Source
- Flash Attention with attention bias: https://zhuanlan.zhihu.com/p/567167376
- Flash attention 2: https://tridao.me/publications/flash2/flash2.pdf
- Flash Decoder: https://princeton-nlp.github.io/flash-decoding/
- 詳細的 GPT2/3 參數計算: https://www.lesswrong.com/posts/3duR8CrvcHywrnhLo/how-does-gpt-3-spend-its-175b-parameters
- GPT3 原始 paper.
- GPT2 原始 paper.
- LLM1, https://finbarr.ca/how-is-llama-cpp-possible/
- FlashAttention图解(如何加速Attention) - 知乎 (zhihu.com)
- NLP(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能 - 知乎 (zhihu.com)
- FlashAttenion-V3: Flash Decoding详解 https://zhuanlan.zhihu.com/p/661478232
- Flash Decoding ++: https://mbd.baidu.com/newspage/data/landingsuper?rs=1906216269&ruk=xed99He2cfyczAP3Jws7PQ&pageType=1&isBdboxFrom=1&sid_for_share&urlext=%7B%22cuid%22%3A%22_a2K8_uSBijAu-uOYiSKtguqHaY1i2tq_8Hsugi6v8KX0qqSB%22%7D&context=%7B%22nid%22%3A%22news_9804123083419031340%22,%22sourceFrom%22%3A%22bjh%22%7D
Takeaway
Flash Attention
- 使用 computation to trade-off memory bandwidth!
- Computation 就是兩招: (1) tile, for forward (inference) and backward (training) pass; (2) re-compute attention for backward (training).
Flash Attention 2 (optimized for NV GPU)
https://www.youtube.com/watch?v=b1D_hGKblNU&ab_channel=DataScienceGems
- Reduced non-matmul FLOPS
- matmul throughput can be up to 16x higher than non-matmul throughput
- Parallelized attention computation
- Better work partitioning between warps?
Flash Attention 3 (Flash Decoder)
- 特別用來處理 long context! 并行處理 KQ and O
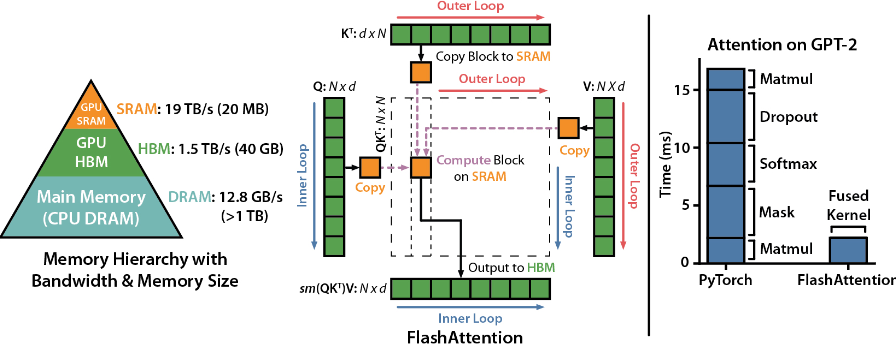
Flash Attention
Flash Attention (FA) 的主要思路就是通過 tile 技術減少在 DRAM 和 on-chip SRAM 讀寫實際。在 GPT2/3 medium model (sequence length=1024) 有三倍加速。 \(\begin{aligned}\text{MultiHead}(Q, K, V) & =\text{Concat}\left(\text{head}_1, \ldots, \text{head}_{n_{heads}}\right) W^O \\\text { where \quad head}_i & =\text {Attention}\left(Q W_i^Q, K W_i^K, V W_i^V\right)\end{aligned}\)
- 每一個 $\text{head}i$ 都是三個矩陣乘法,$Q W_i^Q, K W_i^K, V W_i^V$,每個矩陣乘法大小是 $(n{ctx} \times d_{model})\times (d_{model}\times d_{head}) = n_{ctx} \times d_{head}$。
Attention
- 再來是 Perform matrix correlation = $S = (Q W_i^Q) (K W_i^K)^T : n_{ctx} \times n_{ctx}$ , 如下圖中的中間虛線區域。
- 接下來要做 $n_{ctx}$ 次 P = softmax(S) softmax operation (以 row 為單位)。
- 再來 $\text{head}i = O_i = P (V W_i^V) \to (n{ctx} \times n_{ctx}) \times (n_{ctx} \times d_{head}) = n_{ctx} \times d_{head}$ 這步是簡化 memory bandwidth 的關鍵!
MultiHead Attention
- 所以每個 $\text{head}i = O_i$ 的大小是 $n{ctx}\times d_{head}$。但是因爲有 $n_{head}$ 而且 concatenate 在一起再做一次矩陣乘法 with $W^O$, $(n_{ctx} \times d_{model})\times (d_{model}\times d_{model})$。所以 $\text{MultiHead}(Q,K,V)$ 的大小是 ($n_{ctx}\times d_{model}$)
關鍵問題: 計算 $\text{head}i$ 需要先做 $n{ctx}$ 次 softmax(S) on $n_{ctx}\times n_{ctx}$ 矩陣,如何簡化 memory bandwidth, 而不是如何減少 computation, 甚至是用 computation 來換 memory bandwidth reduction?
FA 核心就是
- Inference: 計算 KQ matrix 不需要全部數據 [$n_{ctx}\times n_{ctx}$],而是用 tile: [$d_{head}\times d_{head}$] 分段計算
- Softmax 需要 renormalized
- GPT2: 1024 x 1024, 直觀上用 64 x 64 分段計算。
- Llama: 2048 x 2048, 直觀上用 128 x 128 分段計算。
- Training: Back-propagate 不存儲 attention matrix (1024x1024 or 2048x2048), 只需要存儲 softmax normalization 的係數
如何分段?
K 是 outer loop, 對於每個 Ki, (step 5)
Inner loop 儘量把 Qj 做完。 (step 7)
因為 SRAM 是有限的資源,Q 可以有 $\left[\frac{M} { n_{byte} d}\right]$ block size。此處不用拘泥於一個 block. 而是越多越好。
其中 $n_{byte}$ 的定義如下:
| $n_{byte}$ | |
|---|---|
| FP32 | 4 |
| FP16 | 2 |
| INT8 | 1 |
| INT4 | 0.5 |
這裡有一個 catch, 就是如何把分段的 softmax 變成整個 column 的 softmax. 需要做 re-normalization (在 Flash Attention 2 改善這部分).

Algorithm 1

以上是沒有 mask 的情況。Algorithm 2 是有 mask 的情況。(Step 11) why mask?

Flash Attention 2
- Softmax normalization reduction: reduce non-matmul FLOPS

-
Parallelizing attention computation (for batch > 1)
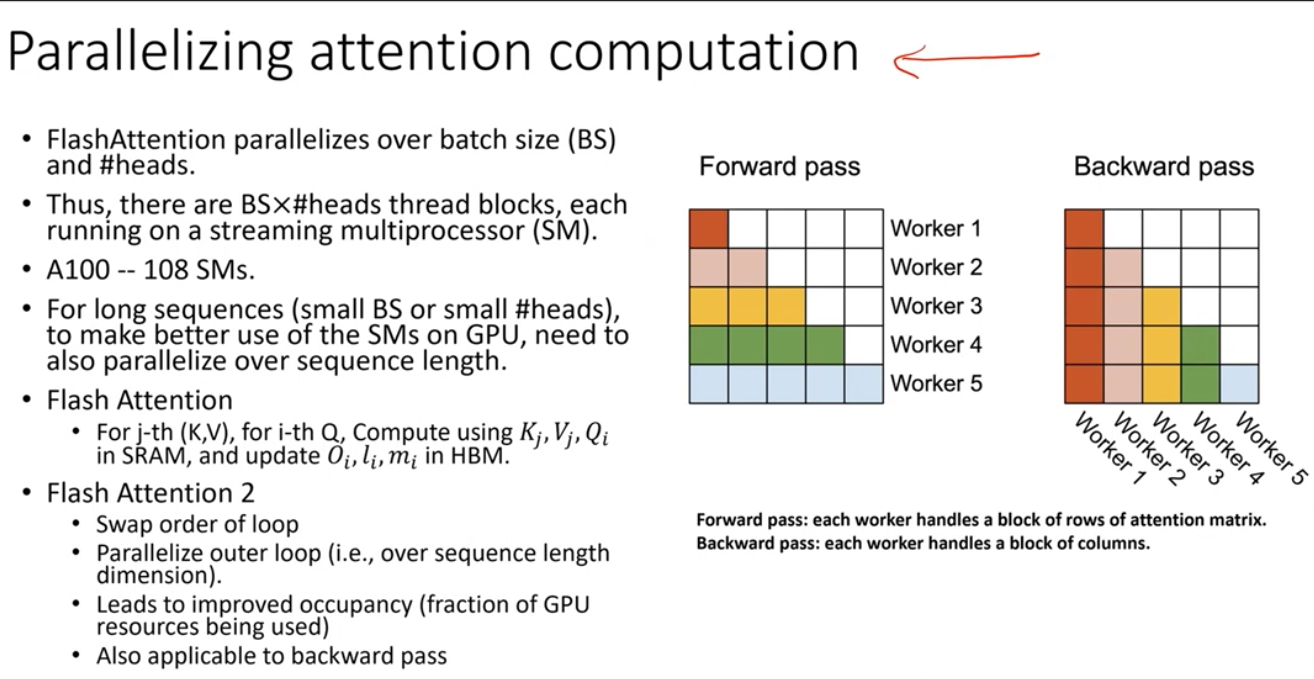
-
work partitioning between warps (What is warps?)
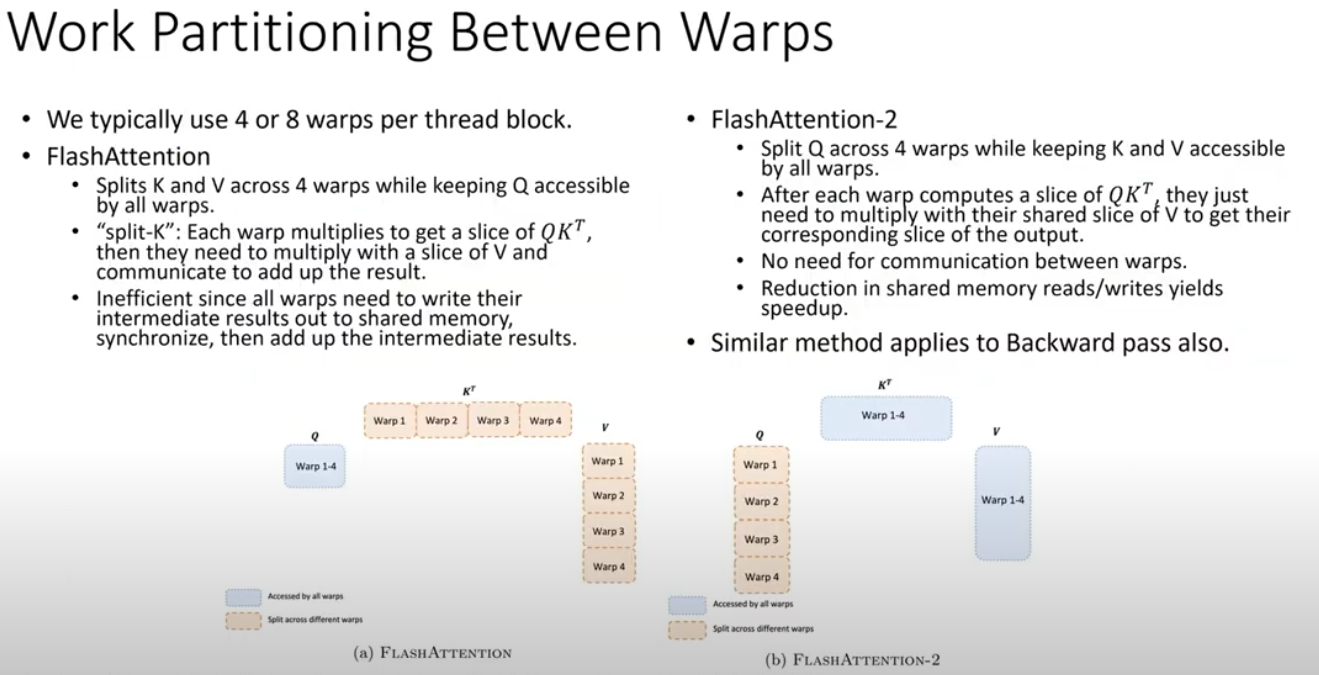
####
注意 Flash Attention 在 O(2) 的计算过程依赖 O(1),从下图也可以看出,FlashAttention是按顺序更新output的,其实当时我在看FlashAttention这篇文章时就觉得这个顺序操作可以优化的,因为反正都要rescale,不如最后统一rescale,没必要等之前block计算完(为了获取上一个block的max值)

Flash Attention 3: A faster attention for decoding: Flash-Decoding
上面提到FlashAttention对batch size和query length进行了并行化加速,Flash-Decoding在此基础上增加了一个新的并行化维度:keys/values的序列长度。即使batch size很小,但只要上下文足够长,它就可以充分利用GPU。与FlashAttention类似,Flash-Decoding几乎不用额外存储大量数据到全局内存中,从而减少了内存开销。
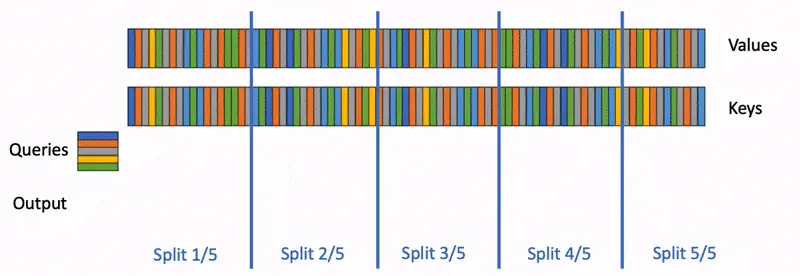
Flash Decoding主要包含以下三个步骤(可以结合上图来看):
- 将keys和values分成较小的block
- 使用FlashAttention并行计算query与每个block的注意力(这是和FlashAttention最大的区别)。对于每个block的每行(因为一行是一个特征维度),Flash Decoding会额外记录attention values的log-sum-exp(标量值,用于第3步进行rescale)
- 对所有output blocks进行reduction得到最终的output,需要用log-sum-exp值来重新调整每个块的贡献
实际应用中,第1步中的数据分块不涉及GPU操作(因为不需要在物理上分开),只需要对第2步和第3步执行单独的kernels。虽然最终的reduction操作会引入一些额外的计算,但在总体上,Flash-Decoding通过增加并行化的方式取得了更高的效率。
Flash Decode ++: A faster attention for decoding: Flash-Decoding
为了进一步解决问题,近日,来自无问芯穹(Infinigence-AI)、清华大学和上海交通大学的联合团队提出了一种新方法 FlashDecoding++,不仅能带来比之前方法更强的加速能力(可以将 GPU 推理提速 2-4 倍),更重要的是还同时支持 NVIDIA 和 AMD 的 GPU!它的核心思想是通过异步方法实现注意力计算的真正并行,并针对「矮胖」矩阵乘优化加速 Decode 阶段的计算。
New Idea:
Use Hierarchy softmax + sparsity!!
Hierarchical softmax is a replacement for softmax which is must faster to evaluate. While softmax is O(n) time, hierarchical softmax is O(logn) time.
https://www.quora.com/What-is-a-hierarchical-SoftMax-What-are-its-applications
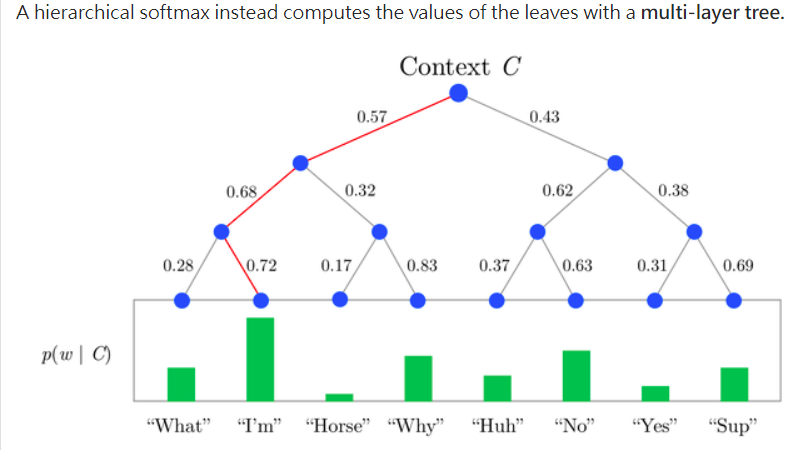
Make it fast
ChatGPT-2 (不論大小) 為例
Embedding
- 每個 tokens ($Q=K=V$) 進來先做一次mapping to $Q W_i^Q, K W_i^K, V W_i^V$,每個大小是 $n_{ctx} \times d_{head}$。
- 以 GPT2 所有的 models 都有一樣的 $n_{ctx}$ 和 $d_{head}$
- $Q W_i^Q, K W_i^K, V W_i^V$ 都是 1024 x 64
Attention
- 再來是 Perform matrix correlation = $S = (Q W_i^Q) (K W_i^K)^T : 1024 \times 1024$
- 接下來要做 1024 個 P = softmax(S) ($1024 \times 1024$) softmax operation (with token number, 以 column? 為單位)。
- 再來 $O_i = P (V W_i^V) \to (1024 \times 1024) \times (1024 \times 64) = 1024 \times 64$
- 最後 concatenat $O_i$ 變成 $O$ ($1024 \times d_{model}$), 再 $O W^o$ 得到 ($1024 \times d_{model}$)
- $d_{model}$ 是由 ChatGPT-2 的大小決定,from 768 到 1600.
FFN (Flash Attention 有特別針對 FFN?)
- 接下來是 FF layer
- (768 x 768?) or 64 x 128 (2x) + 128 x 256 (2x)? 這也是節省的重點。
Llama (不論大小) 為例
- Embedding
- 每個 tokens ($Q=K=V$) 進來先做一次mapping to $Q W_i^Q, K W_i^K, V W_i^V$,每個大小是 $n_{ctx} \times d_{head}$
- 以 Llama1 所有的 models 都有一樣的 $n_{ctx}$ 和 $d_{head}$
- $Q W_i^Q, K W_i^K, V W_i^V$ 都是 2048 x 128
- Attention
- 再來是 Perform matrix correlation = $S = (Q W_i^Q) (K W_i^K)^T : 2048 \times 2048$
- 接下來要做 2048 個 P = softmax(S) ($2048 \times 2048$) softmax operation (with token number, 以 column? 為單位)。
- 再來 $O_i = P (V W_i^V) \to (2048 \times 2048) \times (2048 \times 128) = 2048 \times 128$
- 最後 concatenat $O_i$ 變成 $O$ ($2048 \times d_{model}$), 再 $O W^o$ 得到 ($2048 \times d_{model}$)
- $d_{model}$ 是由 Llama 的大小決定,from 4096 (7B model) 到 8192 (65B model).
- 接下來是 FF layer
- (768 x 768?) or 64 x 128 (2x) + 128 x 256 (2x)? 這也是節省的重點。

一般 GPU 會把 S and P 放在 HBM, which takes O(N^2) memory. 通常 N » d (GPT2 medium, N = 1024, and d = 64)

Benchmarks on CodeLlama 34B
作者对CodeLLaMa-34b的decoding throughput进行了基准测试。该模型与Llama 2具有相同的架构。作者在各种序列长度(从512到64k)上测试了decoding速度,并比较了多种attention计算方法:
- PyTorch:使用纯PyTorch primitives运行注意力计算(不使用FlashAttention)。
- FlashAttention v2(v2.2之前的版本)。
- FasterTransformer:使用FasterTransformer attention kernel
- Flash-Decoding
- 将从内存中读取整个模型和KV Cache所需的时间作为上限