Source
-
Sheared Llama https://arxiv.org/pdf/2310.06694.pdf
-
SparseGPT
Takeaway
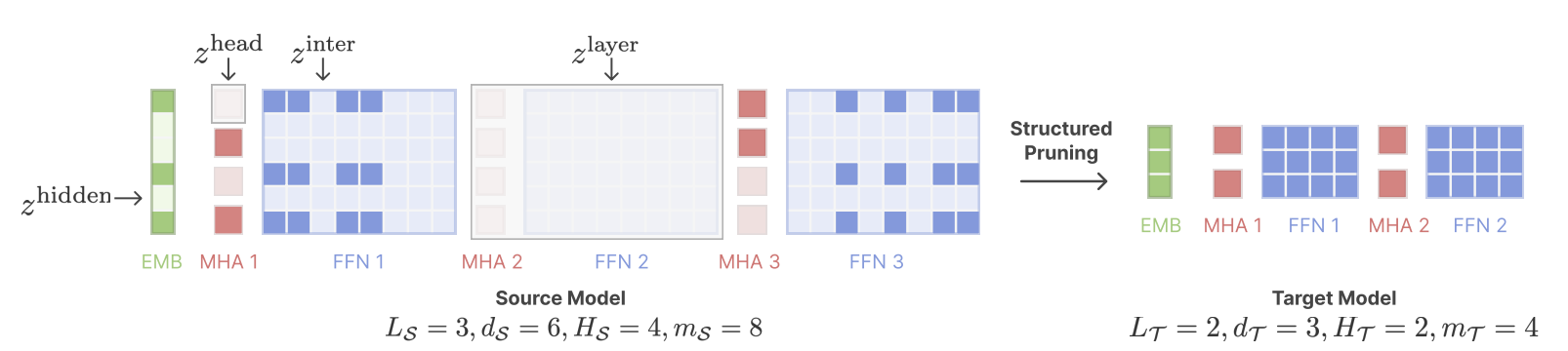
- Attention parameters (1/3) and FFN (2/3)
- FFN 一般可以 prune
- Attention 的 multi-heads 可以 prune
Attention is what you need, Memory is the Bottleneck
Attention 已經是必備的 core network. 相較於 CNN, attention 最大的問題是 memory bandwidth.
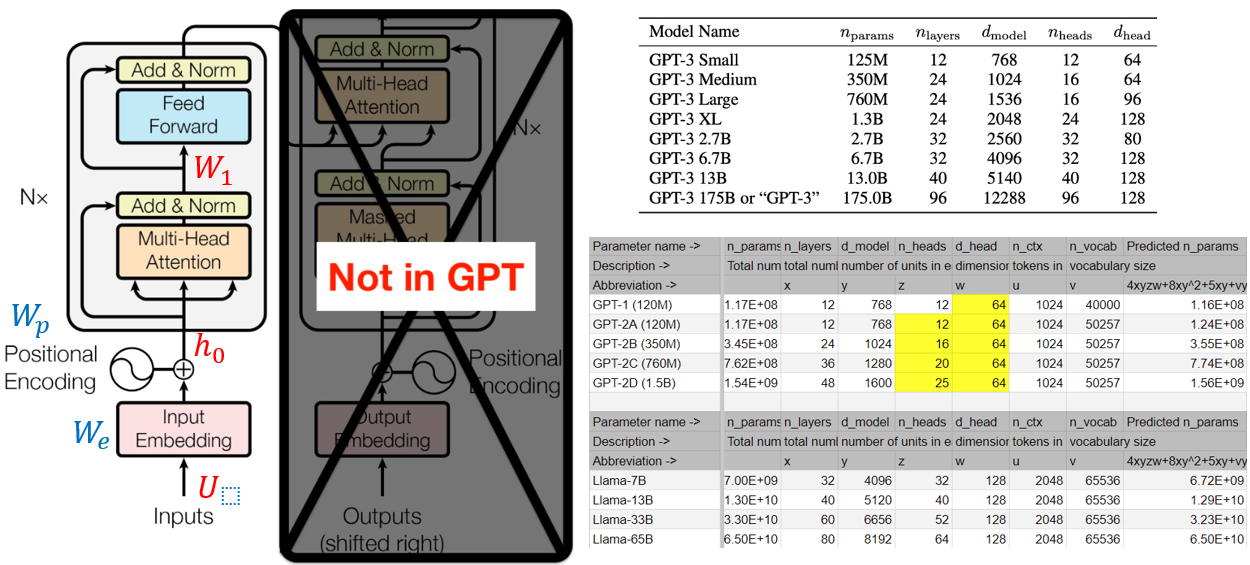
主要在計算 K, Q 的 correlation, 以及 softmax. 以下是 GPT1/2/3 的參數。
下圖應該畫錯了! GPT 應該是 decoder only (右邊)。所以對應的方塊圖是沒有 encoder (左邊),只有 decoder (右邊)。所以打叉的地方相反。BERT 纔是 encoder only (左邊)。不過兩者的架構非常類似。不過 decoder only 架構 output 會 shift right 再接回 input, 稱爲 auto-regression.
Why Long Context
最早的大語言模型 (ChatGPT2/3, Llama) 的 context length 只有 768/1K/2K tokens. 在應用爲什麼大語言模型需要 long context (8K or longer)? 簡單說有兩點
- 處理長文本輸入。例如一篇長的文章做 summary.
- 對話的記憶長度。例如長的對話有上下文的 context. Question and Answering
因此實務上,long context (4K/8K or longer) 對於應用非常有用。
How to Make Long Context
Naïve Way
最簡單的方法就是設定長的 input token length, 就是以下的 $n_{ctx}$ 例如從 1K/2K 改成 4K/8K/16K/32K. 幾個問題:
- 整體的 parameter number 並沒有隨著 $n_{ctx}$ 而增加!只有在 查字典和 position encoder 增加一些 parameter 。 -> good things 如果我們知道如何 fine-tune 原來的 model 就可以從 1K/2K to 4K-32K!!!!! 不過要修改 position encoder!!!
- 但是 internal matrix computation 隨著 $n_{ctx}$ 呈現綫性增加。
- cache size (of activations) 隨著 $n_{ctx}$ 呈現綫性增加。
另外的問題是需要從新訓練 LLM 使用更長的 context. 例如從目前 Llama2-7B 只有 2K context, 如果要更長 context 就需要從新用更長的 text training. Big effort to train from scratch!!!
Ideal Goal
是否有方法
- 只要 fine-tune 原來的 1K/2K 的 LLM model parameter 就可以改成 4K-32K, 不過要修改 position encoder.
- 最好內部的計算和 activation 的 cache size 不需要增加? too good to be true!!!!
Address Goal 1 (Fine-tune instead of pre-train)
1. Fine-tune use 32K
2. RoPE (Rotation PE) + flash attention : simpler than fine-tune
https://www.youtube.com/watch?v=UPYf3jxcMVY&ab_channel=1littlecoder
LLaMA2上下文長度暴漲至100萬tokens,只需調整1個超參數 (baidu.com)
目前的Transformer位置編碼方法,有絕對位置編碼(將位置信息融入到輸入)、相對位置編碼(將位置信息寫入attention分數計算)和旋轉位置編碼幾種。其中,最火熱的要屬旋轉位置編碼,也就是RoPE了。
RoPE通過絕對位置編碼的形式,實現了相對位置編碼的效果,但與相對位置編碼相比,又能更好地提升大模型的外推潛力。
如何進一步激發採用RoPE位置編碼的大模型的外推能力,也成爲了最近不少研究的新方向。
這些研究,又主要分爲限制注意力和調整旋轉角兩大流派。
限制注意力的代表研究包括ALiBi、xPos、BCA等。最近MIT提出的StreamingLLM,可以讓大模型實現無限的輸入長度(但並不增加上下文窗口長度),就屬於這一方向的研究類型。
調整旋轉角的工作則更多,典型代表如線性內插、Giraffe、Code LLaMA、LLaMA2 Long等都屬於這一類型的研究。
以Meta最近爆火的LLaMA2 Long研究爲例,它就提出了一個名叫RoPE ABF的方法,通過修改一個超參數,成功將大模型的上下文長度延長到3.2萬tokens。
這個超參數,正是Code LLaMA和LLaMA2 Long等研究找出的“開關”——
旋轉角底數(base)。
只需要微調它,就可以確保提升大模型的外推表現。
但無論是Code LLaMA還是LLaMA2 Long,都只是在特定的base和續訓長度上進行微調,使得其外推能力增強。
是否能找到一種規律,確保所有用了RoPE位置編碼的大模型,都能穩定提升外推表現?
來自復旦大學和上海AI研究院的研究人員,針對這一問題進行了實驗。
他們先是分析了影響RoPE外推能力的幾種參數,提出了一種名叫臨界維度(Critical Dimension)的概念,隨後基於這一概念,總結出了一套RoPE外推的縮放法則(Scaling Laws of RoPE-based Extrapolation)。
只需要應用這個規律,就能確保任意基於RoPE位置編碼大模型都能改善外推能力。
先來看看臨界維度是什麼。
對此論文認爲,旋轉角底數更小,能讓更多的維度感知到位置信息,旋轉角底數更大,則能表示出更長的位置信息。
基於這一規律,可以根據不同預訓練和續訓文本長度,來直接計算出大模型的外推表現,換言之就是預測大模型的支持的上下文長度。
反之利用這一法則,也能快速推導出如何最好地調整旋轉角底數,從而提升大模型外推表現。
作者針對這一系列任務進行了測試,發現實驗上目前輸入10萬、50萬甚至100萬tokens長度,都可以保證,無需額外注意力限制即可實現外推。
與此同時,包括Code LLaMA和LLaMA2 Long在內的大模型外推能力增強工作都證明了這一規律是確實合理有效的。
這樣一來,只需要根據這個規律“調個參”,就能輕鬆擴展基於RoPE的大模型上下文窗口長度、增強外推能力了。
Address Goal 2 (Reduce computation and activation)
1. Cache size optimization
就是使用 KV cache + flash decoder? to break the 32K into 2K + 2K …. chunks?
2. MGQ (Multiple Group Query)
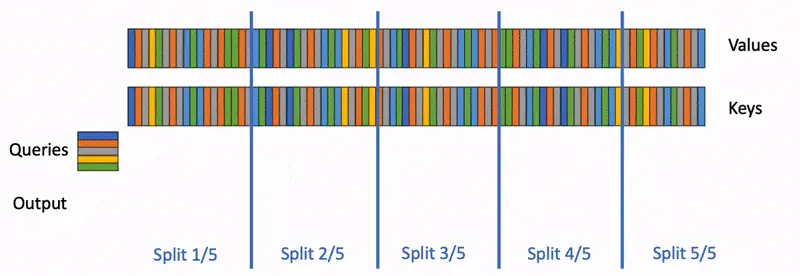
應該是減少 heads, 或是多個 heads 共享同一個 weights?
Flash Decoder
FlashAttenion-V3: Flash Decoding詳解 - 知乎 (zhihu.com)