Source
-
[Transformer升级之路:16、“复盘”长度外推技术 - 科学空间 Scientific Spaces](https://spaces.ac.cn/archives/9948) -
Flash Attention with attention bias: https://zhuanlan.zhihu.com/p/567167376
-
Flash attention 2: https://tridao.me/publications/flash2/flash2.pdf
-
Flash Decoder: https://princeton-nlp.github.io/flash-decoding/
- 詳細的 GPT2/3 參數計算: https://www.lesswrong.com/posts/3duR8CrvcHywrnhLo/how-does-gpt-3-spend-its-175b-parameters local file: GPT parameters
- GPT3 原始 paper.
- GPT2 原始 paper.
- LLM1, https://finbarr.ca/how-is-llama-cpp-possible/
- FlashAttention圖解(如何加速Attention) - 知乎 (zhihu.com)
- NLP(十七):從 FlashAttention 到 PagedAttention, 如何進一步優化 Attention 性能 - 知乎 (zhihu.com)
- LLaMA2上下文長度暴漲至100萬tokens,只需調整1個超參數 (baidu.com)
- Flash Decoder
To Do: Mixed Model: short term transformer, long term Mamba
Takeaway
- 使用 computation to trade-off memory bandwidth!
Long Context 定義: “Train Short, Test Long”。
此處 long context 都是指 train short, test long. 這也是實際的狀況。
如果要用 128K 或是 1M context 來 train model, 大概率不可能找到這麽長的 datasets! 注意,不是只有一筆 data 128K or 1M, 是幾 T 或百 T 的資料都要 128K or 1M. 而且 training cost 大概沒有誰能負擔。
所以還是只能用現有的 data train.
Why Long Context
最早的大語言模型 (ChatGPT2/3, Llama) 的 context length 只有 768/1K/2K tokens. 在應用爲什麼大語言模型需要 long context (8K or longer)? 簡單說有兩點
- 處理長文本輸入。例如一篇長的文章做 summary.
- 對話的記憶長度。例如長的對話有上下文的 context. Question and Answering
- 對於 RAG 也需要 long context
- Multimodality input (image and video) 更需要 long context.
因此實務上,long context (4K/8K or longer) 對於應用非常有用。
How to Make Long Context
先説結論: Training 容易 (RoPE), Inference 難 (平方難度)!
- training 還是用 1K/2K dataset dataset and model 訓練,只要小改 model.
- inference 是實打實要計算之前 context 的 attention,計算量和 context length 成平方比,memory 也是! 不過有很多 techniques to reduce the complexity.
分成兩部分
-
Training: 直接用原來的 1K/2K dataset, 小改就可以處理 4K-32K context or longer
-
RoPE - Rotation Position Encoder, 只改 position encoder, 原來 1K/2K LLM model 的參數都不改。最簡單好用。
-
Fine-tune 原來的 1K/2K model.
-
更複雜的 solution: Page retrieval: Llama-long
-
-
**Inference: **
前面只是說 LLM 可以當作是用 128K / 1M train 過的 model. 但是 long context 的 128K 或是 1M 的 attention 還是要算啊!又不是卜卦,如果沒有之前的 attention score and value, 如何能實現 long context!!
因此 long context inference 內部的計算和 activation 的 cache size 不需要增加? too good to be true!!!!**
- GQA (algorithm)
- Sliding Window Attention (SWA)
- SteamingLLM (Attention Sink)
- Hyper Attention
- Cache compression, H2O (algorithm)
- Flash decoder (software optimization)
Training: Fine-tune instead of pre-train
這部分直接引用科學空間!
問題定義(https://spaces.ac.cn/archives/9948#)
顧名思義,免訓練長度外推,就是不需要用長序列數據進行額外的訓練,只用短序列語料對模型進行訓練,就可以得到一個能夠處理和預測長序列的模型,即“Train Short, Test Long”。那麼如何判斷一個模型能否用於長序列呢?最基本的指標就是模型的長序列Loss或者PPL不會爆炸,更加符合實踐的評測則是輸入足夠長的Context,讓模型去預測答案,然後跟真實答案做對比,算BLEU、ROUGE等,LongBench就是就屬於這類榜單。
但要注意的是,長度外推應當不以犧牲遠程依賴爲代價——否則考慮長度外推就沒有意義了,倒不如直接截斷文本——這意味着通過顯式地截斷遠程依賴的方案都需要謹慎選擇,比如ALIBI以及《Transformer升級之路:7、長度外推性與局部注意力》所列舉的大部分方案,還有帶顯式Decay的線性RNN,這些方案當序列長度足夠大時都表現爲局部注意力,即便有可能實現長度外推,也會有遠程依賴不足的風險,需要根據自己的場景斟酌使用。
如何判斷在長度外推的同時有沒有損失遠程依賴呢?比較嚴謹的是像《Transformer升級之路:12、無限外推的ReRoPE?》最後提出的評測方案,準備足夠長的文本,但每個模型只算每個樣本最後一段的指標,如下圖所示:

一種關注遠程依賴的評測方式
比如,模型訓練長度是4K,想要看外推到16K的效果,那麼我們準備一個16K tokens的測試集,4K的模型輸入每個樣本最後4K tokens算指標,8K模型輸入每個樣本最後8K tokens但只算最後4K tokens算指標,12K模型輸入每個樣本最後12K tokens但只算最後4K tokens算指標;依此類推。這樣一來,不同長度的模型算的都是同一段tokens的指標,不同的只是輸入的Context不一樣,如果遠程依賴得以有效保留,那麼應該能做到Context越長,指標越好。
旋轉位置 #
談完評測,我們回到方法上。文章開頭我們提到“舊的分析工作”,這裏“新”、“舊”的一個主要特點是“舊”工作多數試圖自行設置新的架構或者位置編碼來實現長度外推,而最近一年來的“新”工作主要是研究帶旋轉位置編碼(RoPE)的、Decoder-Only的Transformer模型的長度外推。
先說個題外話,爲什麼如今大部分LLM的位置編碼都選擇了RoPE呢?筆者認爲主要有幾點原因:
1、RoPE不帶有顯式的遠程衰減,這對於旨在Long Context的模型至關重要;
2、RoPE是一種真正的位置編碼,通過不同頻率的三角函數有效區分了長程和短程,達到了類似層次位置編碼的效果,這也是Long Context中比較關鍵的一環;
3、RoPE直接作用於Q、K,不改變Attention的形式,與Flash Attention更契合,更容易Scale Up。
相比之下,諸如ALIBI、KERPLE等,雖然有時也稱爲位置編碼,但它們實際上只是一種Attention Bias,沒有太多位置信息,且不適用於Encoder,能用於Decoder大體上是因爲Decoder本身的下三角Mask就已經有較爲充分的位置Bias了,額外的Attention Bias只是錦上添花。此外它們無法在單個頭內有效區分長程和短程,而是要通過在不同頭設置不同的Decay因子來實現,這也意味着它們用於單頭注意力(比如GAU)的效果會欠佳。
窗口截斷 (Inference!) #
上兩節的內容主要是想表達的觀點是:目前看來,RoPE對於Long Context來說是足夠的,所以研究RoPE的長度外推是有價值的,以及我們在選擇長度外推方案時,不應犧牲遠程依賴的能力。
在最早討論長度外推的《Transformer升級之路:7、長度外推性與局部注意力》一文中,我們判斷長度外推是一個預測階段的OOD(Out Of Distribution)的問題,儘管用今天的視角看,這篇文章的一些評述已經顯得有點過時,但這個根本判斷是依然還算正確,放到RoPE中,就是推理階段出現了沒見過的相對距離。爲此,一個看上去可行的方案是引入Sliding Window的Attention Mask,如下圖左所示:

Sliding Window Mask

Λ-shape Window Mask
當然,由於強行截斷了窗口外的注意力,所以這個方案並不滿足“不犧牲遠程依賴的能力”的原則,但我們可以只將它作爲一個Baseline看待。很遺憾的是,即便做出瞭如此犧牲,這個方案卻是不Work的——連最基本的PPL不爆炸都做不到!對這個現象的深入分析,先後誕生《LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models》和《Efficient Streaming Language Models with Attention Sinks》兩篇論文,並給出了幾乎一樣的答案。但事實上,在更早的幾個月前,一位“業外人士”就發現了相同的結論,並發表在知乎專欄文章《Perpetual Sampling Technical Report》上。
答案可能讓人意外:開頭的幾個Token很重要,不能扔掉。所以最後可用的Window Mask應該如上圖右(LM-Infinite這篇論文管它叫“ΛΛ-Mask”)。
爲什麼開頭的Token會佔據如此重要的地位呢?目前有兩個不同的理解角度:
1、開頭的幾個Token是絕對位置的“錨點”:顧名思義,相對位置編碼原則上只能識別相對位置,但有些任務可能比較依賴絕對位置,通過開頭幾個絕對位置約等於0的Token作爲“標的”,每個Token就能夠測出自己的絕對位置,而去掉開頭幾個Token後則缺失了這一環,從而完全打亂了注意力模式導致PPL爆炸;
2、開頭的幾個Token是注意力的“回收站”:由於注意力求和爲1,所以注意力一定會分配到某些Token上,但有些情況下模型可能會發現“沒什麼Token值得注意的”,這時它選擇將一部分注意力放到沒什麼信息量的前幾個Token上,起到“不注意”的作用,去掉它們後模型會強行將注意力分配到其他無關的Token,從而擾亂了注意力模式。
其實說白了,就是實測發現大部分情況下,前幾個Token的注意力佔比還是很重的,所以不能去掉,去掉注意力就全亂了。至於爲什麼很重,就看大家的想象力了。
PE 部分:Transformer升级之路:16、“复盘”长度外推技术 - 科学空间|Scientific Spaces
RoPE (Rotation PE) + flash attention : simpler than fine-tune
https://www.youtube.com/watch?v=UPYf3jxcMVY&ab_channel=1littlecoder
LLaMA2上下文長度暴漲至100萬tokens,只需調整1個超參數 (baidu.com)
目前的Transformer位置編碼方法,有絕對位置編碼(將位置信息融入到輸入)、相對位置編碼(將位置信息寫入attention分數計算)和旋轉位置編碼幾種。其中,最火熱的要屬旋轉位置編碼,也就是RoPE了。
RoPE通過絕對位置編碼的形式,實現了相對位置編碼的效果,但與相對位置編碼相比,又能更好地提升大模型的外推潛力。
如何進一步激發採用RoPE位置編碼的大模型的外推能力,也成爲了最近不少研究的新方向。
這些研究,又主要分爲限制注意力和調整旋轉角兩大流派。
限制注意力的代表研究包括ALiBi、xPos、BCA等。最近MIT提出的StreamingLLM,可以讓大模型實現無限的輸入長度(但並不增加上下文窗口長度),就屬於這一方向的研究類型。
調整旋轉角的工作則更多,典型代表如線性內插、Giraffe、Code LLaMA、LLaMA2 Long等都屬於這一類型的研究。
以Meta最近爆火的LLaMA2 Long研究爲例,它就提出了一個名叫RoPE ABF的方法,通過修改一個超參數,成功將大模型的上下文長度延長到3.2萬tokens。
這個超參數,正是Code LLaMA和LLaMA2 Long等研究找出的“開關”——
旋轉角底數(base)。
只需要微調它,就可以確保提升大模型的外推表現。
但無論是Code LLaMA還是LLaMA2 Long,都只是在特定的base和續訓長度上進行微調,使得其外推能力增強。
是否能找到一種規律,確保所有用了RoPE位置編碼的大模型,都能穩定提升外推表現?
來自復旦大學和上海AI研究院的研究人員,針對這一問題進行了實驗。
他們先是分析了影響RoPE外推能力的幾種參數,提出了一種名叫臨界維度(Critical Dimension)的概念,隨後基於這一概念,總結出了一套RoPE外推的縮放法則(Scaling Laws of RoPE-based Extrapolation)。
只需要應用這個規律,就能確保任意基於RoPE位置編碼大模型都能改善外推能力。
先來看看臨界維度是什麼。
對此論文認爲,旋轉角底數更小,能讓更多的維度感知到位置信息,旋轉角底數更大,則能表示出更長的位置信息。
基於這一規律,可以根據不同預訓練和續訓文本長度,來直接計算出大模型的外推表現,換言之就是預測大模型的支持的上下文長度。
反之利用這一法則,也能快速推導出如何最好地調整旋轉角底數,從而提升大模型外推表現。
作者針對這一系列任務進行了測試,發現實驗上目前輸入10萬、50萬甚至100萬tokens長度,都可以保證,無需額外注意力限制即可實現外推。
與此同時,包括Code LLaMA和LLaMA2 Long在內的大模型外推能力增強工作都證明了這一規律是確實合理有效的。
這樣一來,只需要根據這個規律“調個參”,就能輕鬆擴展基於RoPE的大模型上下文窗口長度、增強外推能力了。
Naive Training (Never Happen)
最簡單的方法就是設定長的 input token length, 就是以下的 $n_{ctx}$ 例如從 1K/2K 改成 4K/8K/16K/32K/128K/1M. 最大問題:
- Dataset!
- Training cost!
- Model 的 parameter number 並沒有隨著 $n_{ctx}$ 而增加!只有在 查字典和 position encoder 增加一些 parameter 。 -> good things 如果我們知道如何 fine-tune 原來的 model 就可以從 1K/2K to 4K-32K!!!!! 不過要修改 position encoder!!!
- 但是 internal matrix computation 隨著 $n_{ctx}$ 呈現平方增加。
- cache size (of activations) 隨著 $n_{ctx}$ 呈現綫性增加。
另外的問題是需要從新訓練 LLM 使用更長的 context. 例如從目前 Llama2-7B 只有 2K context, 如果要更長 context 就需要從新用更長的 text training. Big effort to train from scratch!!!
Long Context Inference Key
Transformer 包含兩個部分:MHA (Multi-Head Attention) 和 FF (Feed-Forward).
Based on Karpathy’s interpretation:
- MHA 是 token-to-token communication: 基本和 context 長度成平方比例
- FF 是 inside token 的 computation: 和 context 長度無關
所以 long context 主要的 optimization 就是如何減少 attention 部分!
Inference: Reduce computation and activation
1. Cache size optimization
就是使用 KV cache + flash decoder? to break the 32K into 2K + 2K …. chunks?
#####
應該是減少 heads, 或是多個 heads 共享同一個 weights?
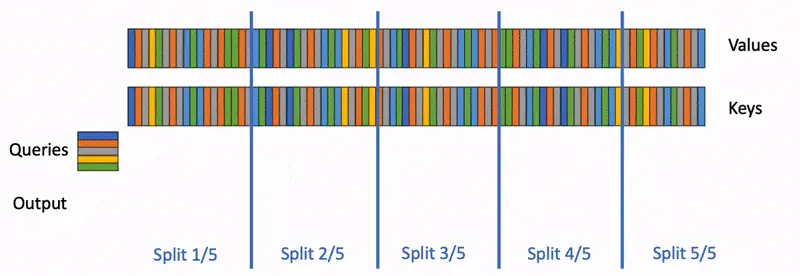
Flash Decoder
FlashAttenion-V3: Flash Decoding詳解 - 知乎 (zhihu.com)