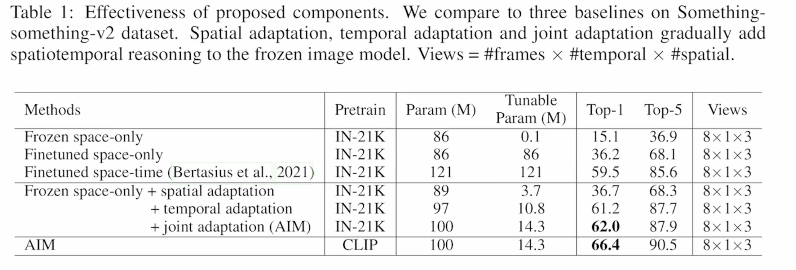
NLP
(2019 Google AI) BERT - Pre-training of Bidirectional Transformer
Model: Transformer (Encoder)
Training: SSL and bidirectional (mask and consecutive sentences)
Fine-tuning: full fine-tune
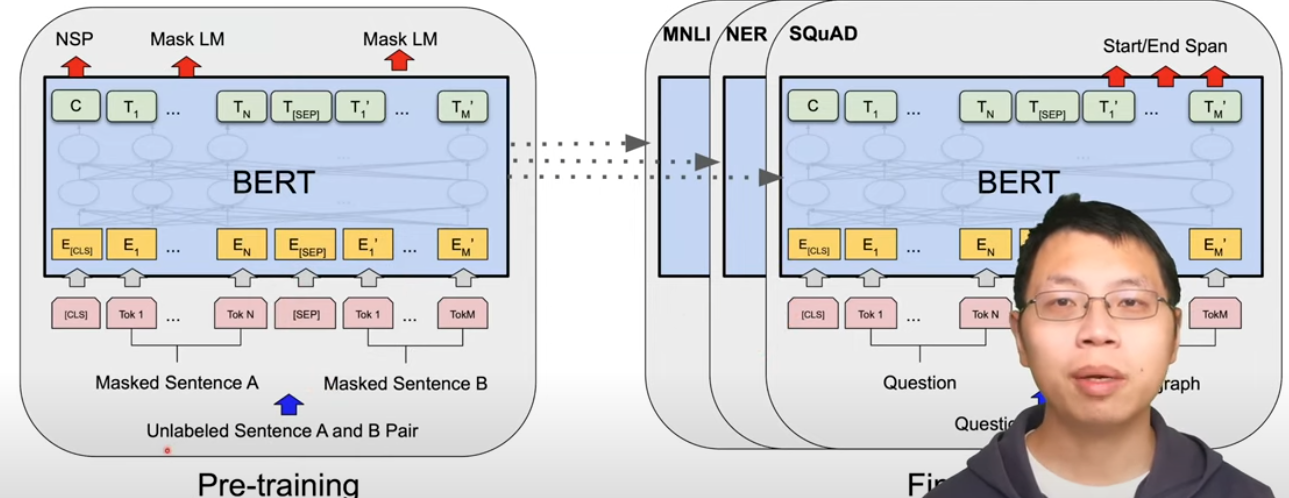
(2022 OpenAI) Whisper for multilingual speech recognition
OpenAI Whisper 精读【论文精读】 - YouTube
Model: Transformer (audio encoder+ text decoder)
Training: Weakly Supervised Learning
Summary
- 高端的食材,只需要最朴素的烹饪
- Big weak supervised learning
- Model 就是 native transformer : input Mel spectrum, output: script
- Pro: ROBUST and no fine-tuning needed, SOTA on many tasks
- Con: big computation.
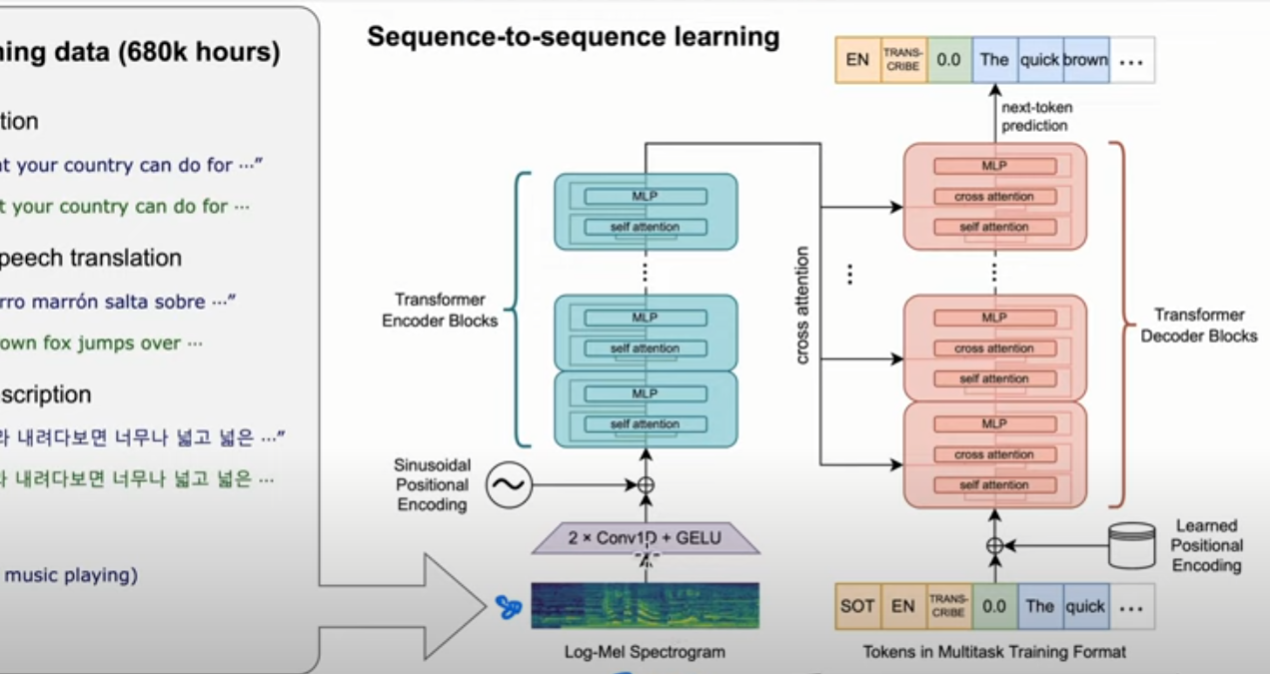
(2022 Microsoft) Neural Corpus Indexer (NCI)
Neural Corpus Indexer 文档检索【论文精读】 - YouTube
Model: Transformer (encoder+decoder)
Training: Supervised Learning
Summary
- Semantic search using neural network (end-to-end)
- Reranking 本來就是 neural network
- Query generation 很重要
Computer Vision
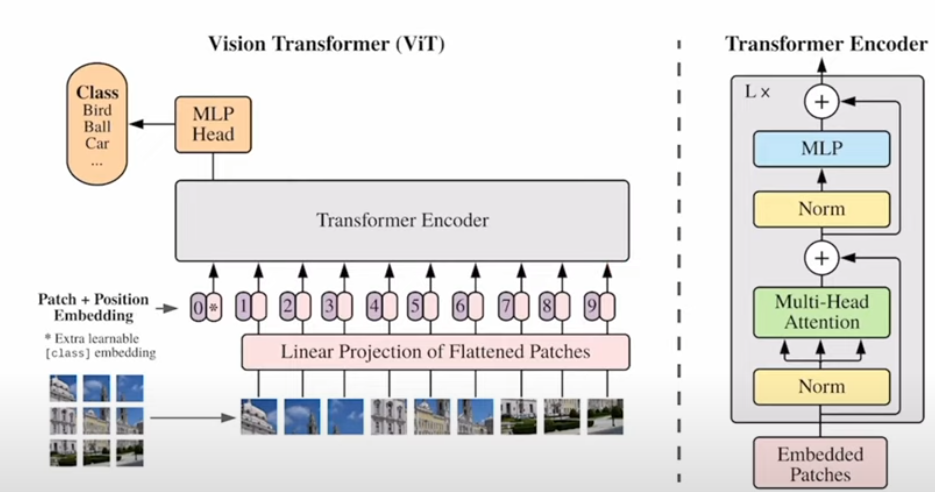
(2021 Google) ViT: An image is worth 16x16 words
Model: Transformer (Encoder)
Training: Supervised Learning, but touching SSL in last section
(2021 Microsoft MSRA) SWIN - Shifted WINdow Transformer for CV
Swin Transformer論文精讀【論文精讀】 - YouTube
Model: Transformer with hierarchy (Encoder)
Training: Supervised Learning
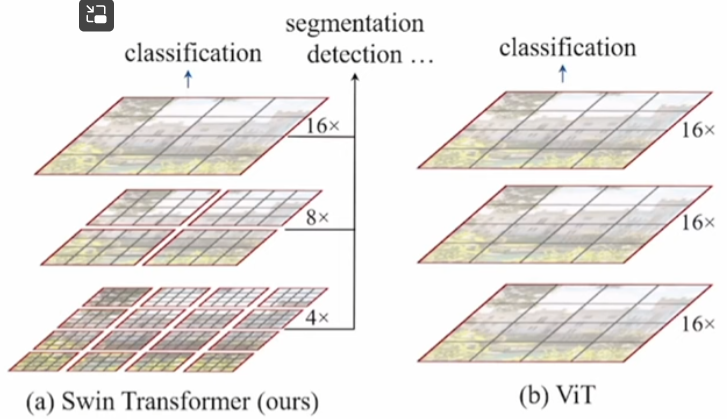
Summary and contribution
Solve two problems of ViT
- 不同尺度問題: hierarchy
- 計算量問題 :shifted window (local)
Key to success from CNN
-
Window attention + shifted window attention 取代 global attention!
-
用 patch merge 取代 pooling!
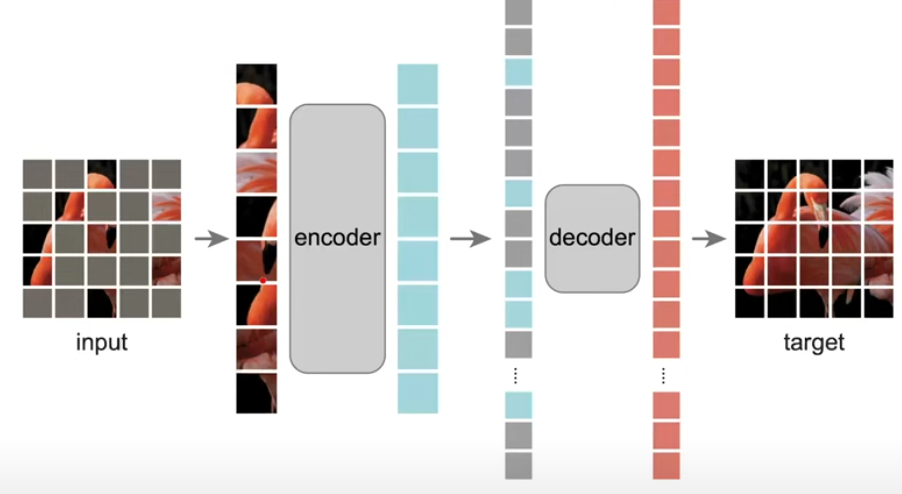
(2022 Meta, MAIR) MAE: Masked Auto-Encoder: scalable self-supervised learning for vision
Model: Vision Transformer (ViT encoder + transformer decoder + linear projection)
Training: SSL (mask auto-encoder)
Fine-tuning: full fine-tune and linear projection (last layer)
Summary and contribution
-
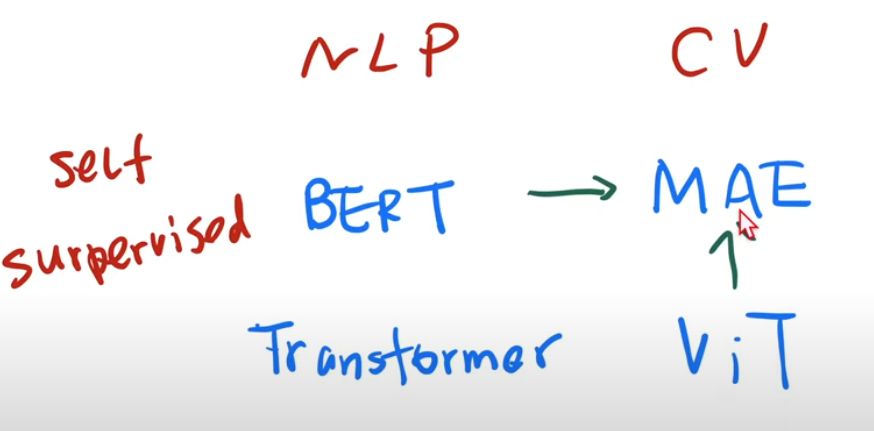
Transformer -> BERT -> ViT (CV) -> MAE (CV BERT, MLP)
-
NLP Computer Vision First use transformer
but supervised learningTransformer ViT First use self-supervised learning
and achieve good resultsBERT MAE First use self-supervised learning
on large model (>1B)GPT-2 (1.5B?)
auto-regressionMAE on ViT-Huge (?)
auto-encoder
- 這裏的 AE 只是强調 auto + encoder, 和傳統的 MLP auto-encoder 或是 convolution auto-encoder 完全沒有關係! Encoder 仍然是 transformer 的架構!
- MAE is based on ViT which is based on transformer
-
Decoder 是 MLP? NO! 還是一個 transformer block. 只是 encoder and decoder 是非對稱!因爲 encoder 只處理 unmasked patches (只有 25% of image). Decoder 要處理全部 patches (input with masked patches and output restored patches), but decoder size is only 10% of the encoder!!
-
Use MAE on ViT-Huge on ImageNet-1K can achieve 87.8%, far better than the ViT paper self-supervised result on ViT-B model (80%)!
- ViT-22B 使用 supervised or self-supervised?
(2023 Amazon) AIM: Adapting Image Model for Video Recognition
大模型时代下做科研的四个思路【论文精读·52】 - YouTube
Model: Vision Transformer (ViT)
Training: Pre-trained ViT (frozen)
Fine-tuning: Adapter (spatial, temporal, joint)
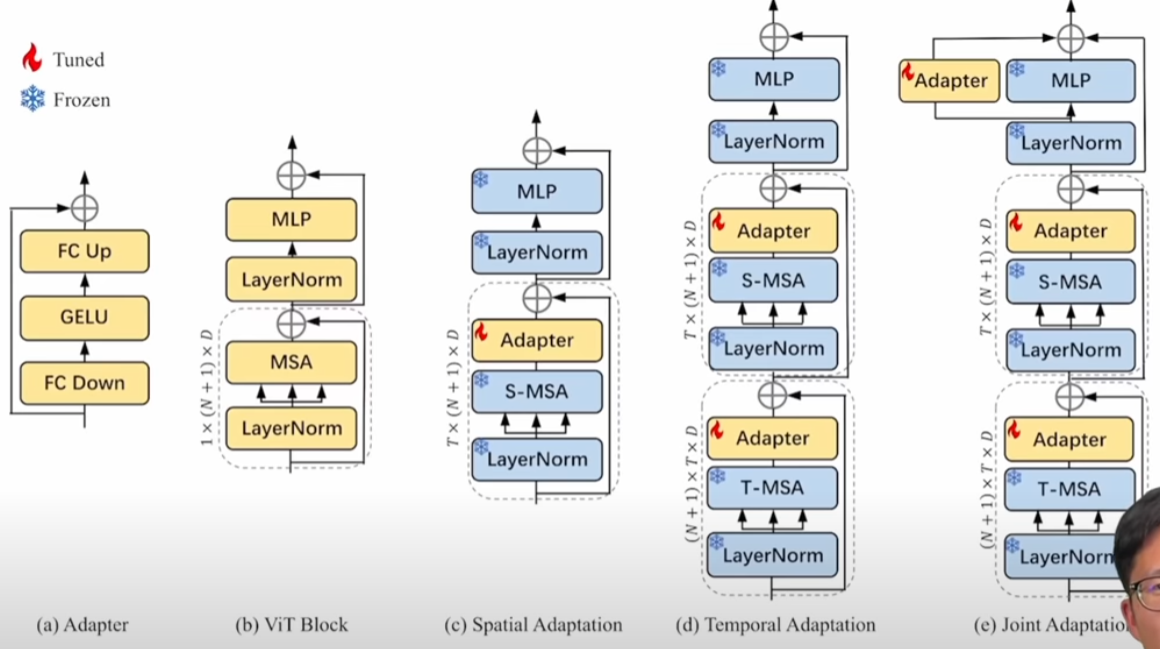
Summary
- Spatial adaptation + temporal adaptation + joint adptation