Takeaway
-
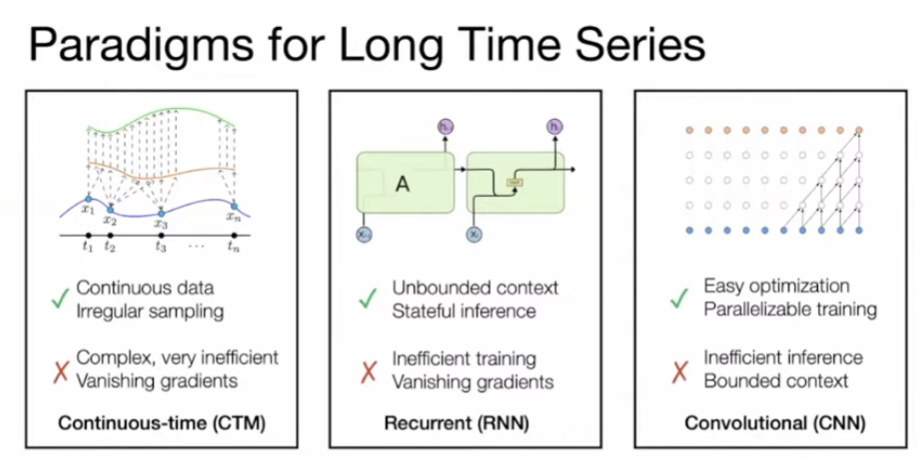
Transformer 最大的問題是性能 (吞吐量 throughput,準確度 perplexity,延遲 latency) 隨著 sequence length 下降。但是 long context 對 RAG 和 multi-modality model 非常重要。

-
RNN 或是類似 state compression 的 model 例如 RetNet, RWKV, Mamba 可以解決這個問題。
-
S4 (or SSM) for linear sequence -> S6 (add selector) -> Mamba (add more layers and other blocks) for generation
| RNN/LSTM | Transformer | RWKV | Mamba | |
|---|---|---|---|---|
| Train, 時間維度 | 梯度消失,無法平行 | 可以平行 | 可以平行 | 可以平行 |
| Attention scope | 小,附近 tokens | 大,$T$ | 大,$T$ | 無窮大? |
| Attention 計算, $T$ tokens | 綫性 | 平方 (prefill) | 綫性 | 綫性 |
| Attention 存儲 | 1-step | 平方 (update) | 1-step | 1-step |
| Complexity, Time | $O(T^2 d)$ | $O(T d)$ | ||
| Complexity, Space | $O(d)$, 1-step | $O(T^2 + Td)$ | $O(d)$, 1-step | $O(d)$ |
| Nonlinearity | Small sigmoid ($d$) | Big softmax ($d^2$) | Softmax, sigmoid? | Small softmax ($d$), SILU x*sigmoid(x) |
$T$: sequence length; $d$: feature dimension. $d$ 和 $N$ 是同一件事嗎?
介紹
自 2017 年被提出以來,Transformer 已經成爲 AI 大模型的主流架構,但隨着模型規模的擴展和需要處理的序列不斷變長,Transformer 的侷限性也逐漸凸顯。一個很明顯的缺陷是:Transformer 模型中自注意力機制的計算量或存儲會隨着上下文長度的增加呈平方級增長,比如上下文增加 32 倍時,計算量可能會增長 1000 倍,計算效率非常低。注意此事可以用 KV cache 減少計算量,但付出的代價是存儲呈平方成長。
爲了克服這些缺陷,研究者們開發出了很多注意力機制的高效變體,但這往往以犧牲其有效性特爲代價。到目前爲止,這些變體都還沒有被證明能在不同領域發揮有效作用。幾個例子: RetNet, RWKV (Receptance Weighted Key Value).
我們複習一下之前的架構,再和 Mamba 做一些比較。
RNN/LSTM
-
Training: 長序列訓練 RNN 的困難:
-
梯度消失: LSTM 有一定程度減緩這個問題。
-
Recurrent 結構,所以無法在時間維度平行訓練。但在 batch 方向仍然可以平行。
-
- Inference: 雖然 recurrent generation 無法像 CNN 可以平行展開,但所有生成的 token 都只需要前一個 time step 的 hidden state + input (Markovian)!
- RNN/LSTM 除了訓練長序列困難,另一個缺點是 attention scope 不夠!比較久之前的 tokens attention 會消失,因此常用於語音或比較 local attention 的應用。
Transformer
- Training: 可以在時間維度 (token sequence) 平行訓練 (類似 prompt mode). 這是最大的優點。
- Inference (generative mode): (1) 好處是 attention scope 包含所有之前 context 範圍的 tokens (1K/4K/8K); (2) 缺點是 attention matrix 的計算和存儲都和 context length 的平方成正比。另一個缺點是 token generation 仍然是 recurrent.
Transformer 徹底改變了幾乎所有自然語言處理 (NLP) 任務,但其內存和計算複雜性卻與序列長度呈二次方關係。相比之下,RNN 和 LSTM 在內存和計算要求方面表現出線性擴展,但由於並行化和可擴展性的限制,很難達到與 Transformer 相同的性能。
RetNet
RetNet是微软研究院提出的一种新型自回归基础架构。RetNet在某种程度上借鉴了Transformer的思想,但它并非直接基于Transformer,而是提出了一种新的机制和架构,在新的架构中引入了一种名为多尺度保留(Multi-ScaleRetention,MSR)的机制来替代Transformer中的多头注意力机制。
RetNet的设计不仅提高了训练效率,还大大简化了推断过程。从RetNet的并行训练和循环推理可以发现它实际上是RNN和Transformer核心原则的融合:即REcurrent(循环)+self-attenTION(自注意力)=RETENTION(保留)。

RWKV
一種新穎的模型架構,即接收加權鍵值(Reacceptance Weighted Key Value, RWKV),它將 Transformer 的高效可並行訓練與 RNN 的高效推理相結合。我們的方法利用線性注意力機制,允許我們將模型制定爲 Transformer 或 RNN,它在訓練過程中並行計算,並在推理過程中保持恆定的計算和內存複雜性,從而使第一個非 Transformer 架構擴展到數十個數十億個參數。實驗表明,RWKV 的性能與類似大小的 Transformer 相當,這表明未來的工作可以利用這種架構來創建更高效的模型。這項工作在協調序列處理任務中計算效率和模型性能之間的權衡方面邁出了重要一步。
缺點: 雖然是綫性。但是非綫性計算非常複雜?看起來是用計算換綫性 attention?
Mamba
最近,一項名爲「Mamba」的研究似乎打破了這一局面。這篇論文的作者只有兩位,一位是卡內基梅隆大學機器學習系助理教授 Albert Gu (Stanford PhD),另一位是 Together.AI 首席科學家、普林斯頓大學計算機科學助理教授(即將上任)Tri Dao。
Albert Gu 一個重要創新是引入了一個名爲「選擇性 SSM」的架構,該架構是 Albert 此前主導研發的 S4 架構(Structured State Spaces for Sequence Modeling ,用於序列建模的結構化狀態空間)的一個簡單泛化,可以有選擇地決定關注還是忽略傳入的輸入。一個「小小的改變」—— 讓某些參數 (B, C matrix) 成爲輸入的函數,結果卻非常有效。
附帶一提,SSM (State Space Model) and the underlying linear algebra (Hippo) theory 可以說源自 Stanford 的 Information System Lab (Thomas Kailath)
Mamba 完整的架構如下圖右紅筆所示。基本結構和 transformer model 非常類似。不過核心的 attention block 被 SSM 取代。
而且這個 SSM 是 S6 結構 (State space model with selector). 是從 vanilla SSM S4 而來。

| Transformer | Mamba | |
|---|---|---|
| Attention | SSM (S6) | |
| Linearity | Nonlinear (softmax inside) | Linear (S4 is linear time-invariant, S6 is linear time-varying) |
| Trainable | Q, K, V mapping and multi-head | 3 mappings, delta, N, B, C (A is fixed, but A_bar is trainable) |
| Multi-head | Yes, d_model / d_dimension | Hidden state dimension? N |
S3 (State Space for Sequence) vs. S4 (Structured S3) vs. S6 (Selective Scan S4)
| S3 - State Space Sequence | S4 - Structured S3 | S6 - Selective Scan S4 | |
|---|---|---|---|
| A, B, C | fixed | fixed | A fixed, B/C content dependent |
| $\bar{A}, \bar{B}, \bar{C}$ | Based on trainable $\Delta$ | Based on trainable $\Delta$ | Based on trainable $\Delta$ $\bar{B} \bar{C}$ trainable |
| $y$ | Convolution: $K * x$ | Convolution: $K * x$ | Scan because $\bar{B}_t, \bar{C}_t$ are content dependent |
| A | Random, not stable | Hippo | Hippo |
###
S3: 源自 sequence model
S3 has 3 equivalent representations.
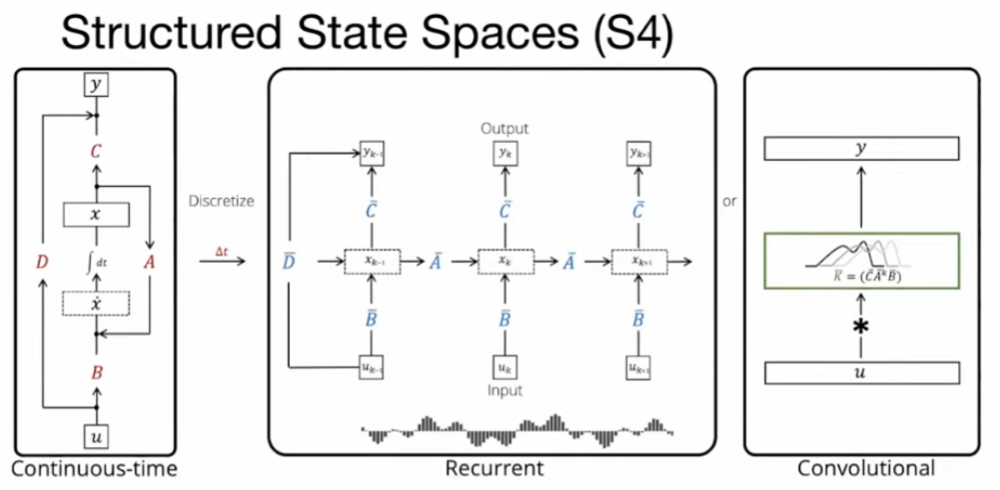
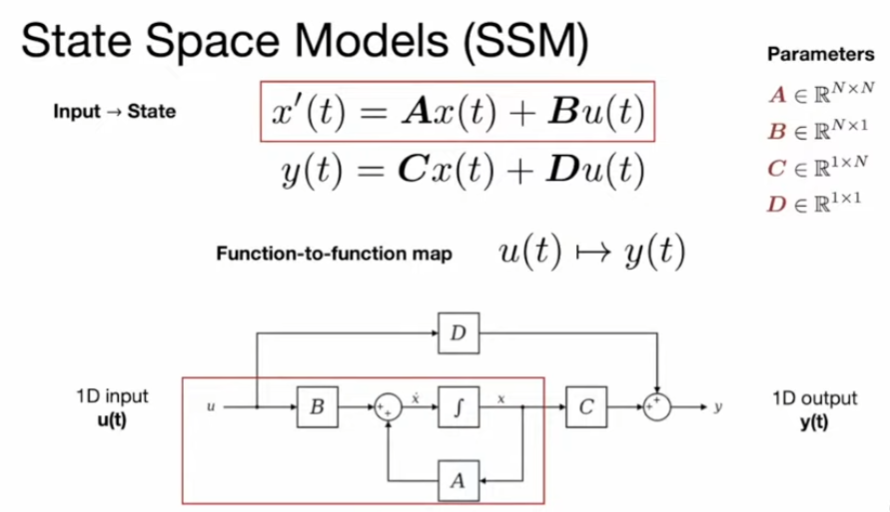
Continuous-time view
(Linear) Recurrent view, (similar to nolinear RNN): Discrete-time SSM, and unroll it to get the recurrent version

Convolution view: Discrete and unroll it

Trainable parameter:
A_bar, B_bar, C_bar
幾個重點
-
A, B, C 形成 convolution kernel to compress the input to finite states (有 dimensions!). 可以想成 filters!

-
Kernel space 可以是 multi-dimension。這其實對應 CNN 不同的 kernels. 或者類似 transformer 的 multi-heads!
Challenges
Problem of Long Range Dependency!
- Random initiation problem. MNIST only get 50%.
A and K are very slow to compute
- Power up A -> vanishing gradients
- Computation: Power up A O(N^2 L) computation. Ideal O(L) computation
S4: 加上 HIPPO on A to solve the above two problems
值得一提的是,S4 是一個非常成功的架構。此前,它成功地對 Long Range Arena (LRA) 中的長程依賴進行了建模,併成爲首個在 Path-X 上獲得高於平均性能的模型。更具體地說,S4 是一類用於深度學習的序列模型,與 RNN、CNN 和經典的狀態空間模型(State Space Model,SSM)廣泛相關。SSM 是獨立的序列轉換,可被整合到端到端神經網絡架構中( SSM 架構有時也稱 SSNN,它與 SSM 層的關係就像 CNN 與線性卷積層的關係一樣)。Mamba 論文也討論了一些著名的 SSM 架構,比如 Linear attention、H3、Hyena、RetNet、RWKV,其中許多也將作爲論文研究的基線。Mamba 的成功讓 Albert Gu 對 SSM 的未來充滿了信心。
S4 的問題:
- Linear, S4 是 LTI (linear and time invariant, content independent). S6 也是 linear, but time varying (content dependent! 類似 RNN)
-
S4: No nonlinearity in hidden states! one step –> S6 keep this. training like transformer
-
S4: No time dependent in hidden states! –> S6 relax this . Inference like LSTM
- S4: A and B are fixed parameter to memorize, predicted by theory. C and delta are deep learning parameters –> S6 change A to fixed, and B, C, delta learnable from current input, but not last hidden state, not anything in the past, which is different from LSTM!
Conclusion: S4 is better than CNN and RNN across-board. But competitive to transformer
Solution S4 : Structured State Space (SSS?) built-in structure to remember long context!
- HiPPO operators A are structured (e.q. quasiseparable)


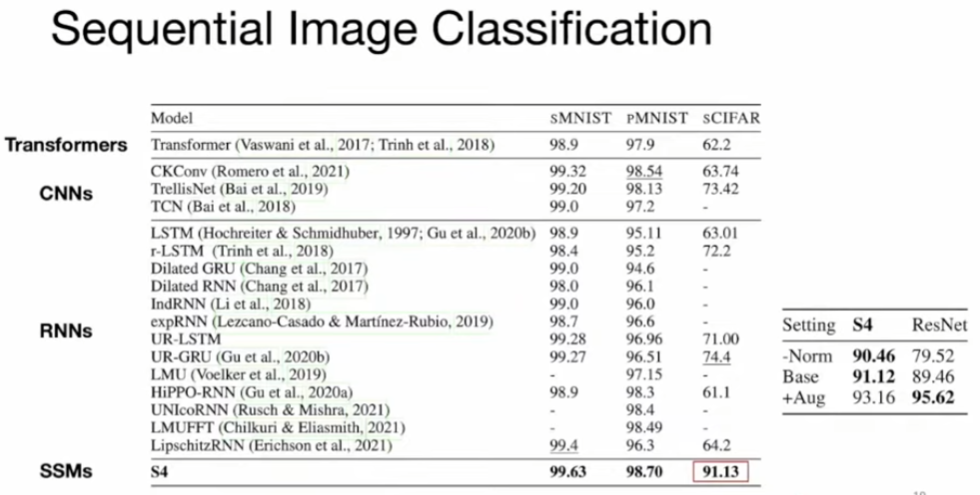
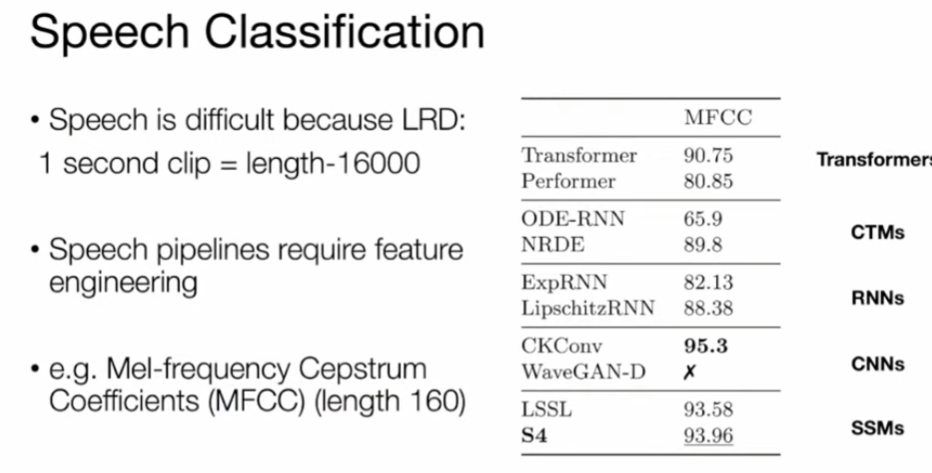
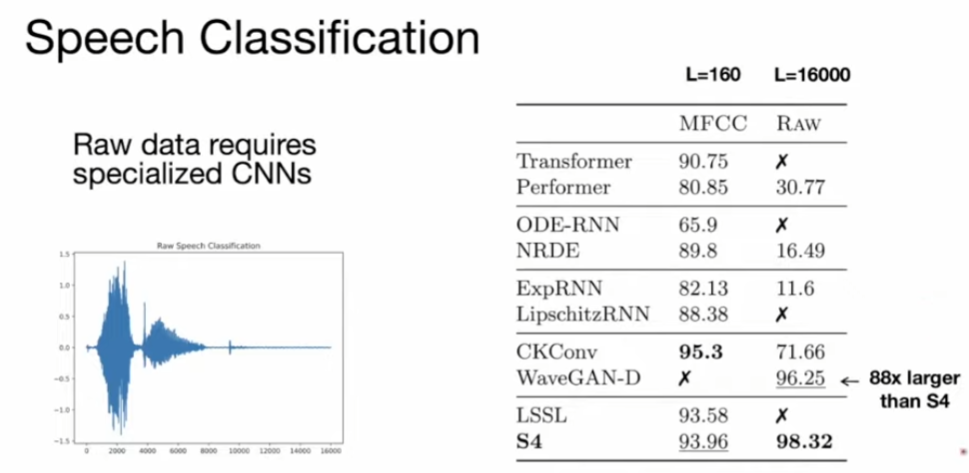
Raw speech! long range because of the sampling rate !!!
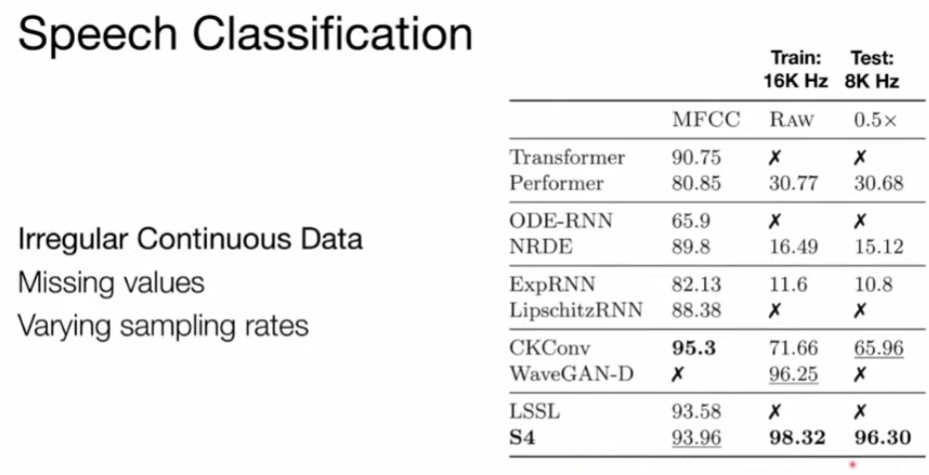
Insensitive to the sampling rate. Training at 16K, test at 8K.
Long range
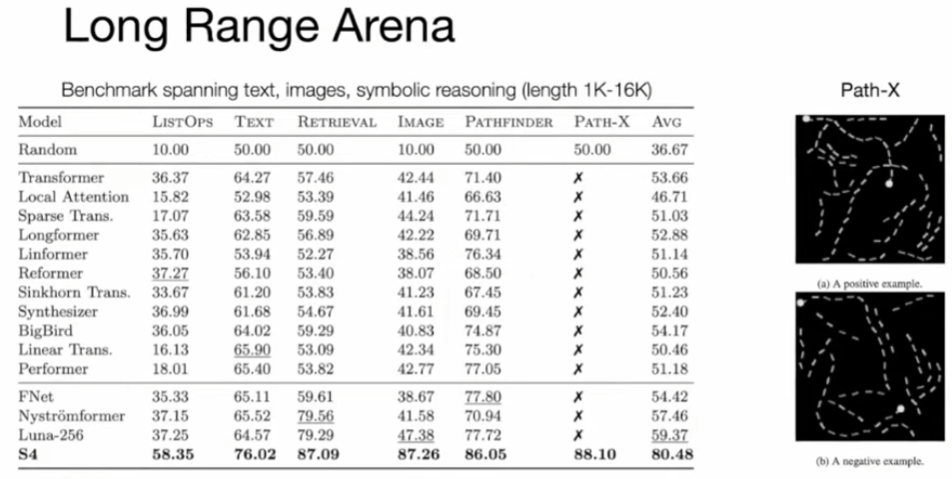
Text : best for no attention model.
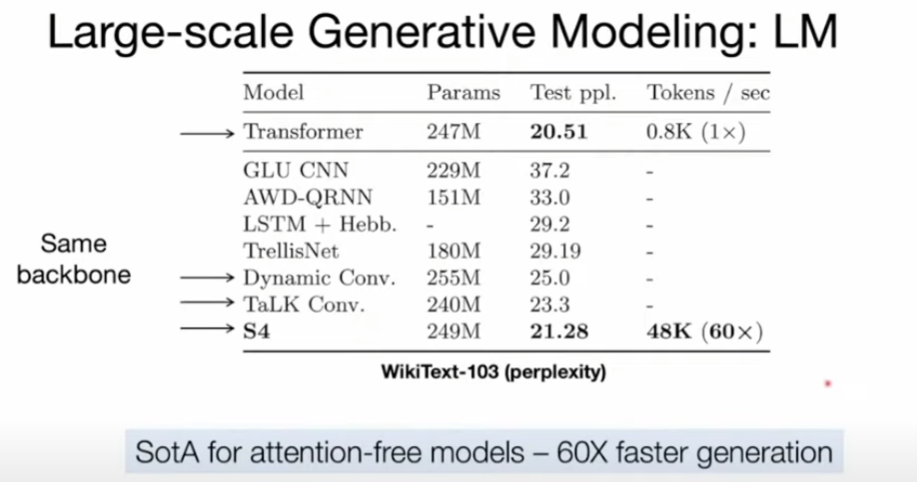
Tri Dao 則是 FlashAttention、Flash Attention v2、Flash-Decoding的作者。FlashAttention 是一種對注意力計算進行重新排序並利用經典技術(平鋪、重新計算)加快速度並將內存使用從序列長度的二次減少到線性的算法。Flash Attention v2、Flash-Decoding 都是建立在 Flash Attention 基礎上的後續工作,把大模型的長文本推理效率不斷推向極限。在 Mamba 之前,Tri Dao 和 Albert Gu 也有過合作。
From S4 to S6 方法創新
A, B, C, D fixed 變成 B, C learnable?
論文第 3.1 節介紹瞭如何利用合成任務的直覺來啓發選擇機制,第 3.2 節解釋瞭如何將這一機制納入狀態空間模型。由此產生的時變 SSM 不能使用卷積,導致了高效計算的技術難題。研究者採用了一種硬件感知算法,利用當前硬件的內存層次結構來克服這一難題(第 3.3 節)。第 3.4 節描述了一個簡單的 SSM 架構,不需要注意力,甚至不需要 MLP 塊。第 3.5 節討論了選擇機制的一些其他特性。
選擇機制
研究者發現了此前模型的一個關鍵侷限:以依賴輸入的方式高效選擇數據的能力(即關注或忽略特定輸入)。
序列建模的一個基本方法是將上下文壓縮到更小的狀態,我們可以從這個角度來看待當下流行的序列模型。例如,注意力既高效又低效,因爲它根本沒有明確壓縮上下文。這一點可以從自迴歸推理需要明確存儲整個上下文(即 KV 緩存)這一事實中看出,這直接導致了 Transformer 緩慢的線性時間推理和二次時間訓練。
遞歸模型的效率很高,因爲它們的狀態是有限的,這意味着恆定時間推理和線性時間訓練。然而,它們的高效性受限於這種狀態對上下文的壓縮程度。
爲了理解這一原理,下圖展示了兩個合成任務的運行示例:
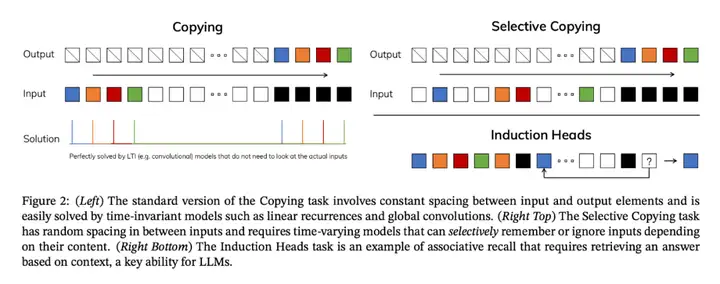
研究者設計了一種簡單的選擇機制,根據輸入對 SSM 參數進行參數化。這樣,模型就能過濾掉無關信息,並無限期地記住相關信息。
將選擇機制納入模型的一種方法是讓影響序列交互的參數(如 RNN 的遞歸動力學或 CNN 的卷積核)與輸入相關。算法 1 和 2 展示了本文使用的主要選擇機制。其主要區別在於,該方法只需將幾個參數 ∆,B,C 設置爲輸入函數,並在整個過程中改變張量形狀。這些參數現在都有一個長度維度 L ,意味着模型已經從時間不變變爲時間可變。

硬件感知算法
上述變化對模型的計算提出了技術挑戰。所有先前的 SSM 模型都必須是時間和輸入不變的,這樣才能提高計算效率。爲此,研究者採用了一種硬件感知算法,通過掃描而不是卷積來計算模型,但不會將擴展狀態具體化,以避免在 GPU 存儲器層次結構的不同級別之間進行 IO 訪問。由此產生的實現方法在理論上(與所有基於卷積的 SSM 的僞線性相比,在序列長度上呈線性縮放)和現有硬件上都比以前的方法更快(在 A100 GPU 上可快達 3 倍)。
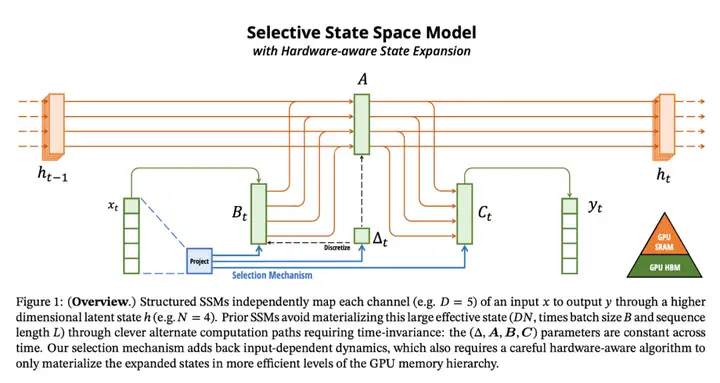
架構
研究者將先前的 SSM 架構設計與 Transformer 的 MLP 塊合併爲一個塊,從而簡化了深度序列模型架構,形成了一種包含選擇性狀態空間的簡單、同質的架構設計(Mamba)。
與結構化 SSM 一樣,選擇性 SSM 也是一種獨立的序列變換,可以靈活地融入神經網絡。H3 架構是著名的同質化架構設計的基礎,通常由線性注意力啓發的塊和 MLP(多層感知器)塊交錯組成。
研究者簡化了這一架構,將這兩個部分合二爲一,均勻堆疊,如圖 3。他們受到門控注意力單元(GAU)的啓發,該單元也對注意力做了類似的處理。
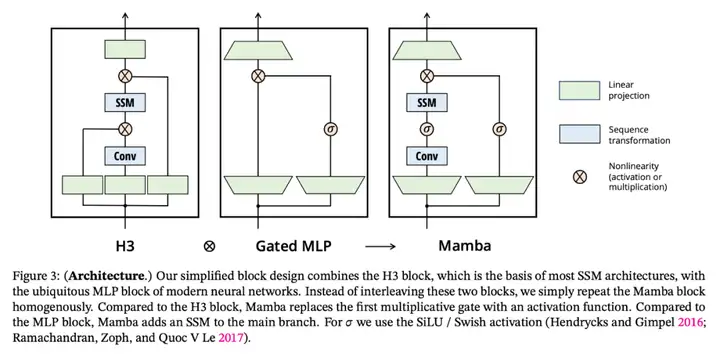
選擇性 SSM 以及 Mamba 架構的擴展是完全遞歸模型,幾個關鍵特性使其適合作爲在序列上運行的通用基礎模型的骨幹:
- 高質量:選擇性爲語言和基因組學等密集模型帶來了強大的性能。
- 快速訓練和推理:在訓練過程中,計算量和內存與序列長度成線性關係,而在推理過程中,由於不需要緩存以前的元素,自迴歸展開模型每一步只需要恆定的時間。
- 長上下文:質量和效率共同提高了實際數據的性能,序列長度可達 100 萬。
實驗評估
實證驗證了 Mamba 作爲通用序列基礎模型骨幹的潛力,無論是在預訓練質量還是特定領域的任務性能方面,Mamba 都能在多種類型的模態和環境中發揮作用:
合成任務。在複製和感應頭等重要的語言模型合成任務上,Mamba 不僅能輕鬆解決,而且能推斷出無限長的解決方案(>100 萬 token)。
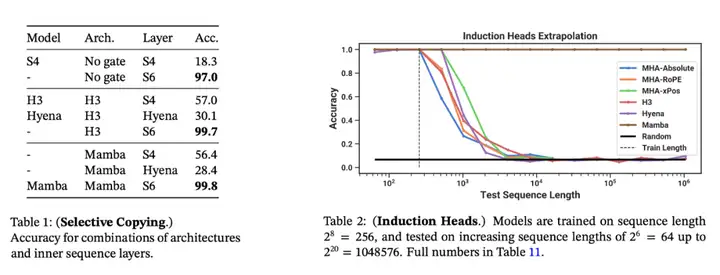
音頻和基因組學。在音頻波形和 DNA 序列建模方面,Mamba 在預訓練質量和下游指標方面都優於 SaShiMi、Hyena、Transformer 等先前的 SOTA 模型(例如,在具有挑戰性的語音生成數據集上將 FID 降低了一半以上)。在這兩種情況下,它的性能隨着上下文長度的增加而提高,最高可達百萬長度的序列。
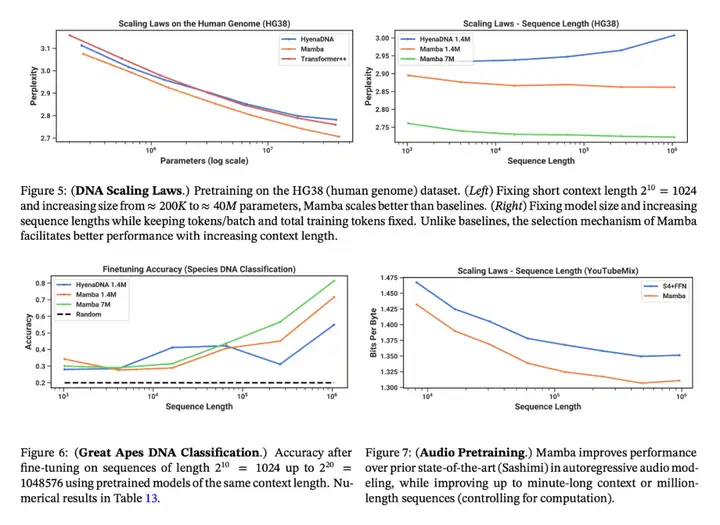
語言建模。Mamba 是首個線性時間序列模型,在預訓練複雜度和下游評估方面都真正達到了 Transformer 質量的性能。通過多達 1B 參數的縮放規律,研究者發現 Mamba 的性能超過了大量基線模型,包括 LLaMa 這種非常強大的現代 Transformer 訓練配方。
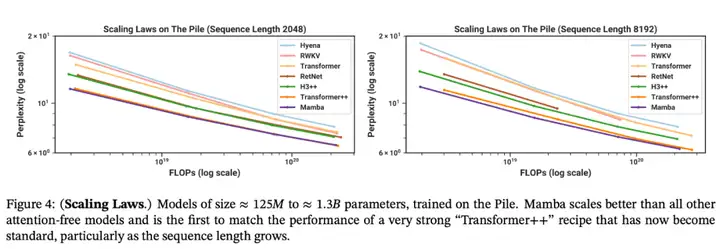
與類似規模的 Transformer 相比,Mamba 具有 5 倍的生成吞吐量,而且 Mamba-3B 的質量與兩倍於其規模的 Transformer 相當(例如,與 Pythia-3B 相比,常識推理的平均值高出 4 分,甚至超過 Pythia-7B)。
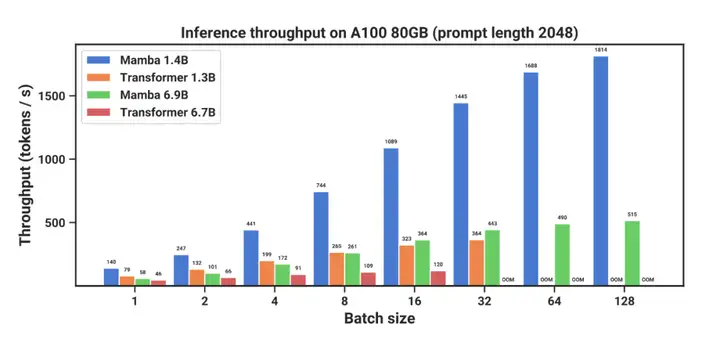



Mamba
- S4 problem: Only time awareness but lack content awareness!!






- Parallel scan: just described
- Kernel fusion
- Recomputation (use computation to trade storage, trick used in flash attention)



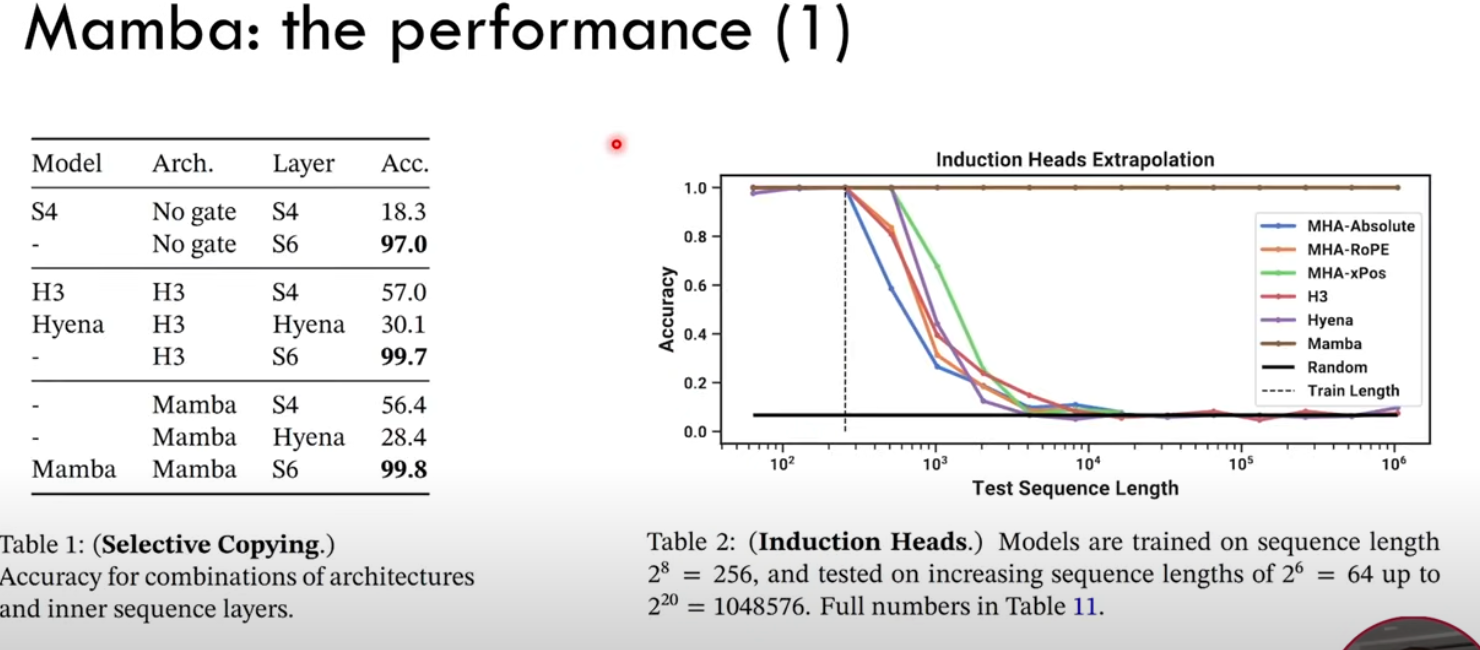
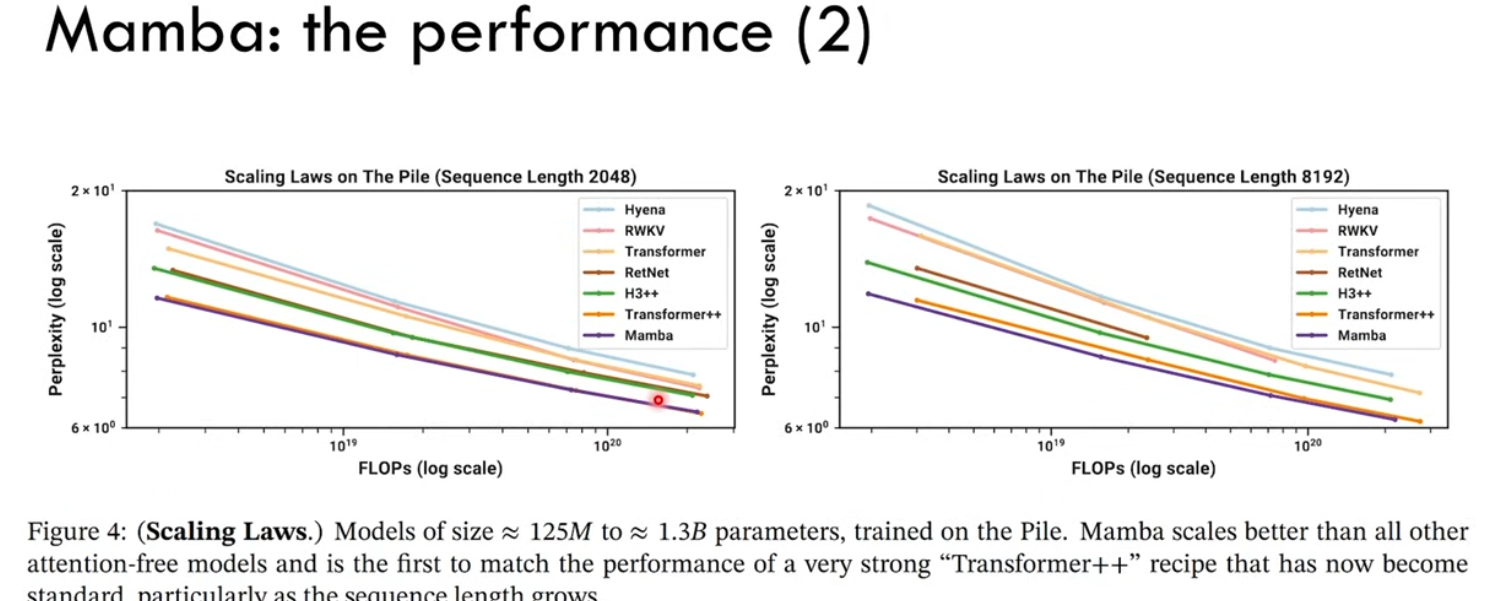
Reference
Hepta. “How to Judge RWKV (arXiv 2305.13048)?,” September 15, 2023. https://www.zhihu.com/question/602564718/answer/3211669817.
| [Efficiently Modeling Long Sequences with Structured State Spaces - Albert Gu | Stanford MLSys #46 (youtube.com)](https://www.youtube.com/watch?v=EvQ3ncuriCM) |
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Paper Explained) (youtube.com)
https://www.youtube.com/watch?v=8Q_tqwpTpVU&ab_channel=UmarJamil
https://www.youtube.com/watch?v=iskuX3Ak9Uk&ab_channel=TrelisResearch. Good!