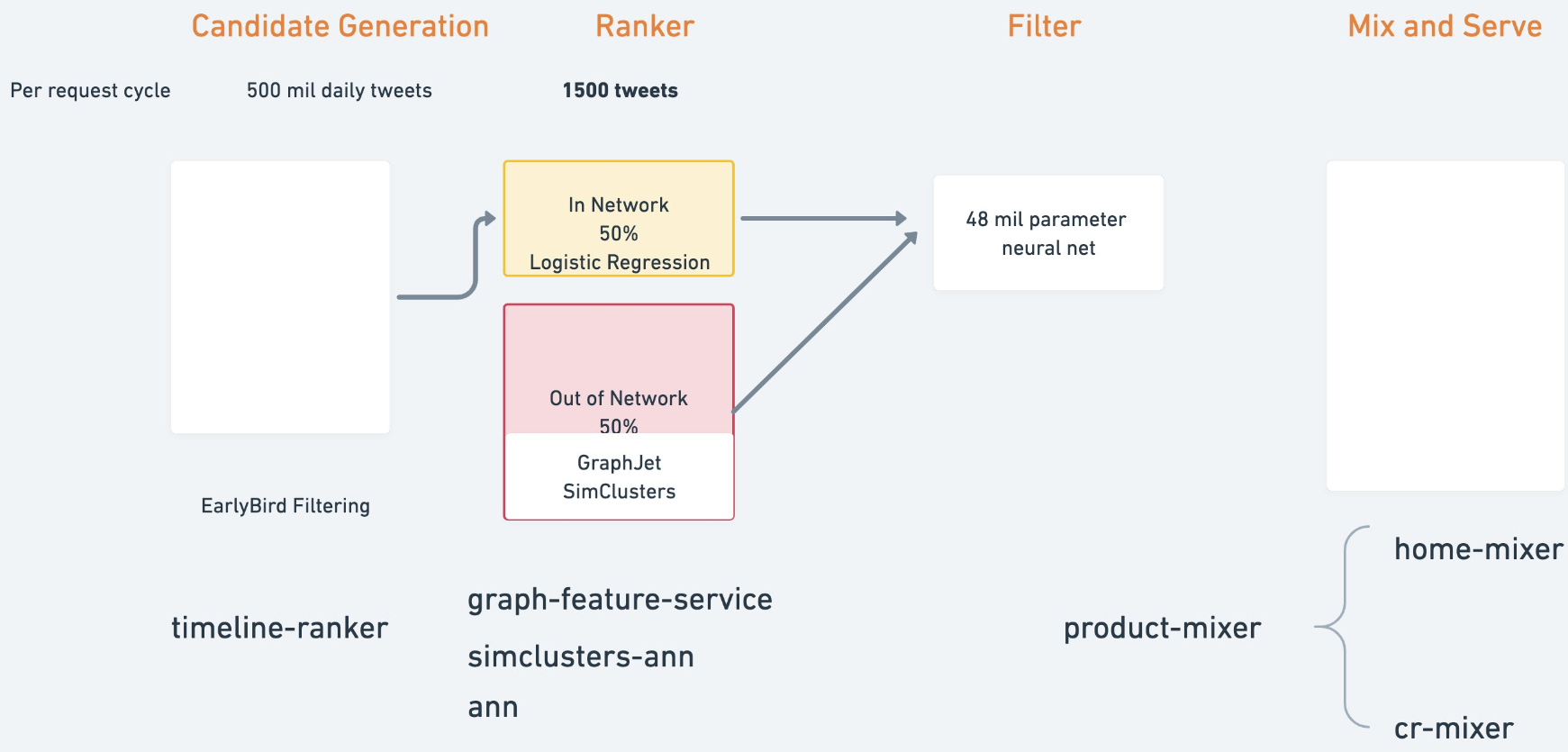
Twitter 算法