Source
- openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision (github.com)
- (89) Fine tuning Whisper for Speech Transcription - YouTube Excellent video!!!!!
- “OpenAI Whisper 新一代语音技术.” 知乎专栏, December 29, 2023. https://zhuanlan.zhihu.com/p/662906303.
- 使用推测解码 (Speculative Decoding) 使 Whisper 实现 2 倍的推理加速 - 知乎 (zhihu.com)
- Gandhi, Sanchit. “Speculative Decoding for 2x Faster Whisper Inference.” Accessed January 21, 2024. https://huggingface.co/blog/whisper-speculative-decoding.
介紹
更新:Whisper-large-v3也在首次OpenAI开发者大会之后,11月7号 release出来了,效果更加强劲。
Whisper是OpenAI于2022年12月发布的语音处理系统。虽然论文名字是Robust Speech Recognition via Large-Scale Weak Supervision,但不只是具有语音识别能力,还具备语音活性检测(VAD)、声纹识别、语音翻译(其他语种语音到英语的翻译)等能力。
Whisper相关资源:
- Blog:Introducing Whisper
- Paper:https://cdn.openai.com/papers/whisper.pdf
- Model: https://huggingface.co/openai/whisper-large-v2
- Belle-whisper:BELLE-2/Belle-whisper-large-v2-zh · Hugging Face (增强中文识别能力的开源模型)
- Belle-distilwhisper: BELLE-2/Belle-distilwhisper-large-v2-zh · Hugging Face (蒸馏模型基础上增加中文识别能力)
Whisper是端到端的语音系统,相比于之前的端到端语音识别,其特点主要是:
- 多语种:英语为主,支持99种语言,包括中文。
- 多任务:语音识别为主,支持VAD、语种识别、说话人日志、语音翻译、对齐等。
- 数据量:68万小时语音数据用于训练,从公开数据集或者网络上获取的多种语言语音数据,远超之前语音识别几百、几千、最多1万小时的数据量。下面会展开介绍。
- 鲁棒性:主要还是源于海量的训练数据,并在语音数据上进行了常见的增强操作,例如变速[1]、加噪、谱增强[2]等。
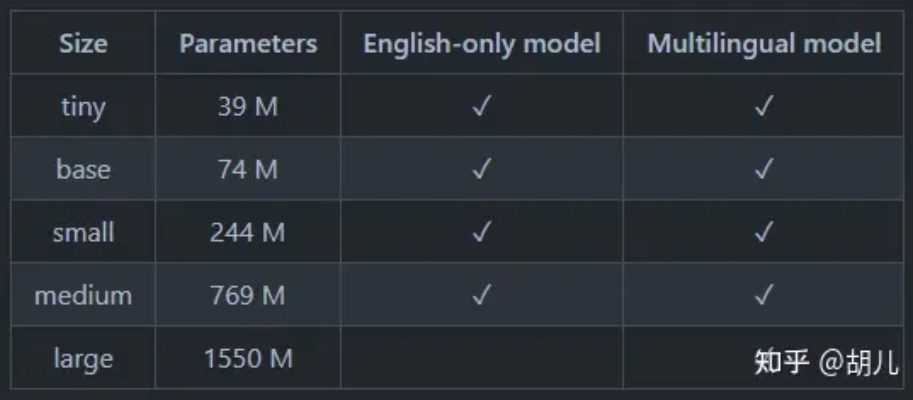
- 多模型:提供了从tiny到large,从小到大的五种规格模型,适合不同场景。如下图所示:
- 根據實測效果:tiny 和 base 效果不好。可能從 small 開始使用。
應用
- ASR : speech recognition
- YouTube video transcript: 幫 youtube 加 caption
- Whisper + LLM: 非常有用的應用
性能
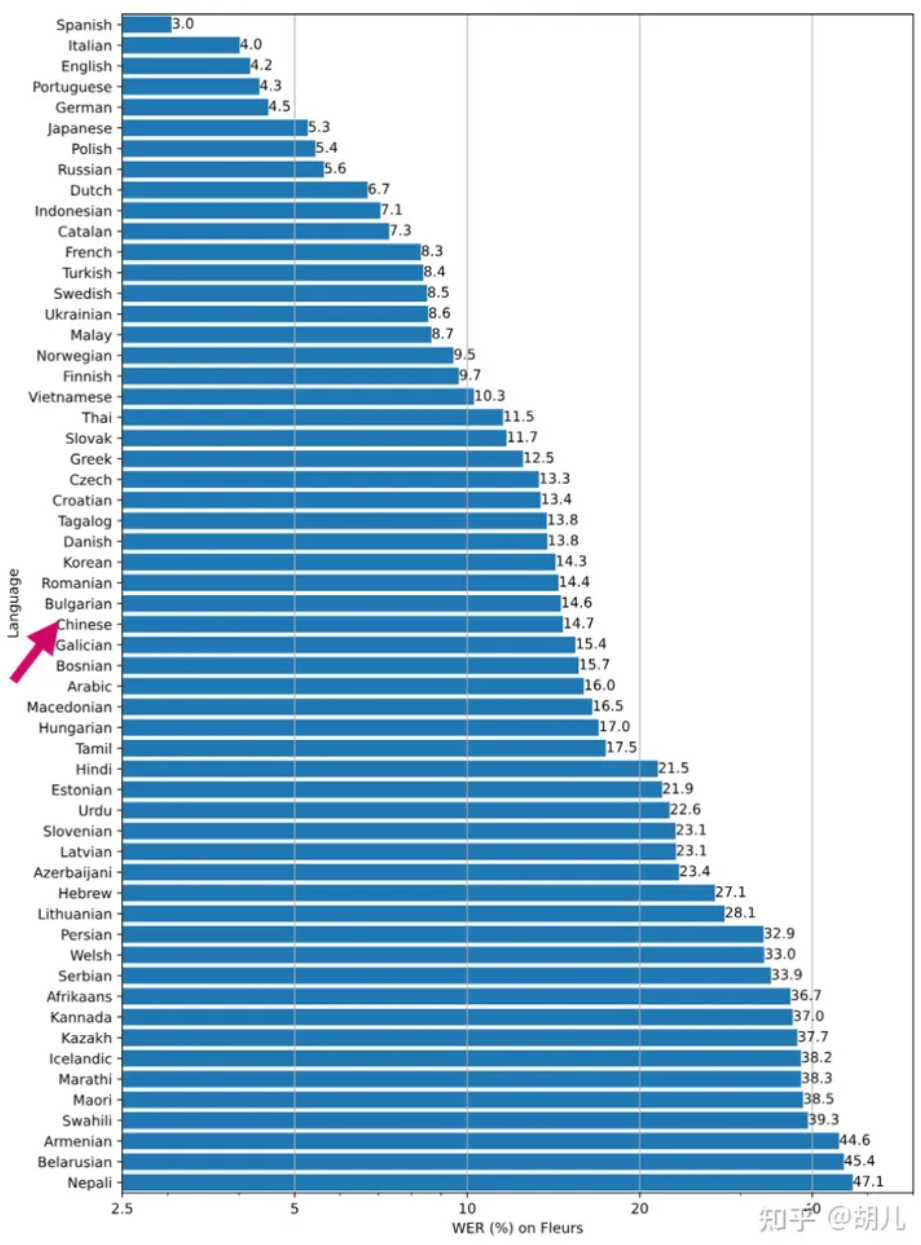
whisper-large-v2
下图是在 whisper-large-v2 在 Fleurss数据集上的词错误率WER(越低越好),幾個特點。
- 拉丁語系 (西語,葡語,意語)表現普遍好,可能和母音發音的爲主有關。
- 英語訓練集多自然性能好,德語應該是和英語接近所以表現不錯。
- 日語表現好,可能是日語冗餘多。
- 中文的表现中规中矩。
whisper-large-v3
Whisper-large-v3 相比 v2 在各個語言有 10-20% 的效果提升。
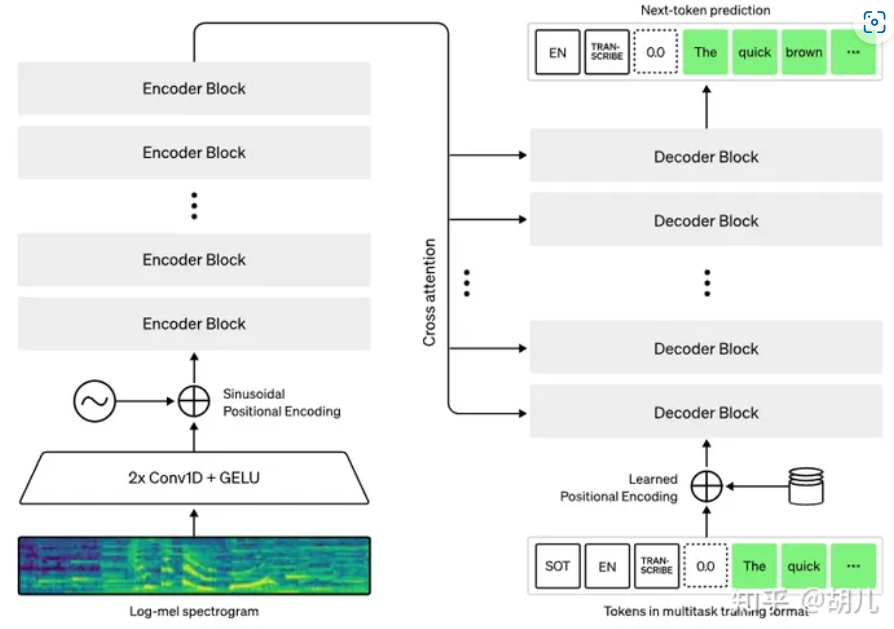
模型
数据处理
数据过滤:
- 通过启发式方法,去掉其中ASR产生的数据。例如,纯大写、纯小写、没有标点等,去掉这类数据。
- 语种是否匹配,语音和文本是否属于同一语种。基于语音语种检测模型来实现。
- 数据去重,转写文本级别的去重。
数据格式化:
- 30秒长度,最长30秒长度。所以在使用时,最好不要超过30秒,以获得最好的效果。
- 语音、非语音均保留。非语音数据可以用来训练VAD任务。
- 重采样至16Khz,语音数据涉及到采样率问题,实际应用中8Khz、16Khz最为常见。whisper将所有数据均重采样到16Khz,不再对不同采样率分别建模,一个模型即可完成,简化复杂度,模型性能也会有一定提升。
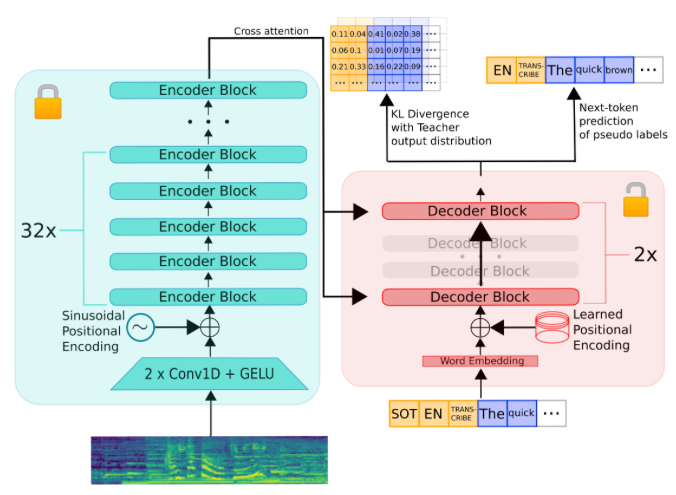
Speculative Decode
-
Whisper 的瓶頸是在 decoder, 也就是 generation. 因為每個 token 產生都需要重新 load 所有的 weights.
-
Speculative decode 使用大小模型可以加速 decode 的過程。
-
Draft model: full encoder (32x?) + 2 layer of decoder 如下圖
-
Main model: share the same encoder + full decoder
-
Main + draft model 增加 8% model size.
1 | |
Future Work
- Medusa for whisper? Lookahead for whisper.
- Math model for Medusa and other.