Source
Takeaway
- Mistral Long Context: GQA and SWA
- GQA 的幫助:1B model > 2K context; 7B model > 8K context
Mistral
人工智慧新創公司Mistral AI以Apache 2.0授權開源Mistral 7B語言模型,Mistral 7B的特別之處在於其規模較小僅有73億,但是在所有基準測試上,其表現都優於規模更大的語言模型Llama 2 13B,還具有編寫程式碼以及處理8,000個token的能力。
整體來說,Mistral 7B在多個基準測試,包括常識推理、世界知識、閱讀理解、數學和程式碼等,表現亮眼,除了明顯優於Llama 2 13B之外,也和Llama 34B模型打成平手,其編寫程式碼的能力接近CodeLlama 7B,並且在英文任務中表現良好。
在大規模多工語言理解(MMLU)基準測試上,Mistral 7B的表現相當一個3倍大的Llama 2模型,但是卻可大幅節省記憶體消耗,吞吐量也有所增加,其提供了更高的性價比。
Mistral 7B運用了群組查詢注意力(GQA)加快推理速度,還使用滑動視窗注意力(SWA),以更小的成本處理較長的序列。群組查詢注意力方法分組多個查詢並且同時進行處理,透過這種方式,群組查詢注意力機制能夠減少重複計算,提高推理速度並降低運算成本。
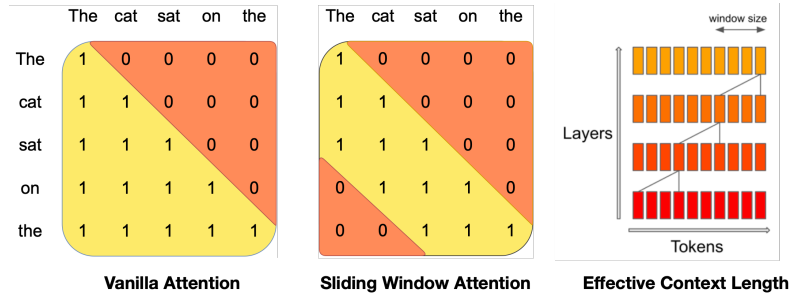
滑動視窗注意力機制則限制模型,在神經網路的每一個層級,只能關注前面一定範圍的token,這個限制視窗會根據模型的層數向前滑動,在更高的層數中,模型能夠間接關注序列中更早出現的token。運用這種方式,滑動視窗注意力機制可以降低計算和記憶體需求,並更高效地處理長序列,Mistral 7B每層注意前4,096個隱藏狀態,能夠以線性計算成本提高處理速度,特別是序列長度為16K 時,速度提高達2倍。
這兩種技術組合使Mistral 7B在處理各種不同任務時,具有高效和靈活性,同時保持良好的可擴展性。
另外,官方也運用公開指令資料集微調Mistral 7B,經過微調後的Mistral 7B Instruct模型在MT-Bench測試中表現良好,能夠與130億參數的聊天模型的效能相當。
How to Make Long Context
是否有方法
- **Training: 只要 fine-tune 原來的 1K/2K 的 LLM model parameter 就可以改成 4K-32K context, **
- 修改 position encoder only
- Page retrieval: Llama-long
- Inference: long context 內部的計算和 activation 的 cache size 不需要增加? too good to be true!!!!
- GQA (algorithm)
- Sliding Window Attention (SWA)
- SteamingLLM (Attention Sink)
- Cache compression, H2O (algorithm)
- Flash decoder (software optimization)
GQA
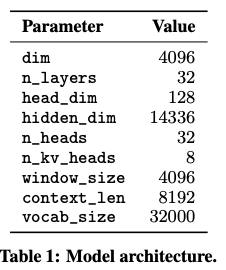
Mistral 7B 如下表。
Mistral 7B is based on a transformer architecture [27]. The main parameters of the architecture are summarized in Table 1. Compared to Llama, it introduces a few changes that we summarize below.
SWA: Window size 4K, attention context 約 8-16K.
Group = n_heads / n_kv_heads = 32/8 = 4?
Rolling Buffer Cache
SWA : Sliding Window Attention
#####