Source
https://python.langchain.com/docs/get_started/introduction.html : English version, LangChain
https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide :
LLM Application
Attention 已經是必備的 core network. 相較於 CNN, attention 最大的問題是 memory bandwidth.
主要在計算 K, Q 的 correlation, 以及 softmax.
幼稚園
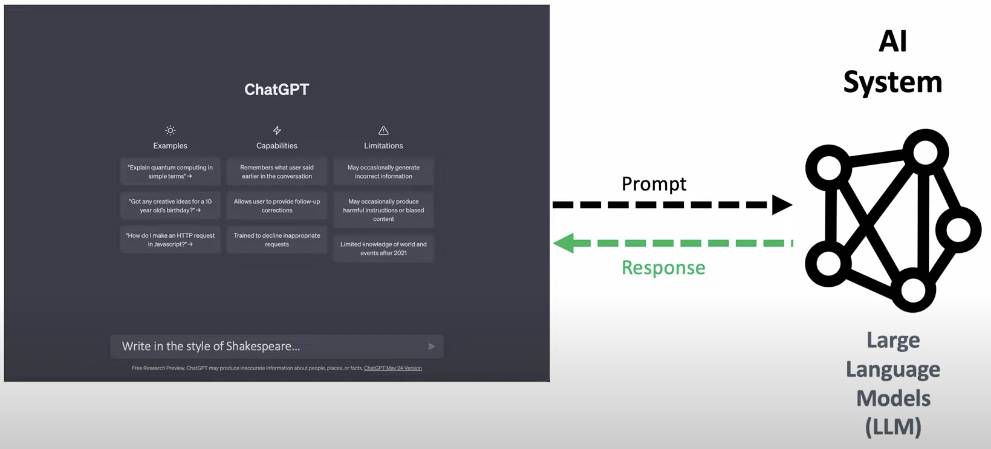
利用 prompt 產生 response. 最基本的操作。不過值得一提是 LLM “瞭解” 前後文的 prompt and response. 這裡就不多做說明。
小學
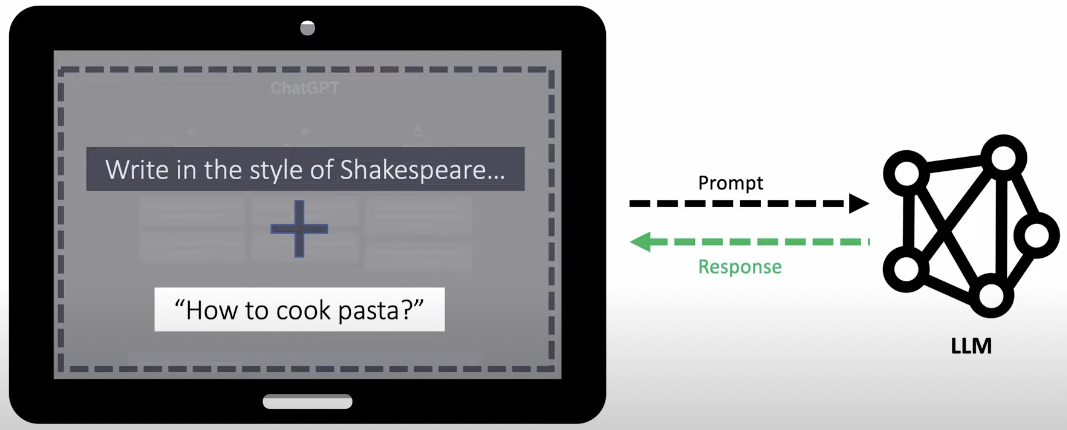
Prompt template: 如下的 “Write in the style of Shakespeare” 就是 template. 整體的 prompt = prompt template + input prompt.
1 | |
國中
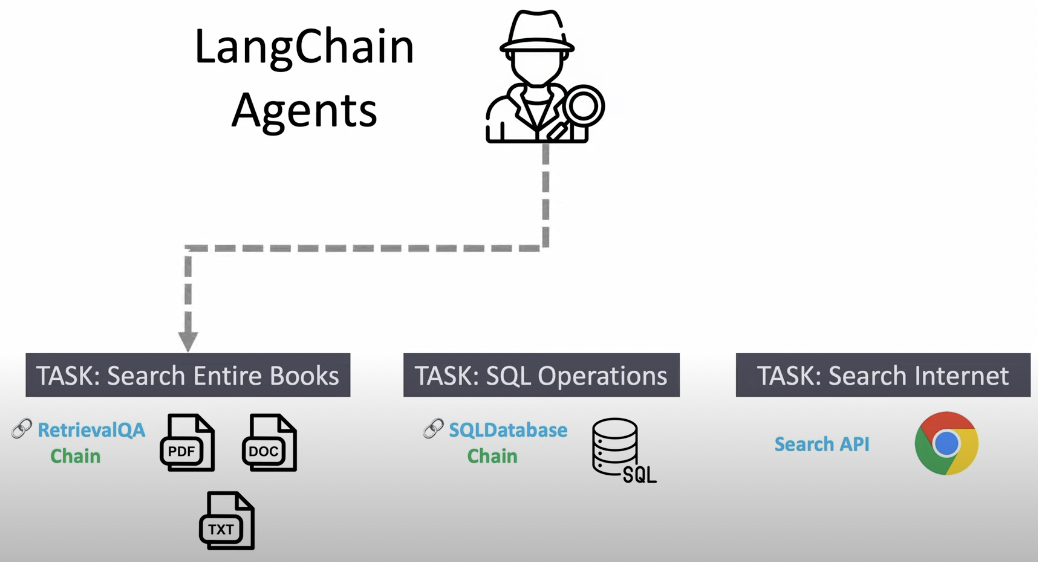
User Input -> Prompt Template -> Specify LLM
Task: Math problem, SQL, Search engine
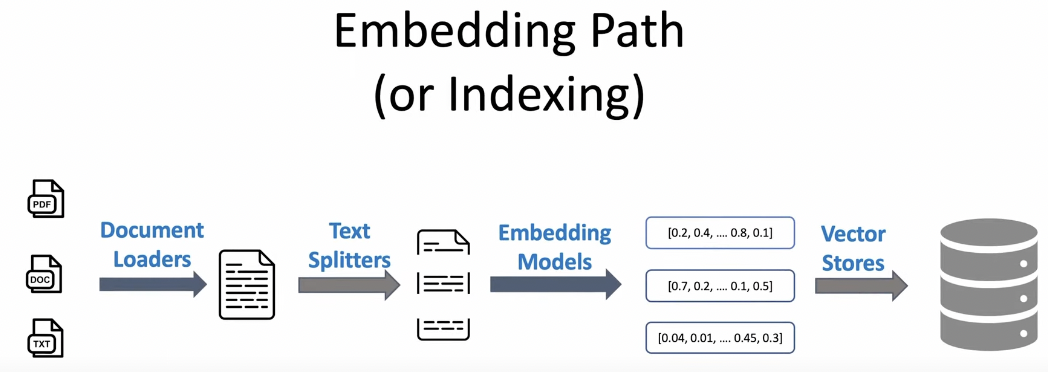
高中 (Embedding)
Load external pdf

大學 (Chain)
我們可以把 Chain 理解爲任務。一個 Chain 就是一個任務,當然也可以像鏈條一樣,一個一個的執行多個鏈。
可以連網,這是最 powerful 的地方。 OpenAI API 無法連網。
研究所 (Lang Chain, Agent)
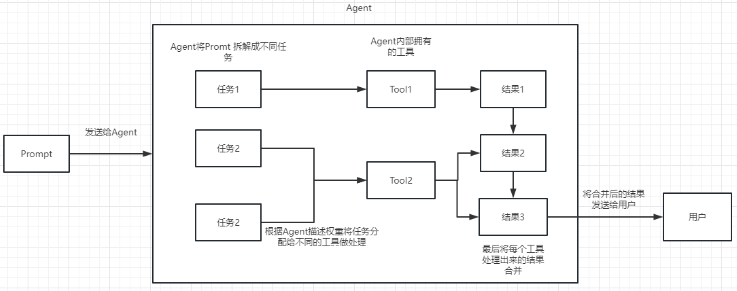
Lang Chain 基礎功能

LLM 調用
- 支持多種模型接口,比如 OpenAI、Hugging Face、AzureOpenAI …
- Fake LLM,用於測試
- 緩存的支持,比如 in-mem(內存)、SQLite、Redis、SQL
- 用量記錄
- 支持流模式(就是一個字一個字的返回,類似打字效果)
Prompt管理,支持各種自定義模板
擁有大量的文檔加載器,比如 Email、Markdown、PDF、Youtube …
對索引的支持
- 文檔分割器
- 向量化
- 對接向量存儲與搜索,比如 Chroma、Pinecone、Qdrand
Chains
- LLMChain
- 各種工具Chain
- LangChainHub
API
OpenAI API
如何申請 (money) and setup
1 | |
1 | |
HuggingFace API
1 | |
Go to HuggingFace website to obtain the token

1 | |
實例
Q and A
第一个案例,我们就来个最简单的,用 LangChain 加载 OpenAI 的模型,并且完成一次问答。
1 | |
回答如下:
人工智能可以被評價為一門研究電腦如何模仿人類智能行為的科學領域。它的目標是開發技術可以讓電腦思考 和做出決定,讓它可以處理人類不能處理的任務,例如識別圖像,語音識別,自然語言處理,機器人操作等。 它能為人類提供解決問題的新思路,在各個領域都有很多應用,讓人們的生活及工作更便捷,更輕鬆。
对超长文本进行总结
假如我们想要用 openai api 对一个段文本进行总结,我们通常的做法就是直接发给 api 让他总结。但是如果文本超过了 api 最大的 token 限制就会报错。
这时,我们一般会进行对文章进行分段,比如通过 tiktoken 计算并分割,然后将各段发送给 api 进行总结,最后将各段的总结再进行一个全部的总结。
如果,你用是 LangChain,他很好的帮我们处理了这个过程,使得我们编写代码变的非常简单。
首先我们对切割前和切割后的 document 个数进行了打印,我们可以看到,切割前就是只有整篇的一个 document,切割完成后,会把上面一个 document 切成 317 个 document。

最终输出了对前 5 个 document 的总结。

这里有几个参数需要注意:
文本分割器的 chunk_overlap 参数
这个是指切割后的每个 document 里包含几个上一个 document 结尾的内容,主要作用是为了增加每个 document 的上下文关联。比如,chunk_overlap=0时, 第一个 document 为 aaaaaa,第二个为 bbbbbb;当 chunk_overlap=2 时,第一个 document 为 aaaaaa,第二个为 aabbbbbb。
不过,这个也不是绝对的,要看所使用的那个文本分割模型内部的具体算法。
文本分割器可以参考这个文档:https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
chain 的 chain_type 参数
这个参数主要控制了将 document 传递给 llm 模型的方式,一共有 4 种方式:
stuff: 这种最简单粗暴,会把所有的 document 一次全部传给 llm 模型进行总结。如果document很多的话,势必会报超出最大 token 限制的错,所以总结文本的时候一般不会选中这个。
map_reduce: 这个方式会先将每个 document 进行总结,最后将所有 document 总结出的结果再进行一次总结。

refine: 这种方式会先总结第一个 document,然后在将第一个 document 总结出的内容和第二个 document 一起发给 llm 模型在进行总结,以此类推。这种方式的好处就是在总结后一个 document 的时候,会带着前一个的 document 进行总结,给需要总结的 document 添加了上下文,增加了总结内容的连贯性。

map_rerank: 这种一般不会用在总结的 chain 上,而是会用在问答的 chain 上,他其实是一种搜索答案的匹配方式。首先你要给出一个问题,他会根据问题给每个 document 计算一个这个 document 能回答这个问题的概率分数,然后找到分数最高的那个 document ,在通过把这个 document 转化为问题的 prompt 的一部分(问题+document)发送给 llm 模型,最后 llm 模型返回具体答案。