Source
- What is Retrieval Augmented Generation (RAG) https://www.youtube.com/watch?v=T-D1OfcDW1M
Takeaway
- LLM 是唬爛 (hallucination) 大師,自己非常相信 generate 出來的東西。有兩個問題 : (1) 沒有信源; (2) LLM training dateset 可能 out-of-date.
- 一個方法是 RAG, 就是在 prompt 給 LLM 之前,先 query credible source (e.g. NASA for space related question, NY times for latest news), 再把 retrieval information augment to prompt, 再送給 LLM. 此時有兩個好處 (1) 有 credible 信源頭; (2) information 是 up-to-date.
- 這和 AutoGPT 有什麼差異? AutoGPT 是 LLM 決定是否要 (或者不要) search internet, 以及 search 那些 website. 比較不確定,也無法保證 search 結果是否正確或是 up-to-date。
- 這和 cloud-edge collaborative approach 有什麼關係? 三種模式:
- Cloud large LLM, Edge small LLM: prompt to both large LLM and small LLM. 以 cloud LLM 為 golden. Edge LLM 只是快但不一定正確 answer. 可以用 cloud answer 再修正或是 train edge LLM
- Cloud large LLM, Edge small LLM: prompt to the small LLM first. Small LLM 決定是否要 pass to cloud LLM. 好處是: 快 and cost saving, 也有機會 train edge LLM. 但是 edge LLM 自己是唬爛大師,不知道自己不知道 (don’t know what don’t know). 可能小錯 (cloud LLM) 加大錯 (edge LLM)
- Cloud credible source or database, edge small LLM with RAG. 好處是: 準確, 如果網路快,query credible source 可能又快又省,不用 cloud LLM. Edge LLM 的準確度可能大增!
| LLM only (cloud or edge) | Cloud+Edge LLM post arbitration |
Cloud+Edge LLM pre arbitration |
Cloud info+ edge LLM RAG |
Cloud info+ edge AutoGPT |
|
|---|---|---|---|---|---|
| Accuracy | 1. Based of pre-trained knowledge, could be out-of-date. 2. Hallucination without credible source |
1. Based of pre-trained knowledge, could be out-of-date. 2. Hallucination without credible source |
Worst. Edge LLM error + cloud LLM error |
High | Med-High |
| Cost | Edge:low; Cloud:high | High | Medium | Low | Med |
| Latency | Edge: fast; Cloud: slow | Fast | Fast | Slow? | Slow |
| Self-improve | You don’t know you don’t know. Ceiling: cloud LLM |
Yes, use cloud LLM fine-tune edge LLM |
Maybe | Yes | Maybe |
Source
-
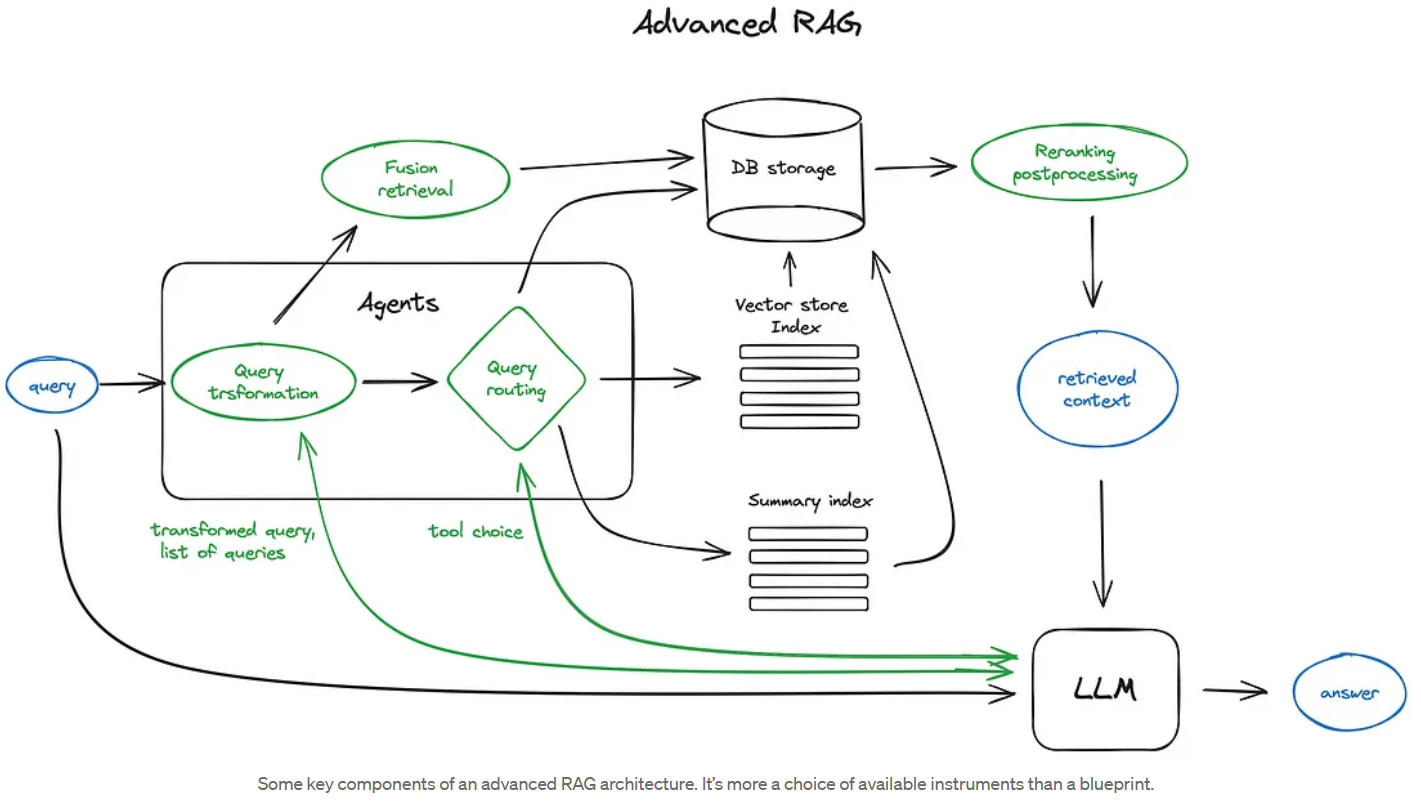
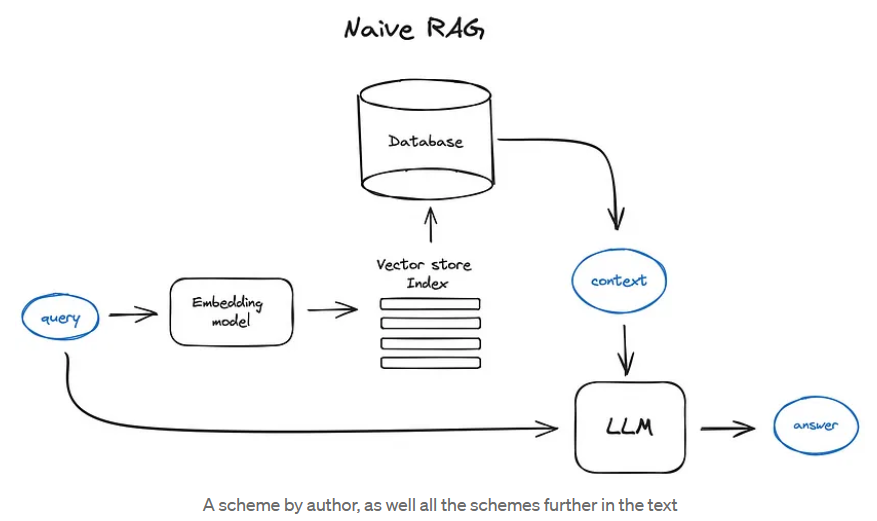
[Advanced RAG Techniques: an Illustrated Overview by IVAN ILIN Dec, 2023 Towards AI](https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6) - 百川
RAG
Vanilla RAG case in brief looks the following way: you split your texts into chunks, then you embed these chunks into vectors with some Transformer Encoder model, you put all those vectors into an index and finally you create a prompt for an LLM that tells the model to answers user’s query given the context we found on the search step. In the runtime we vectorise user’s query with the same Encoder model and then execute search of this query vector against the index, find the top-k results, retrieve the corresponding text chunks from our database and feed them into the LLM prompt as context.
The prompt can look like:
1 | |
Advanced RAG