Source
-
https://juejin.cn/post/7234795667477561402
-
https://zhuanlan.zhihu.com/p/424631681
-
https://zhuanlan.zhihu.com/p/654745411
-
Excellent YouTube video from Karpathy: https://www.youtube.com/watch?v=zduSFxRajkE&t=505s
開場
之前在中文語言模型時,遇到分詞的問題。以爲分詞是中文獨有的問題。因爲英文(或是整個西方語言)都可以用 space 和標點符號做爲“分詞”或是“分字”。不過到了大語言模型 (LLM) 的時代,“分詞” (Tokenizer) 變成西語重要的工具。不過中文的分詞和西語的分字還是有所不同。
在学习这些语言模型的时候,各位有没有去注意他们的编码方式,也就是NLP预训练时的tokenization呢?我们都了解一种最基本的tokenization, 也就是把每一个单词看成一个token,然后对其进行编号。这种编码方式十分符合人类语言习惯,因为人类语言也经常以单词为单位进行交流,但这并不一定是最合理的编码方式。對於西語很容易分詞,只要利用 space 和標點符號。但對於中文就要額外分詞處理。
我们知道,一门语言中,通常有几万到几十万量级的单词数。若使用这种编码方式,在语言模型预测的时候需要在这个拥有几万个单词的列表上计算一个概率分布,那样的计算量是非常恐怖的,而且过大的token列表十分影响模型的预测准确度。在GPT-3提出以后,又增加了prompt的feature,其特点之一就是用户可以指定将源语言翻译成某一种语言。举个例子,若是我们输入:
English: Let’s have a drink tonight.
French:
模型就能输出一句与”Let’s have a drink tonight.”所对应的法语翻译。要是”French:”改成”Spanish:”,那模型将输出对应的西班牙语翻译。随着模型集成的不同国家的语言越来越多,模型的词汇列表势必会增长到一个非常可怕的数量级,到时候该如何去处理它带来的矩阵内存占用和预测准确性问题呢?
Naive method: Character Encoding
第一個方法可以答復減小 token list 就是用英文(以及變異字母)大小寫字母加上標點符號為 tokens。大約 60 個 tokens. 看起來很完美,但是有兩個問題:
- 一篇 1000 英文字的文章需要 4000-5000 tokens (假設一個英文字平均要 4-5 字母)。顯然太長了,對於大語言模型需要 4 到 5 倍的上下文處理能力。也就是更多的内存和處理速度。但這對於可以處理無限長序列的 model, 像是 Mamba 可能不是問題,例如 Mambabyte 不需要任何 tokenizer. 反而可以從 raw data 學習 tokenizer.
- 以字母為 token 直接丟失字母之間的資訊。代表之後的大模型需要學習這些資訊。也就是大模型要處理更多的資訊。
Byte Pair Encoding (BPE)
第二种编码方式能大大减小token list,那就是本文即将介绍的Byte Pair Encoding(BPE),也是NLP中最重要的编码方式之一,它的有效性也被GPT-2, RoBERTa, XLM, FlauBERT等这些最强大的语言模型所证实。
| Letter | Word | Subword, BPE | 中文單字 | 中文詞 | |
|---|---|---|---|---|---|
| 顆粒度 | 一個字母 | 一個單字 | 約半個單字 | 一個中文字 (2-byte Unicode-16) | 1-4 個中文字, 詞 |
| Token size | 50~100 = 7bits | 100K~1M = 20bits | 20K~60K = 16bits | ~20K | ~50K |
| 100 words token length | 400-500 | 100 | 200 | 100 | 80 |
| Entropy | <log2(100) = 6.6bits | log2(1M)/4 = 5 bits | log2(60K)/3 = 5.2 bits? smaller |
從廣義來看,整個大語言模型可以視爲一個大的壓縮機器,把所有的知識 (Tera tokens) 凝縮在幾十億的參數内。
大語言模型的第一步就是 tokenizer. 可以視爲壓縮的第一步。
下面介紹 BPE 和其變形。下圖是很好的 summary.

初识BPE
BPE 是一种简单的数据压缩算法,它在 1994 年发表的文章“A New Algorithm for Data Compression”中被首次提出。下面的示例将解释 BPE。老规矩,我们先用一句话概括它的核心思想:
BPE每一步都将最常见的一对*相邻数据单位*替换为该数据中没有出现过的一个*新单位*,反复迭代直到满足停止条件。
是不是听起来懂了却感觉没有完全懂?下面举个例子。
假设我们有需要编码(压缩)的数据 aaabdaaabac。相邻字节对(相邻数据单位在BPE中看作相邻字节对) aa 最常出现,因此我们将用一个新字节 Z 替换它。我们现在有了 ZabdZabac,其中 Z = aa。下一个常见的字节对是 ab,让我们用 Y 替换它。我们现在有 ZYdZYac,其中 Z = aa ,Y = ab。剩下的唯一字节对是 ac,它只有一个,所以我们不对它进行编码。我们可以递归地使用字节对编码将 ZY 编码为 X。我们的数据现在已转换为 XdXac,其中 X = ZY,Y = ab,Z = aa。它不能被进一步压缩,因为没有出现多次的字节对。那如何把压缩的编码复原呢?反向执行以上过程就行了。
Tokenizer
- character level encoder: codebook 65
- BPE (byte-pair encoder)
- GPT2-3: codebook 50541?
- Tiktoken (OpenAI)
基本是 trade-off of the codebook vs. the token length!
@guodongLLMTokenizer2023
背景
隨着ChatGPT迅速出圈,最近幾個月開源的大模型也是遍地開花。目前,開源的大語言模型主要有三大類:ChatGLM衍生的大模型(wenda、ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera等)、Bloom衍生的大模型(Bloomz、BELLE、Phoenix等)。其中,ChatGLM-6B主要以中英雙語進行訓練,LLaMA主要以英語爲主要語言的拉丁語系進行訓練,而Bloom使用了46種自然語言、13種編程語言進行訓練。
| 模型 | 訓練數據量 | 模型參數 | 訓練數據範圍 | 詞表大小 | 分詞算法 |
|---|---|---|---|---|---|
| LLaMA | 1T~1.4T tokens(其中,7B/13B使用1T,33B/65B使用1.4T) | 7B~65B | 以英語爲主要語言的拉丁語系 | 32K | BBPE |
| ChatGLM-6B | 約 1T tokens | 6B | 中英雙語 | 130K | BBPE |
| Bloom | 1.6TB預處理文本,轉換爲 350B 唯一 tokens | 300M~176B | 46種自然語言,13種編程語言 | 250K | BBPE |
| GPT2 | ? | 50K | Tiktoken |
目前來看,在開源大模型中,LLaMA無疑是其中最閃亮的星。但是,與ChatGLM-6B和Bloom原生支持中文不同。LLaMA 原生僅支持 Latin 或 Cyrillic 語系,對於中文支持不是特別理想。原版LLaMA模型的詞表大小是32K,而多語言模型(如:XLM-R、Bloom)的詞表大小約爲250K。以中文爲例,LLaMA詞表中的中文token比較少(只有幾百個)。這將導致了兩個問題:
- LLaMA 原生tokenizer詞表中僅包含少量中文字符,在對中文字進行tokenzation時,一箇中文漢字往往被切分成多個token(2-3個Token才能組合成一個漢字),顯著降低編解碼的效率。
- 預訓練中沒有出現過或者出現得很少的語言學習得不充分。
爲了解決這些問題,我們可能就需要進行中文詞表擴展。比如:在中文語料庫上訓練一箇中文tokenizer模型,然後將中文 tokenizer 與 LLaMA 原生的 tokenizer 進行合併,通過組合它們的詞彙表,最終獲得一個合併後的 tokenizer 模型。
本文將介紹使用SentencePiece工具如何使用中文語料訓練一個分詞模型。
Coding 例子
1 | |
如何得到 tokenizer? 當然也是 pretrain 得來的。不過一般我們只引用固定的 tokenizer.
答案是肯定的,Tokenizer也是在庞大的预训练语料上训练出来的,只不过由于计算需求相对训练模型少很多。
而在LLAMA中,作者使用的是SentencePiece得到最后的词典,Tokenizer的基座也是SentencePiece中的SentencePieceProcessor类[2], 如下图红框所示,LLAMA的encode过程实际上是通过SentencePiece实现的。
預備知識
講解 SentencePiece 之前,我們先講解下分詞器(Tokenizer)。
那什麼是分詞器?簡單點說就是將字符序列轉化爲數字序列,對應模型的輸入。
通常情況下,Tokenizer有三種粒度:word/char/subword
- word: 按照詞進行分詞,如:
Today is sunday. 則根據空格或標點進行分割[today, is, sunday, .] - character:按照單字符進行分詞,就是以char爲最小粒度。 如:
Today is sunday.則會分割成[t, o, d,a,y, .... ,s,u,n,d,a,y, .] - subword:按照詞的subword進行分詞。如:
Today is sunday.則會分割成[to, day,is , s,un,day, .]
可以看到這三種粒度分詞截然不同,各有利弊。
對於word粒度分詞:
- 優點:詞的邊界和含義得到保留;
- 缺點:1)詞表大,稀有詞學不好;2)OOV(可能超出詞表外的詞);3)無法處理單詞形態關係和詞綴關係,會將兩個本身意思一致的詞分成兩個毫不相同的ID,在英文中尤爲明顯,如:cat, cats。
對於character粒度分詞:
- 優點:詞表極小,比如:26個英文字母幾乎可以組合出所有詞,5000多箇中文常用字基本也能組合出足夠的詞彙;
- 缺點:1)無法承載豐富的語義,英文中尤爲明顯,但中文卻是較爲合理,中文中用此種方式較多。2)序列長度大幅增長;
最後爲了平衡以上兩種方法, 又提出了基於 subword 進行分詞:它可以較好的平衡詞表大小與語義表達能力;常見的子詞算法有Byte-Pair Encoding (BPE) / Byte-level BPE(BBPE)、Unigram LM、WordPiece、SentencePiece等。
- BPE:即字節對編碼。其核心思想是從字母開始,不斷找詞頻最高、且連續的兩個token合併,直到達到目標詞數。
- BBPE:BBPE核心思想將BPE的從字符級別擴展到子節(Byte)級別。BPE的一個問題是如果遇到了unicode編碼,基本字符集可能會很大。BBPE就是以一個字節爲一種“字符”,不管實際字符集用了幾個字節來表示一個字符。這樣的話,基礎字符集的大小就鎖定在了256(2^8)。採用BBPE的好處是可以跨語言共用詞表,顯著壓縮詞表的大小。而壞處就是,對於類似中文這樣的語言,一段文字的序列長度會顯著增長。因此,BBPE based模型可能比BPE based模型表現的更好。然而,BBPE sequence比起BPE來說略長,這也導致了更長的訓練/推理時間。BBPE其實與BPE在實現上並無大的不同,只不過基礎詞表使用256的字節集。
- WordPiece:WordPiece算法可以看作是BPE的變種。不同的是,WordPiece基於概率生成新的subword而不是下一最高頻字節對。WordPiece算法也是每次從詞表中選出兩個子詞合併成新的子詞。BPE選擇頻數最高的相鄰子詞合併,而WordPiece選擇使得語言模型概率最大的相鄰子詞加入詞表。
- Unigram:它和 BPE 以及 WordPiece 從表面上看一個大的不同是,前兩者都是初始化一個小詞表,然後一個個增加到限定的詞彙量,而 Unigram Language Model 卻是先初始一個大詞表,接着通過語言模型評估不斷減少詞表,直到限定詞彙量。
- SentencePiece:SentencePiece它是谷歌推出的子詞開源工具包,它是把一個句子看作一個整體,再拆成片段,而沒有保留天然的詞語的概念。一般地,它把空格也當作一種特殊字符來處理,再用BPE或者Unigram算法來構造詞彙表。SentencePiece除了集成了BPE、ULM子詞算法之外,SentencePiece還能支持字符和詞級別的分詞。
下圖是一些主流模型使用的分詞算法,比如:GPT-1 使用的BPE實現分詞,LLaMA/BLOOM/GPT2/ChatGLM使用BBPE實現分詞。BERT/DistilBERT/Electra使用WordPiece進行分詞,XLNet則採用了SentencePiece進行分詞。
從上面的表格中我們也可以看到當前主流的一些開源大模型有很多基於 BBPE 算法使用 SentencePiece 實現
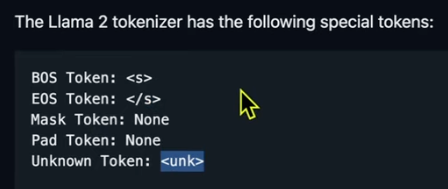
Some Topics
-
Tokenizer conversion: 例如把 Llama tokenizer 轉換成 GPT tokenizer. 好處是 (1) 可以 cascade 不同 tokenizer models. (2) mixed (parallel) 不同 tokenizer models.
-
Tokenizer merge: English tokenizer and Chinese tokenizer for English and Chinese.
Tokenizer Conversion for Cascaded Model
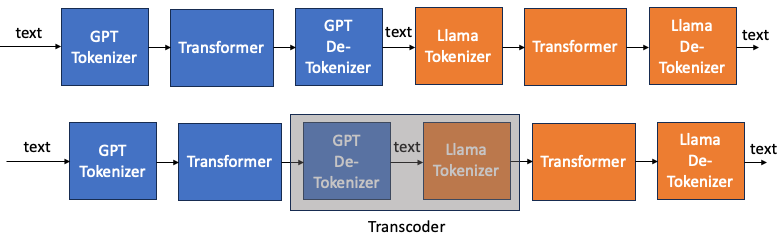
下圖一是兩個不同 tokenizer LLM model 串接。一個例子就是 speculative decode 的 draft mode 和 original model, Draft model 可能使用一個小模型使用和 original 模型不同的 tokenizer.
最直覺的方法就是把 GPT transformer 的 GPT token 先轉換成 text,再由 Llama tokenizer 轉換成 Llama tokens. 這好像是一個可行的方法,基本是兩次的 table lookup (de-tokenizer + tokenizer)。
一個問題是我們是否可以訓練一個 transcoder model, 類似翻譯。從 GPT token 轉換成 Llama token?
先不論是否划算,因為一個 transcoder 可能比兩次的 table lookup 更複雜。但也有可能更簡單。因為 table 都是很大的 table (32K or 50K 參數)。也許簡單的 transcoder (CNN, RNN, or transformer) 可以達成同樣的結果。
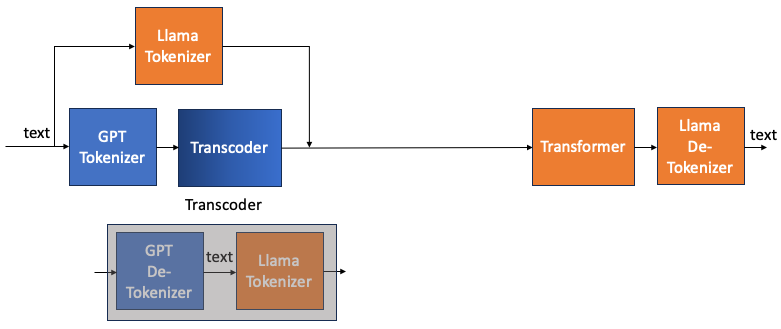
如何 train 這個 transcoder?
上圖 transcoder 很難訓練,因為 input token 和 output token 很難產生。如果勉強用完整的圖一,還會與 transformer 有關。是否可以有容易的 input and output tokens, 並且和 transformer 無關的方法? YES!
下圖是 transcoder 等價的方塊圖。如果要得到一個 GPT de-tokenizer to Llama tokenizer 的transcoder。 相當於訓練一個 input text to GPT tokenizer 而 output 是相同 text to Llama tokenizer 的 transcoder.
因為 text, Llama tokenizer, GPT tokenizer 都是已知。並且整個訓練和 transformer 完全無關!
可以推廣如果要做一個 A de-tokenizer to B tokenizer 的 transcoder, 可以用 text to A tokenizer 為 input, 同樣 text to B tokenizer 為 output. 用這樣 (input, output) 對訓練 model (CNN, RNN, or transformer)
- 一個 trick 是 transcoder 的 vocab size 需要是兩個 tokenizers 的大者。以免 transcoder 會 out of range.
Merge Tokenizer
https://discuss.tensorflow.org/t/is-there-an-existing-tokenizer-model-for-chinese-to-english-translation/4520
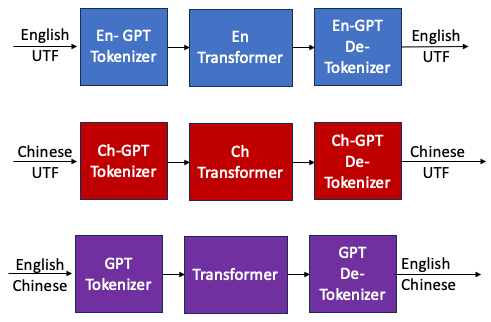
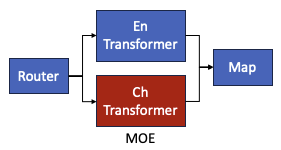
En-Tranformer 和 Ch-Transformer 可以用 MoE 解決!!!
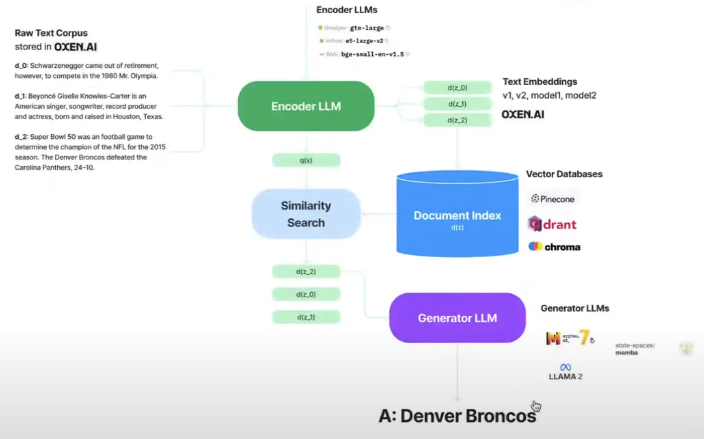
RAG: LLM encoder and LLM generator 可以用不同的 tokenizers!