Source
- Stream Attention [@xiaoEfficientStreaming2023]
- [@xiaoEfficientStreaming2024]
- [@swiftinferHpcaitechSwiftInfer2024]
Attention Sink
该语言模型在长度为 L 的文本上进行了预训练 (pre-trained),预测第 T 个token(T≫L)。
因爲本篇論文的目標是處理無限長的文本,所以無法事先預訓練 (pre-trained)。
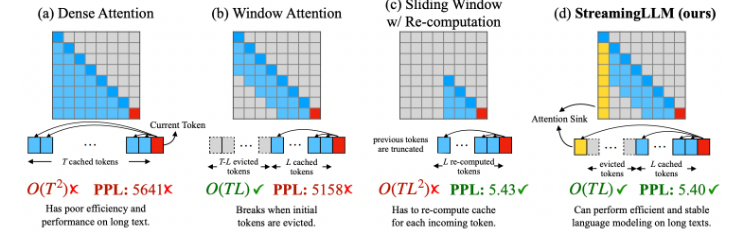
(a): Dense attention: attention matrix 和 $T^2$ 成正比。其中 $T$ 是 context length.
(b): Window Attention: attention matrix 和 $T L$, where $L$ 是?
| Dense Att. | Window Att. | Sliding Win. | Streaming Win | |
|---|---|---|---|---|
| Att. size | $T^2$ | $TL$ | $T L^2$ | $TL$ |
| PPL | Good | Bad perplexity | Good performance | Good performance |
| Cons | Not affordable | Still high cost | Linear cost |
Case a: Dense attention has $O(T^2)$ time complexity, 另外 KV cache size 平方成正比
Case b: Sliding window attention 存儲最近 L tokens’ KV cache (TL). 最大的問題就是只有最近的 L token 記憶
Case c: Sliding window with re-computation. 這是針對 case b 的補救。對於每個新的 token,都要重新 build 最近 L token 的 KV cache! 所以是 TL x L = TL^2.
Case d: StreamingLLM 卻是用非常簡單的方法,就是 keep attention sink (前 4 initial token)
(a) 密集注意力(Dense Attention)具有 $O(T^2)$ 的时间复杂度和不断增加的 KV 缓存大小。当文本长度超过预训练文本长度时,其性能会下降。 (b) 窗口注意力(Window Attention)缓存最近的 $L$ 个tokens的KV。虽然在推理中效率高,但一旦开始tokens的KV 被驱逐,性能就会急剧下降。 (c) 重计算的滑动窗口(Sliding Window with Re-computation)为每个新token重建来自 L 个最近tokens的KV状态。虽然它在长文本上表现良好,但由于在上下文重计算中的二次注意力,其 $O(T L^2)$ 的复杂度使其相当缓慢。 (d) StreamingLLM 保留了用于稳定注意力计算的attention sink(几个初始tokens),并结合了最近的tokens。它高效并且在扩展文本上提供稳定的性能。使用Llama-2-13B模型在PG-19测试集的第一本书(65K tokens)上测量了困惑度。
当将LLMs应用于无限输入流时,会出现两个主要挑战:
- 在解码阶段,基于Transformer的LLMs缓存所有先前tokens的Key和Value状态(KV)见图1a,这可能导致过度的内存使用和增加的解码延迟。
- 现有模型的长度外推能力有限,即当序列长度超出预训练期间设置的注意力窗口大小时,它们的性能会下降。
一种直观的方法,称为窗口注意力,只在最近的tokens的KV状态上维护一个固定大小的滑动窗口(图1b)。尽管它确保了初始填充缓存后的恒定内存使用和解码速度,但一旦序列长度超过缓存大小,模型就会崩溃,即使只是驱逐第一个token的KV(图3)。另一种策略是带有重计算的滑动窗口(图1c),它为每个生成的token重建最近tokens的KV状态。虽然它提供了强大的性能,但由于其窗口内的二次注意力计算,这种方法显著更慢,使得这种方法不适用于实际的流式应用。
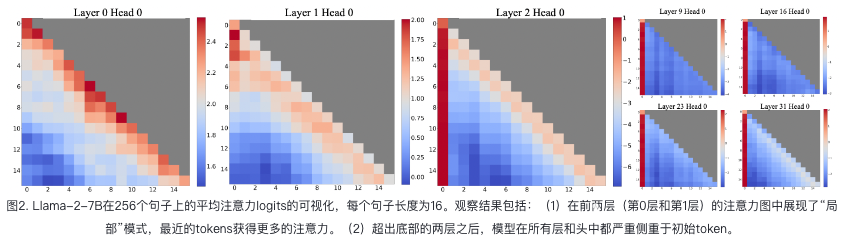
为了理解窗口注意力的失败,我们发现了自回归LLMs的一个有趣现象:无论它们与语言建模任务的相关性如何,初始tokens都被分配了惊人的大量注意力得分,见图2。我们将这些tokens称为“attention sinks”。尽管它们缺乏语义意义,但它们收集了重要的注意力得分。我们将原因归因于Softmax操作,它要求所有上下文tokens的注意力得分总和为一。因此,即使当前查询在许多先前的tokens中没有强烈的匹配,模型仍然需要将这些不需要的注意力值分配到某个地方,以使其总和为一。将初始tokens作为sink tokens的原因是直观的:由于自回归语言建模的特性,初始tokens对几乎所有后续tokens都是可见的,使它们更容易被训练以用作attention sinks。
Inference: Reduce computation and activation
1. Cache size optimization
就是使用 KV cache + flash decoder? to break the 32K into 2K + 2K …. chunks?
2. MGQ (Multiple Group Query)
應該是減少 heads, 或是多個 heads 共享同一個 weights?