Source
Takeaway
- LLM 基本包含兩個檔案:
- Llama2.cpp : 執行 Llama2 model (graph). 這個 file 需要編譯,但是和 7B/13B/70B 無關。
- Llama2.pth: 實際 Llama2 weights, 包含 7B/13B/70B. 不需要編譯,但是需要轉換成 FP16 (bin), 或是 INT8?, HF 格式。
編譯 Llama.cpp on Windows 利用 WSL2 Ubuntu
主要對 llama.cpp 項目進行編譯,生成 main 和 quantize 的執行檔。
在 windows 先用 bash 換到 WSL2 Ubuntu OS
1 | |
這個 github 稱爲 llama.cpp github.
下載 Llama2 7B/13B/70B 模型的 weights (應該沒有 network graph?)
到 Meta 的 Github 做 git clone. https://github.com/facebookresearch/llama
要下載模型必須要 request meta,然後執行下載
這個 github 稱爲 llama github
1 | |
貼上 email 中的 URL link. (注意:超過 24 小時會失效,需要重新申請)
Llama(1) 有四個 models: 7B/13B/33B/65B. 不過 Llama2 取消了 33B 模型 (改成 code llama),65B 模型改成 70B models.
可以選擇 download Llama2 三個 parameter size: 7B/13B/70B. 每個 parameter size 都有兩個models.
- 一個是 Pretrained base model: 沒有 fine-tune, 只會做文字接龍;
- 另一個是 Fine-tuned chat model: 經過 fine-tune, 可以作爲 chat-bot. Karpathy 在 introduction 做了很好的説明。
Meta 還提供一個 code-llama model (34B), 這應該是原來 Llama 33B 經過 fine-tuned 成爲 34B 的 code model.
Meta 下載的格式是 .pth (PyTorcH).
每個 pth 檔案大小約 13-17GB. llama-7B 只要一個 pth (13GB). llama-13B 需要兩個 pth (13GBx2=26GB). llama-70B 有 8 個 pth file (17GBx8=136GB)
- 基本是 2-byte per parameter. 應該是 FP16? Appendix 解釋各個不同量化格式。
回到原來 llama.cpp git hub:
Convert pth file to gguf (FP16) 格式:
1 | |
主要是把 llama-2-7b 内的 pth 檔案,配合 params.json 轉換成 FP16 ggml 格式。
- 注意如果有 vocab_size mismatch: 修改 params.json 的 vocab_size accordingly!!!
- ggml: Georgi Gerganov Machine Learning?
- gguf: Gerogi Gergnanov Unified Format
Convert pth file to hf (HuggingFace, FP16) 格式
1 | |
經過複雜的過程: 1. git clone transformers; 2. pip install xxx; 3. modify code; 4. copy tokenizer.model ..
最後終於 convert 出。
Quantize!
1 | |
檔案結構和格式
1 | |
以下比較這些檔案的大小
| Llama2 | pth size (FP16?) | gguf size (FP16) | Quantized gguf size (INT4?) |
|---|---|---|---|
| 7B-Chat | 13 GB | 13 GB | 3.6 GB |
| 13B-Chat | 13x2 = 26 GB | 24.8 GB | 7.0 GB |
| 70B-Chat | 17GBx8=136GB | 132 GB | 37 GB |
Perplexity?
Command Lin Inference
簡單使用方式用 command line.
1 | |
1 | |
- -m
: quantized model - -f
: prompt 的格式 - -n 256: set the number of tokens to predict when generating text.
- -r: display 格式
- -c: n_ctx, context length. The default is 512
- -i: interactive mode.
- -ins: instruction mode, which is particularly useful when working with Alpaca models.
- –temp ## : default 0.8, temperature, to adjust the randomness of the generated text
- –color: to distinguish between user input and generated text.
- –repeat_penalty ## (default: 1.1): control the repetition of token sequences in the generated text.
Python Use LLM
以上是 command line 的使用方法。
首先用簡單的例子,使用 torchrun
1 | |
再來是直接從 python program 呼叫。
Run LLMs on Your CPU with Llama.cpp: A Step-by-Step Guide (awinml.github.io)
1 | |
Appendix
大语言模型量化方法对比:GPTQ、GGUF (old GGML)、AWQ, HF (Hugging Face)
大型语言模型由一堆权重和激活表示。这些值通常由通常的32位浮点(float32)数据类型表示。
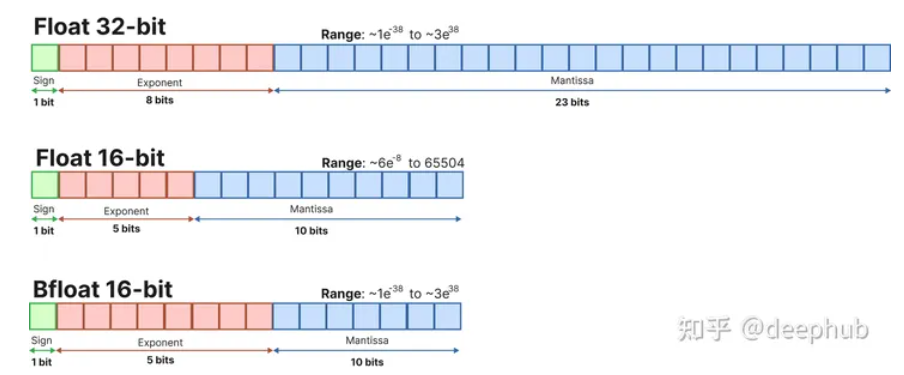
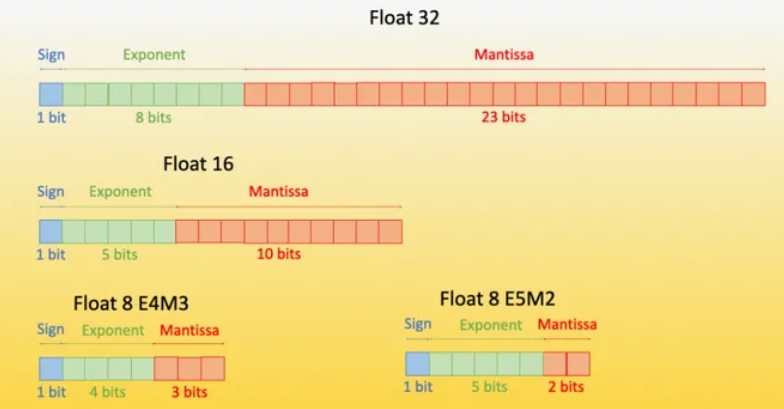
4-bit 量化
INT4, FP4, NF4
INT4 trivial
FP4 精度简述
A: {E3M0, E2M1, E1M2}
B:
- Sign bit (1): 符号位表示符号 (+/-),
- Exponent (2): 指数位以两位表示的整数次方为底数(例如
2^{010} = 2^{2} = 4), - Mantiss (4?): 分数或尾数是“有效”的负二的幂之和对于每个为“1”的位。如果某个位是“0”,则分数保持不变,其中
2^-ii 是该位在位序列中的位置。例如,对于尾数位 1010,我们有(0 + 2^-1 + 0 + 2^-3) = (0.5 + 0.125) = 0.625. 为了得到一个值,我们将分数加1并将所有结果相乘,例如,使用 2 个指数位和一个尾数位,表示 1101 将是:
1 | |
对于 FP4 没有固定的格式,因此可以尝试不同尾数/指数组合的组合。通常,在大多数情况下,3 个指数位会好一些。但有时 2 个指数位和一个尾数位会产生更好的性能。
NF4
1)NF4 Quantization(4bit量化):一种新的int4量化方法,灵感来自信息论。NF4量化可以保证量化后的数据和量化前具有同等的数据分布。意思就是NF4量化后,权重信息损失少,那么最后模型的整体精度就损失少。
PS:1)疑问:int4量化和NF4量化的区别?。这里个人理解
它包括三个步骤:
归一化:将模型的权重归一化,以便我们期望权重落在一定范围内。这允许更有效地表示更常见的值。
量化:将权重量化为4位。在NF4中,量化级别相对于归一化权重是均匀间隔的,从而有效地表示原始的32位权重。
去量化:虽然权重以4位存储,但它们在计算期间被去量化,从而在推理期间提高性能。
NF4量化使用的核心函数标准正态分布(N(0,1)),参考信息论的方法,能保证量化后精度损失少。而int4量化和之前的fp16,int8量化都沿用的是线性量化(y=kx+b)的方式,特别是int8, int4量化后的很多模型精度损失严重
2)研究者发现在自己提出的QLORA Finetuning 技术方案中,使用默认的LoRA参数时,NF4训练达不到BF16的评估指标。
3)NF4量化优于(FP4和int4)量化的性能,意思就是本文提出的NF4量化技术比之前的标准int4量化技术带来的精度损失少。并且NF4量化+二次量化减少存储的同时,精度并未下降。
4)NF4量化+二次量化的方案finetune的模型精度可以媲美BFloat 16。
预量化(GPTQ、AWQ、GGUF)
但是量化是在每次加载模型时进行的,这是非常耗时的操作,有没有办法直接保存量化后的模型,并且在使用时直接加载呢?
TheBloke是HuggingFace上的一个用户,它为我们执行了一系列量化操作,我想用过大模型的人一定对它非常的熟悉吧
1、GPTQ: Post-Training Quantization for GPT Models
GPTQ是一种4位量化的训练后量化(PTQ)方法,主要关注GPU推理和性能。
该方法背后的思想是,尝试通过最小化该权重的均方误差将所有权重压缩到4位。在推理过程中,它将动态地将其权重去量化为float16,以提高性能,同时保持低内存。
尽管我们安装了一些额外的依赖项,但我们可以使用与之前相同的管道,也就是是不需要修改代码,这是使用GPTQ的一大好处。
GPTQ是最常用的压缩方法,因为它针对GPU使用进行了优化。但是如果你的GPU无法处理如此大的模型,那么从GPTQ开始切换到以cpu为中心的方法(如GGUF)是绝对值得的。
2、GPT-Generated Unified Format
尽管GPTQ在压缩方面做得很好,但如果没有运行它的硬件,那么就需要使用其他的方法。
GGUF(以前称为GGML)是一种量化方法,允许用户使用CPU来运行LLM,但也可以将其某些层加载到GPU以提高速度。
虽然使用CPU进行推理通常比使用GPU慢,但对于那些在CPU或苹果设备上运行模型的人来说,这是一种非常好的格式。
如果你想同时利用CPU和GPU, GGUF是一个非常好的格式。
3、AWQ: Activation-aware Weight Quantization
除了上面两种以外,一种新格式是AWQ(激活感知权重量化),它是一种类似于GPTQ的量化方法。AWQ和GPTQ作为方法有几个不同之处,但最重要的是AWQ假设并非所有权重对LLM的性能都同等重要。
也就是说在量化过程中会跳过一小部分权重,这有助于减轻量化损失。所以他们的论文提到了与GPTQ相比的可以由显著加速,同时保持了相似的,有时甚至更好的性能。
该方法还是比较新的,还没有被采用到GPTQ和GGUF的程度。
Reference
大语言模型量化方法对比:GPTQ、GGUF、AWQ - 知乎 (zhihu.com)
QLoRA——技术方案总结篇 - 知乎 (zhihu.com)
[@guodongLLMTokenizer2023]