Source
-
Tiktokenizer 非常有用 online tokenizer!!
-
https://juejin.cn/post/7234795667477561402
-
https://zhuanlan.zhihu.com/p/424631681
-
https://zhuanlan.zhihu.com/p/654745411
-
Excellent YouTube video from Karpathy: https://www.youtube.com/watch?v=zduSFxRajkE&t=505s
開場

GPT2 tokenizer (GPT2=r50K_base) sucks!!!!
- 效率不好 (以下文字要 300 tokens)
- 數字完全隨意
- 空白隨意分,python un-friendly
- 非英語系基本是一字一 token

GPT4 tokenizer (C100K_base)
- 40%-50% more efficient than GPT2 tokenizer (185 vs. 300) becasuse 100K vs. 50K vocab.
- 3 個數字一組,并非 random.
- 空白合為一個 token, python friendly

還有一個系列 (p50k_base)

-
Larger token number (2x, 100K vs. 50K) trade-off
- 資訊被 2x 壓縮,原來的 context length 變一半。等效可以看到 2x longer input context.
- 但是, vocab size 和 embedding table 也變成 2x, bigger softmax operation

Unicode
Unicode sequence in python is:
1 | |
此處尚未 encode 成 bytes.
1 | |
UTF-8/UTF-16/UTF-32 Encode (UTF - Unicode Transformation Format)
Summary:
UTF-8 encode is preferred
- backward compatible to ASCII
- 如果是 English 語系,encode 比較 compact
- 缺點就是 variable length.
UTF-16 在 English 會多了一個 0.
UTF-32 在 English 會多了三個 0. 好處是 fixed length.
1 | |
BPE (Byte-Pair Encode, 也就是 tokenizer)
GPT2: reference: Language Models are Unsupervised Multitask Learners
初识BPE (from Karpathy Let’s build the GPT Tokenizer)
BPE 是一种简单的数据压缩算法,它在 1994 年发表的文章“A New Algorithm for Data Compression”中被首次提出。下面的示例将解释 BPE。老规矩,我们先用一句话概括它的核心思想:
BPE每一步都将最常见的一对*相邻数据单位*替换为该数据中没有出现过的一个*新单位*,反复迭代直到满足停止条件。
是不是听起来懂了却感觉没有完全懂?下面举个例子。
假设我们有需要编码(压缩)的数据 aaabdaaabac。相邻字节对(相邻数据单位在BPE中看作相邻字节对) aa 最常出现,因此我们将用一个新字节 Z 替换它。我们现在有了 ZabdZabac,其中 Z = aa。下一个常见的字节对是 ab,让我们用 Y 替换它。我们现在有 ZYdZYac,其中 Z = aa ,Y = ab。剩下的唯一字节对是 ac,它只有一个,所以我们不对它进行编码。我们可以递归地使用字节对编码将 ZY 编码为 X。我们的数据现在已转换为 XdXac,其中 X = ZY,Y = ab,Z = aa。它不能被进一步压缩,因为没有出现多次的字节对。那如何把压缩的编码复原呢?反向执行以上过程就行了。
Toy example summary
開始 aaabdaaabac: 4 vocabulary or token size {a:0, b:1, c:2, d:3}, 11 token length
最終 XdXac: 7 vocabulary or token size {a:0, b:1, c:2, d:3, X=ZY:4, Y=ab:5, Z=aa:6}, 5 token length
一般例子 BPE “Training”
用 Karpathy 的例一 (token = 533, vocab_size~336, entropy 6.6bit):
這個字串包含 533 字符。經過 UTF-8 encode 之後變成 616 byte sequence。增加來自 non-English 字符。
Unicode! 🅤🅝🅘🅒🅞🅓🅔‽ 🇺🇳🇮🇨🇴🇩🇪! 😄 The very name strikes fear and awe into the hearts of programmers worldwide. We all know we ought to “support Unicode” in our software (whatever that means—like using wchar_t for all the strings, right?). But Unicode can be abstruse, and diving into the thousand-page Unicode Standard plus its dozens of supplementary annexes, reports, and notes can be more than a little intimidating. I don’t blame programmers for still finding the whole thing mysterious, even 30 years after Unicode’s inception.
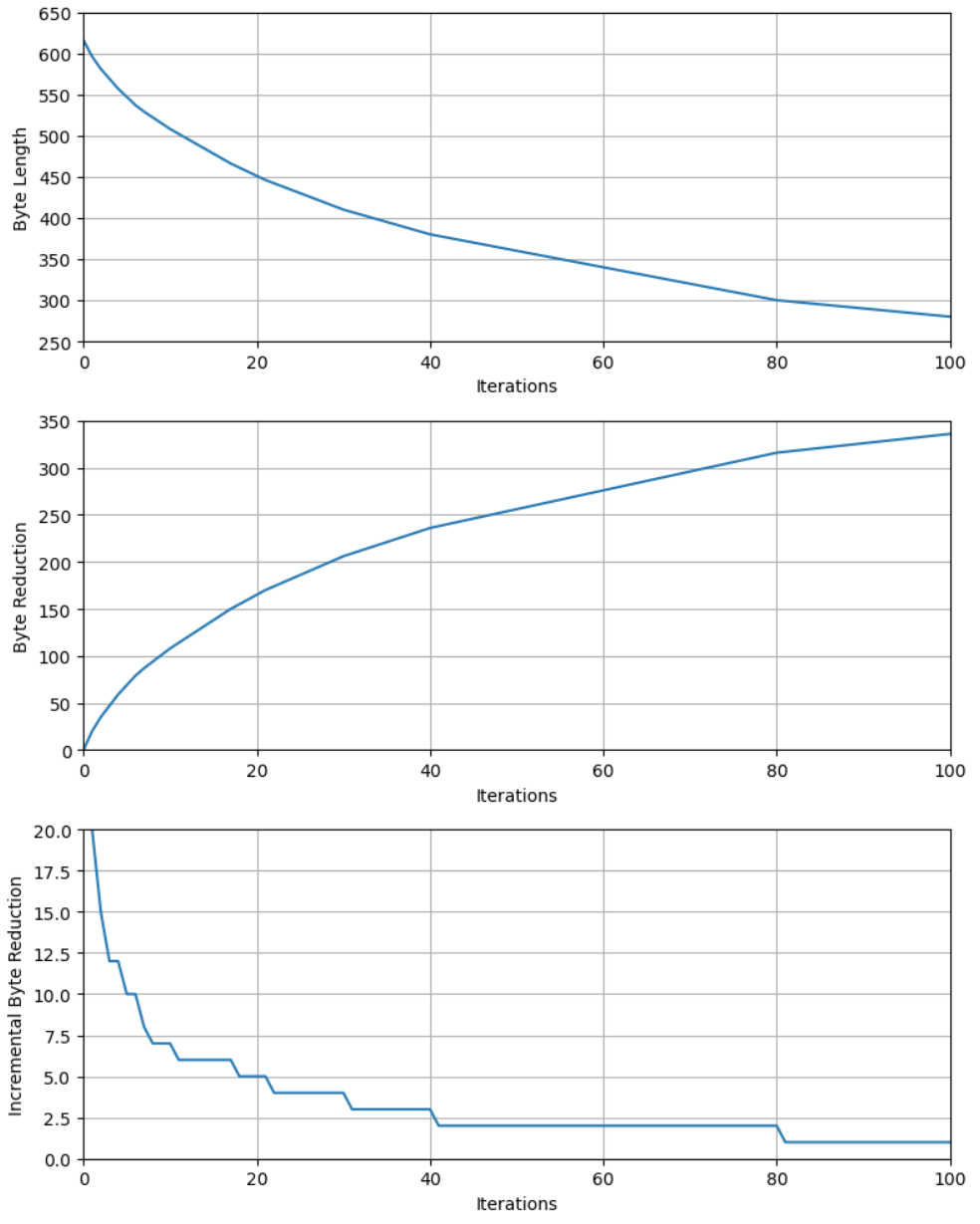
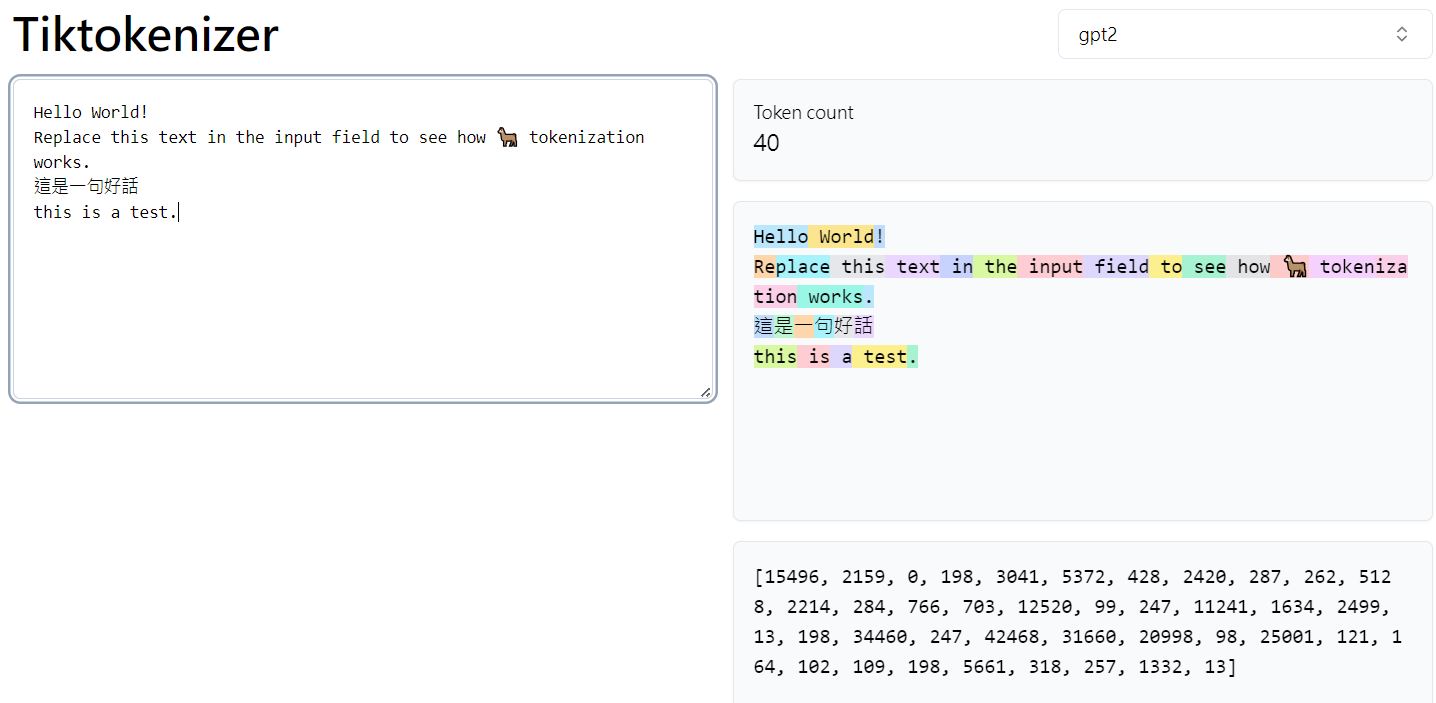
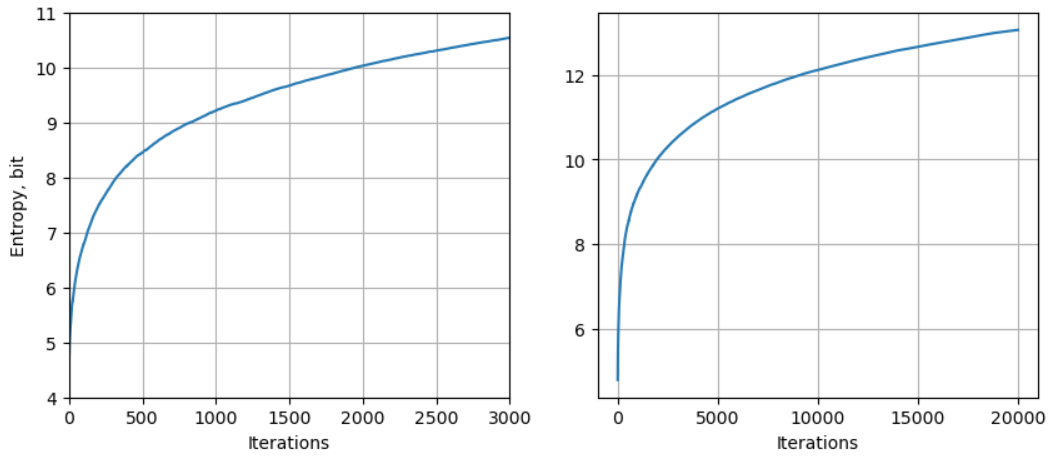
當我們逐步使用 BPE 可以降低 byte length, 如下圖上。如果想看減少多少 byte, 如下圖中;會是一個遞減的收益函數。最後是 incremental byte reduction. 基本從 80 iterations 之後都是增加一個 vocab (token) size 換一個 token length reduction, 沒有任何的 gain!! 反而增加 encode 和 decode 的計算量!! 我們用 entropy 更清楚。
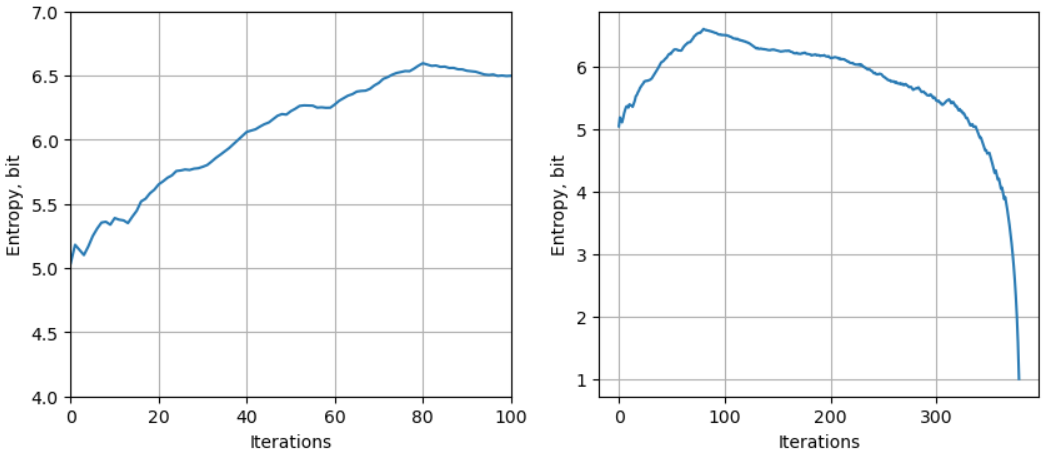
下圖是 self entropy 對 iteration (就是額外的字符) 的趨勢:
- 原始 token distribution (iteration = 0) 的 entropy 最小 (5-bits): 直觀上只有字符出現的頻率 information. 理論上 1-byte uniform distribution 的 entropy 是 8-bit, 不過因爲非 uniform distribution, UTF-8 大約是 5-bit.
- 隨著 iteration 增加,total entropy = 原來字符 information (下降) + 新的 sequence (order) information (上升), 所以 total entropy 增加!
- 原來字符 information 和文章長短關係不大,只要 token 數目遠大於 1-byte (256 tokens), 大約就是 5-bit.
-
等到新的 sequence information 消失 (就是 iteration=80, Incremental byte reduction = 1), 增加 iteration 沒有任何意義,pair 反而減少 token 數目,entropy 開始下降,最後到 1-bit.
- Entropy 的 peak 值大約是 6.6bit. 在 increamental byte reduction = 1 之後會掉下去。Vocab size = 256+80 ~ 336.
開始 256 (1-byte) vocabulary byte sequence -> 形成 byte-pair (這也是 BPE 的來源),遞回次數決定多少新的 vocabulary
256, 257, ….. 由 training code book: {0x0:0, 0x1:1, 0x2:2, 0x3:3, ….0xff: 255, ‘0x1 0x9’: 256, ‘0x70 0x9’: 257, ….}
-
vocab_size = 256 + iterations
-
下表可見 appendix
| Token Length | Vocab Size (256+peak entropy iteration) |
Initial Entropy | Peak Entropy | |
|---|---|---|---|---|
| Unicode article | 616 | 336 | 5 bit | 6.6 bit |
| Unicode article | 24.6K | 2.2K | 5 bit | 10.2 bit |
| Shakespeare | 1.1M | 20~50K | 4.8 bit | 13~14 bit |
Summary
- 上面都是 training 一個 dataset. 應該有 overfit 的問題。計算 entropy 應該要用不同的 dataset 驗證?
- Inference 包含 encode 和 decode 兩個部分。都是用查表?
BPE Encode and Decode
Tokenizer is independent of the LLM!! Can be tuned or trained separately, 但是用非常簡單的 algorithm + statistics, not ai algorithm!

Q: Chinese characters tokenizer counts?
Q: trans-tokenizer
Q: 統計各種 tokenzier 對於壓縮的對比,借此來做 transcoder. like bigram in Karpathy’s example.
Q: 使用 Viterbi 或是科學空間的方法來處理 tokenizer.
兩類 BPE
以上的 BPE 例子是 OpenAI 的 tiktoken. 還有另一個系列是 Google 和 Meta 使用的 sentencepiece tokenizer. 下圖是 llama 使用的 tokenzier.
- 最重要的特點是 character coverage 並不是 100%, 而是可以設定的值!
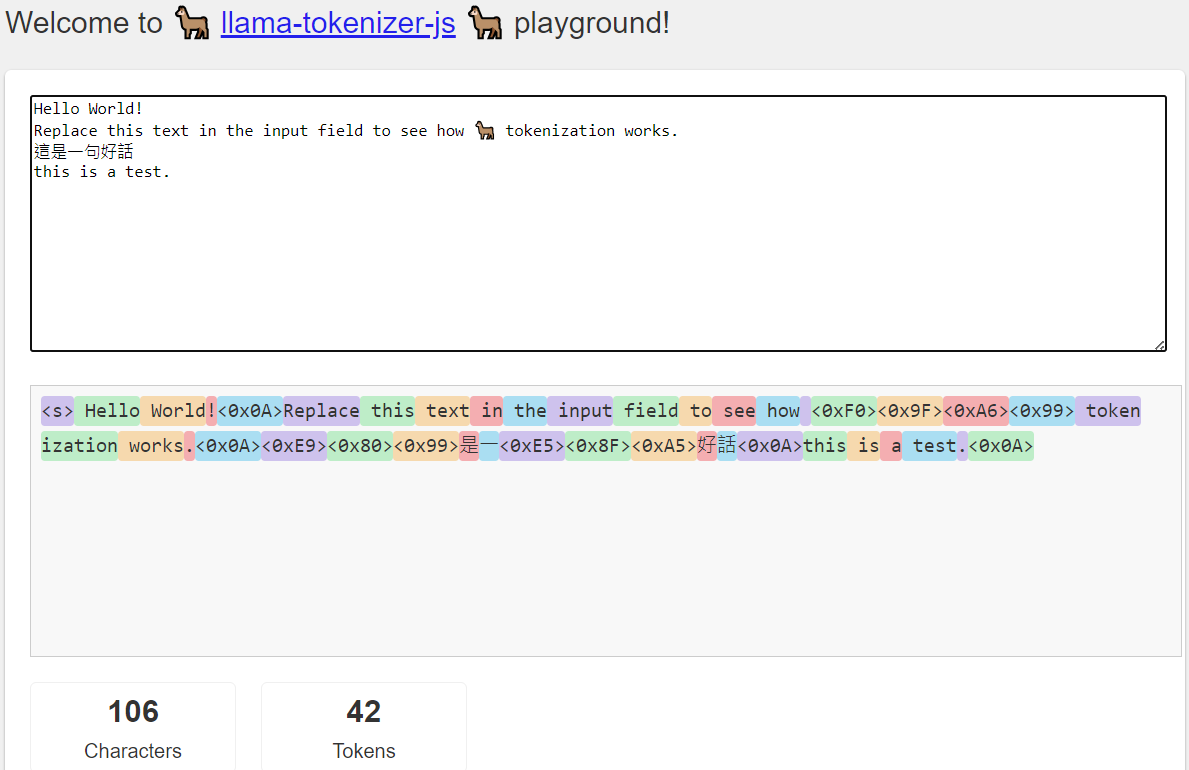
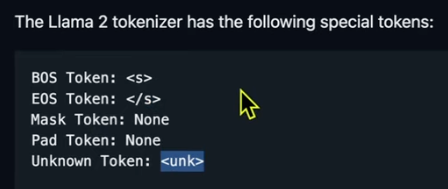
- 對於不直接 encode 的 character, 搭配 byte_fallback, 會改成 utf-8 bytes 如下圖。
- “這是一句好話”:“這” “句” 都 fall back 成 byte 表示。
- 自動加 space token (在 Hello 之前) 以及其他 extra tokens (e.g.
). 稱爲 normalization.
| GPT-like | Llama-like | |
|---|---|---|
| Use case | GPT2/4, minbpe | Llama series, Mistral series |
| Pip | tiktoken | sentencepiece |
| Vocab_size | 50257 (GPT2), 100257 (GPT4) | 32000 (Llama), ~250K (Gemma) |
| Training/Inference tokenizer 這裡指 tokenizer, 和 LLM 無關 |
不同 (OpenAI 只 disclose inference tokenizer) | 相同 (可以 training 自己 tokenizer) |
| Normalization (改動 token) | No | Yes |
| Legacy | 很少,code is clean | 很多,code is messy |
| Training 過程 | Text -> utf8 code (1-4 byte number) -> BPE bytes | Text -> BPE raw byte -> fall back to utf-8 byte |
- tiktoken encodes to utf-8 and then BPEs bytes
- sentencepiece BPEs the code points and optionally falls back to utf-8 bytes for rare code points (rarity is determined by character_coverage hyperparameter), which then get translated to byte tokens.
不是很確定兩者的差別?似乎在 GPT-like tokenizer 在對 English / non-English 的差異比較小。但在 Llama tokenizer 對 English / non-English 差異很大? 所以 GPT 對中日韓文比較好?
Appendix
用 Karpathy 的例一 (token = 533, vocab_size~336, entropy 6.6bit):
這個字串包含 533 字符。經過 UTF-8 encode 之後變成 616 byte sequence。增加來自 non-English 字符。
Unicode! 🅤🅝🅘🅒🅞🅓🅔‽ 🇺🇳🇮🇨🇴🇩🇪! 😄 The very name strikes fear and awe into the hearts of programmers worldwide. We all know we ought to “support Unicode” in our software (whatever that means—like using wchar_t for all the strings, right?). But Unicode can be abstruse, and diving into the thousand-page Unicode Standard plus its dozens of supplementary annexes, reports, and notes can be more than a little intimidating. I don’t blame programmers for still finding the whole thing mysterious, even 30 years after Unicode’s inception.
當我們逐步使用 BPE 可以降低 byte length, 如下圖上。如果想看減少多少 byte, 如下圖中;會是一個遞減的收益函數。最後是 incremental byte reduction. 基本從 80 iterations 之後都是增加一個 vocab (token) size 換一個 token length reduction, 沒有任何的 gain!! 反而增加 encode 和 decode 的計算量!!
Entropy 的 peak 值大約是 6.6bit. 在 increamental byte reduction = 1 之後會掉下去。Vocab size = 256+80 ~ 336.
用 Karpathy 的例二 (token = 24.6K, vocab_size~2.2K, entropy~10.2bit):
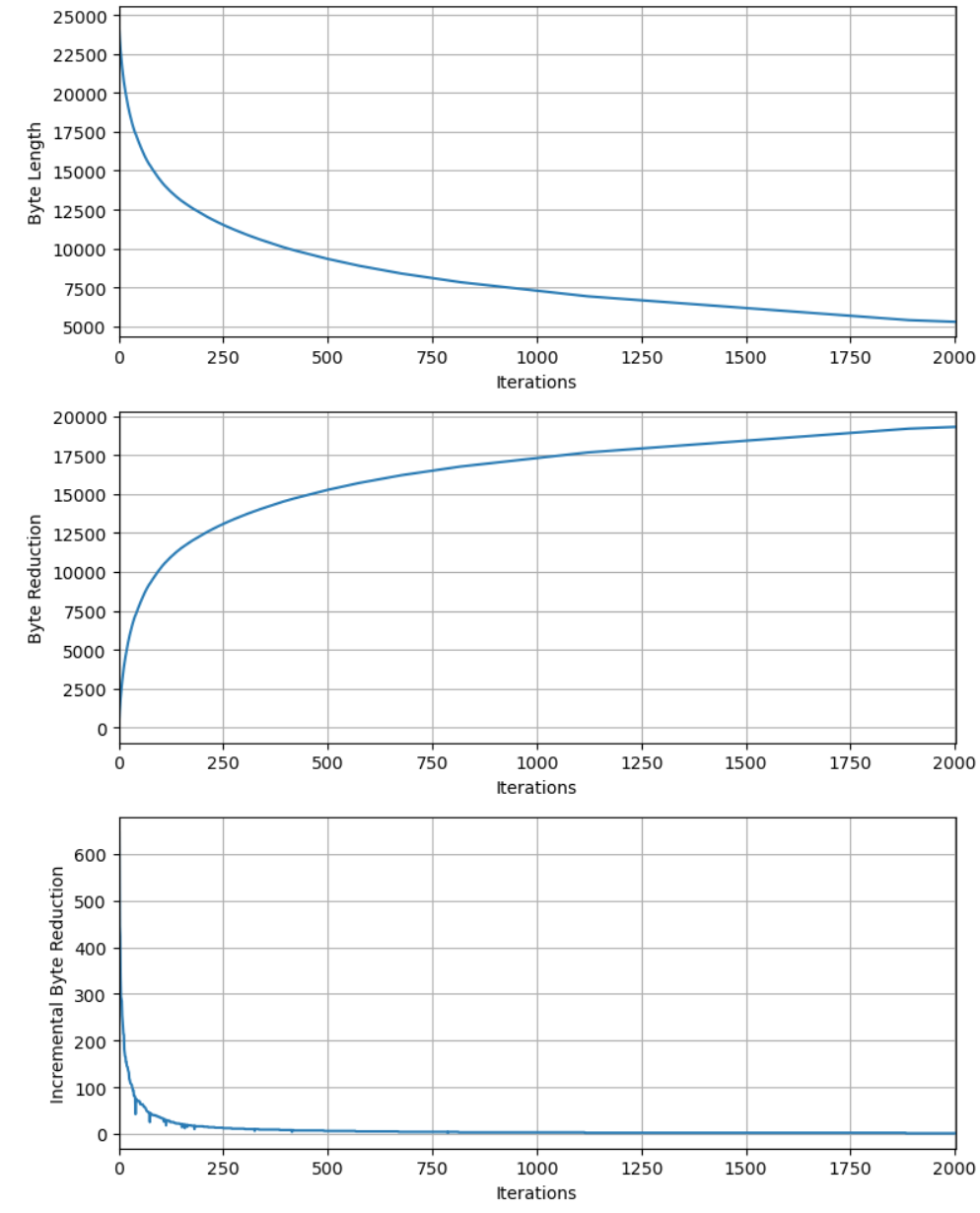
再試上文的全文,約 24597 bytes (UTF-8)。經過 2000 iterations: 最大 entropy 約在10.2 bits@1900 iteration. Vocab size ~ 1900+256=2156.
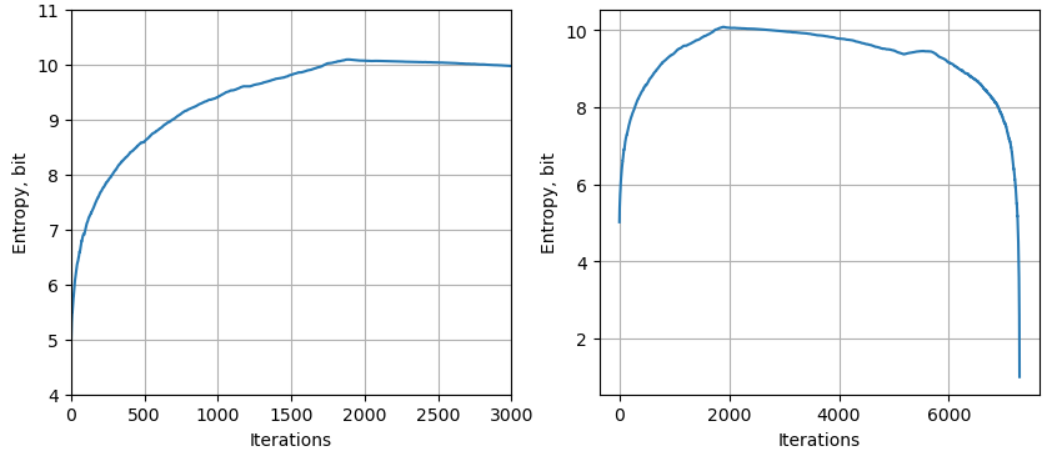
用 Karpathy 的例三 (token = 1.1M, vocab_size > 1K, entropy > 10.2bit):
莎士比亞的文章,一共有 1,115,393 字母。前 100 個字母 (含空白)如下:
2
3
4
5
6
7
8First Citizen: Before we proceed any further, hear me speak. All: Speak, speak. First Citizen: You
經過 UTF-8 encode 之後的 byte number 仍然是 1,115,393. 我們依樣畫葫蘆,可以得到以下的圖。
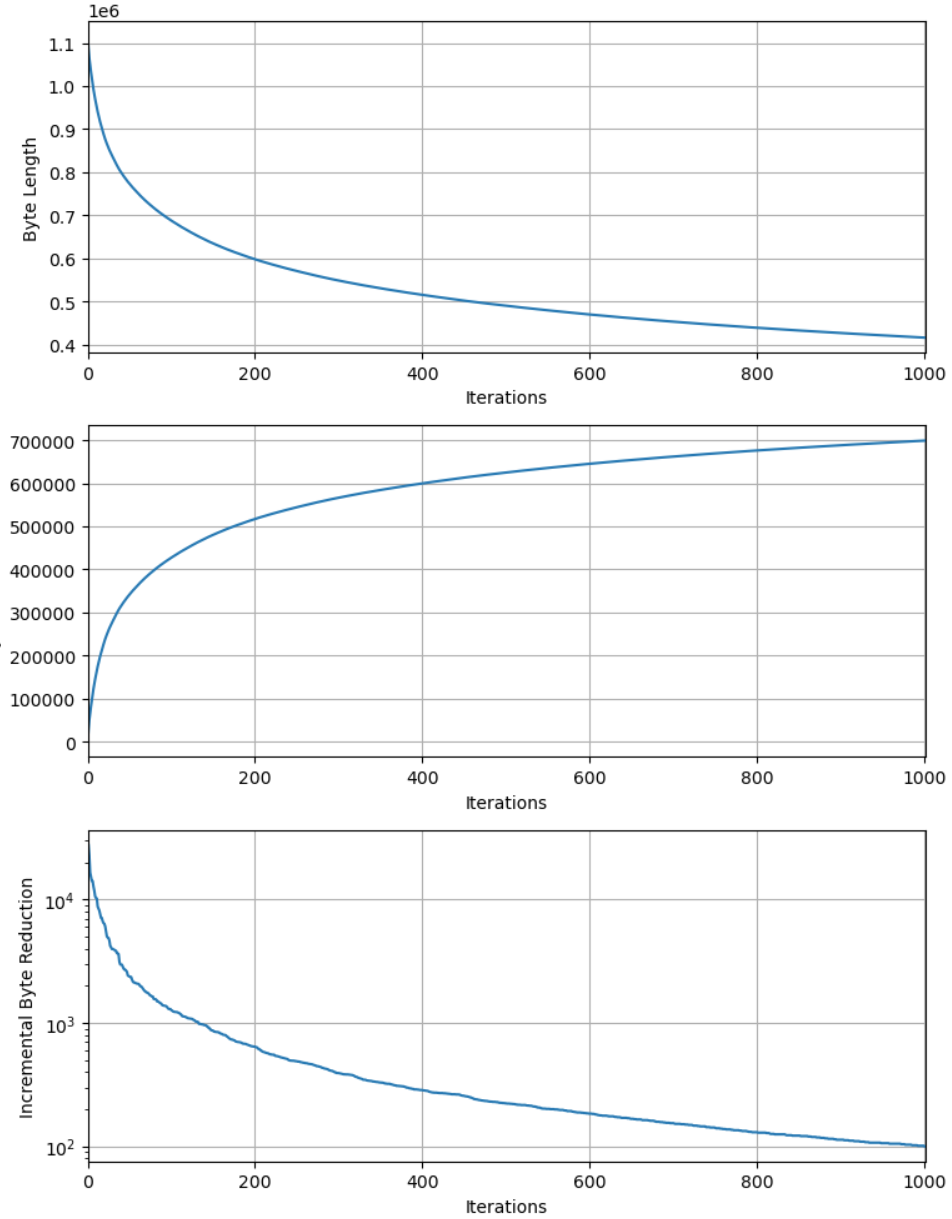
Entropy > 13 bits.
- 使用 normalization 改成 percentage or entropy 看是否有物理意義 English, Chinese, ….
Tokenizer
- character level encoder: codebook 65
- BPE (byte-pair encoder)
- GPT2-3: codebook 50541?
- Tiktoken (OpenAI)
基本是 trade-off of the codebook vs. the token length!
@guodongLLMTokenizer2023
背景
隨着ChatGPT迅速出圈,最近幾個月開源的大模型也是遍地開花。目前,開源的大語言模型主要有三大類:ChatGLM衍生的大模型(wenda、ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera等)、Bloom衍生的大模型(Bloomz、BELLE、Phoenix等)。其中,ChatGLM-6B主要以中英雙語進行訓練,LLaMA主要以英語爲主要語言的拉丁語系進行訓練,而Bloom使用了46種自然語言、13種編程語言進行訓練。
| 模型 | 訓練數據量 | 模型參數 | 訓練數據範圍 | 詞表大小 | 分詞算法 |
|---|---|---|---|---|---|
| LLaMA | 1T~1.4T tokens(其中,7B/13B使用1T,33B/65B使用1.4T) | 7B~65B | 以英語爲主要語言的拉丁語系 | 32K | BBPE |
| ChatGLM-6B | 約 1T tokens | 6B | 中英雙語 | 130K | BBPE |
| Bloom | 1.6TB預處理文本,轉換爲 350B 唯一 tokens | 300M~176B | 46種自然語言,13種編程語言 | 250K | BBPE |
| GPT2 | ? | 50K | Tiktoken |
目前來看,在開源大模型中,LLaMA無疑是其中最閃亮的星。但是,與ChatGLM-6B和Bloom原生支持中文不同。LLaMA 原生僅支持 Latin 或 Cyrillic 語系,對於中文支持不是特別理想。原版LLaMA模型的詞表大小是32K,而多語言模型(如:XLM-R、Bloom)的詞表大小約爲250K。以中文爲例,LLaMA詞表中的中文token比較少(只有幾百個)。這將導致了兩個問題:
- LLaMA 原生tokenizer詞表中僅包含少量中文字符,在對中文字進行tokenzation時,一箇中文漢字往往被切分成多個token(2-3個Token才能組合成一個漢字),顯著降低編解碼的效率。
- 預訓練中沒有出現過或者出現得很少的語言學習得不充分。
爲了解決這些問題,我們可能就需要進行中文詞表擴展。比如:在中文語料庫上訓練一箇中文tokenizer模型,然後將中文 tokenizer 與 LLaMA 原生的 tokenizer 進行合併,通過組合它們的詞彙表,最終獲得一個合併後的 tokenizer 模型。
本文將介紹使用SentencePiece工具如何使用中文語料訓練一個分詞模型。
Coding 例子
1 | |
如何得到 tokenizer? 當然也是 pretrain 得來的。不過一般我們只引用固定的 tokenizer.
答案是肯定的,Tokenizer也是在庞大的预训练语料上训练出来的,只不过由于计算需求相对训练模型少很多。
而在LLAMA中,作者使用的是SentencePiece得到最后的词典,Tokenizer的基座也是SentencePiece中的SentencePieceProcessor类[2], 如下图红框所示,LLAMA的encode过程实际上是通过SentencePiece实现的。
預備知識
講解 SentencePiece 之前,我們先講解下分詞器(Tokenizer)。
那什麼是分詞器?簡單點說就是將字符序列轉化爲數字序列,對應模型的輸入。
通常情況下,Tokenizer有三種粒度:word/char/subword
- word: 按照詞進行分詞,如:
Today is sunday. 則根據空格或標點進行分割[today, is, sunday, .] - character:按照單字符進行分詞,就是以char爲最小粒度。 如:
Today is sunday.則會分割成[t, o, d,a,y, .... ,s,u,n,d,a,y, .] - subword:按照詞的subword進行分詞。如:
Today is sunday.則會分割成[to, day,is , s,un,day, .]
可以看到這三種粒度分詞截然不同,各有利弊。
對於word粒度分詞:
- 優點:詞的邊界和含義得到保留;
- 缺點:1)詞表大,稀有詞學不好;2)OOV(可能超出詞表外的詞);3)無法處理單詞形態關係和詞綴關係,會將兩個本身意思一致的詞分成兩個毫不相同的ID,在英文中尤爲明顯,如:cat, cats。
對於character粒度分詞:
- 優點:詞表極小,比如:26個英文字母幾乎可以組合出所有詞,5000多箇中文常用字基本也能組合出足夠的詞彙;
- 缺點:1)無法承載豐富的語義,英文中尤爲明顯,但中文卻是較爲合理,中文中用此種方式較多。2)序列長度大幅增長;
最後爲了平衡以上兩種方法, 又提出了基於 subword 進行分詞:它可以較好的平衡詞表大小與語義表達能力;常見的子詞算法有Byte-Pair Encoding (BPE) / Byte-level BPE(BBPE)、Unigram LM、WordPiece、SentencePiece等。
- BPE:即字節對編碼。其核心思想是從字母開始,不斷找詞頻最高、且連續的兩個token合併,直到達到目標詞數。
- BBPE:BBPE核心思想將BPE的從字符級別擴展到子節(Byte)級別。BPE的一個問題是如果遇到了unicode編碼,基本字符集可能會很大。BBPE就是以一個字節爲一種“字符”,不管實際字符集用了幾個字節來表示一個字符。這樣的話,基礎字符集的大小就鎖定在了256(2^8)。採用BBPE的好處是可以跨語言共用詞表,顯著壓縮詞表的大小。而壞處就是,對於類似中文這樣的語言,一段文字的序列長度會顯著增長。因此,BBPE based模型可能比BPE based模型表現的更好。然而,BBPE sequence比起BPE來說略長,這也導致了更長的訓練/推理時間。BBPE其實與BPE在實現上並無大的不同,只不過基礎詞表使用256的字節集。
- WordPiece:WordPiece算法可以看作是BPE的變種。不同的是,WordPiece基於概率生成新的subword而不是下一最高頻字節對。WordPiece算法也是每次從詞表中選出兩個子詞合併成新的子詞。BPE選擇頻數最高的相鄰子詞合併,而WordPiece選擇使得語言模型概率最大的相鄰子詞加入詞表。
- Unigram:它和 BPE 以及 WordPiece 從表面上看一個大的不同是,前兩者都是初始化一個小詞表,然後一個個增加到限定的詞彙量,而 Unigram Language Model 卻是先初始一個大詞表,接着通過語言模型評估不斷減少詞表,直到限定詞彙量。
- SentencePiece:SentencePiece它是谷歌推出的子詞開源工具包,它是把一個句子看作一個整體,再拆成片段,而沒有保留天然的詞語的概念。一般地,它把空格也當作一種特殊字符來處理,再用BPE或者Unigram算法來構造詞彙表。SentencePiece除了集成了BPE、ULM子詞算法之外,SentencePiece還能支持字符和詞級別的分詞。
下圖是一些主流模型使用的分詞算法,比如:GPT-1 使用的BPE實現分詞,LLaMA/BLOOM/GPT2/ChatGLM使用BBPE實現分詞。BERT/DistilBERT/Electra使用WordPiece進行分詞,XLNet則採用了SentencePiece進行分詞。
從上面的表格中我們也可以看到當前主流的一些開源大模型有很多基於 BBPE 算法使用 SentencePiece 實現
Some Topics
-
Tokenizer conversion: 例如把 Llama tokenizer 轉換成 GPT tokenizer. 好處是 (1) 可以 cascade 不同 tokenizer models. (2) mixed (parallel) 不同 tokenizer models.
-
Tokenizer merge: English tokenizer and Chinese tokenizer for English and Chinese.
Tokenizer Conversion for Cascaded Model
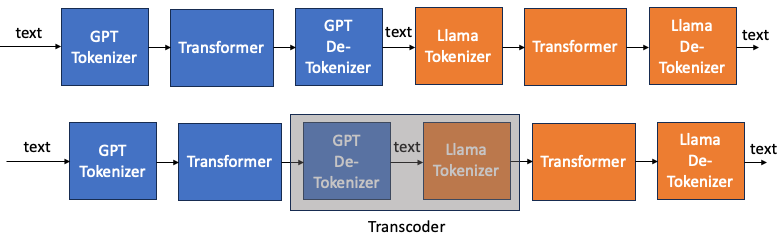
下圖一是兩個不同 tokenizer LLM model 串接。一個例子就是 speculative decode 的 draft mode 和 original model, Draft model 可能使用一個小模型使用和 original 模型不同的 tokenizer.
最直覺的方法就是把 GPT transformer 的 GPT token 先轉換成 text,再由 Llama tokenizer 轉換成 Llama tokens. 這好像是一個可行的方法,基本是兩次的 table lookup (de-tokenizer + tokenizer)。
一個問題是我們是否可以訓練一個 transcoder model, 類似翻譯。從 GPT token 轉換成 Llama token?
先不論是否划算,因為一個 transcoder 可能比兩次的 table lookup 更複雜。但也有可能更簡單。因為 table 都是很大的 table (32K or 50K 參數)。也許簡單的 transcoder (CNN, RNN, or transformer) 可以達成同樣的結果。
如何 train 這個 transcoder?
上圖 transcoder 很難訓練,因為 input token 和 output token 很難產生。如果勉強用完整的圖一,還會與 transformer 有關。是否可以有容易的 input and output tokens, 並且和 transformer 無關的方法? YES!
下圖是 transcoder 等價的方塊圖。如果要得到一個 GPT de-tokenizer to Llama tokenizer 的transcoder。 相當於訓練一個 input text to GPT tokenizer 而 output 是相同 text to Llama tokenizer 的 transcoder.
因為 text, Llama tokenizer, GPT tokenizer 都是已知。並且整個訓練和 transformer 完全無關!
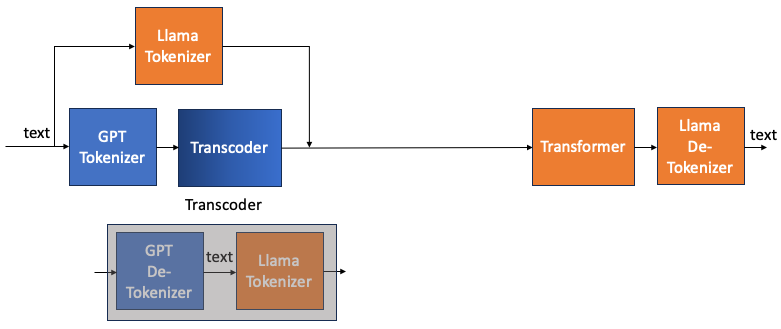
可以推廣如果要做一個 A de-tokenizer to B tokenizer 的 transcoder, 可以用 text to A tokenizer 為 input, 同樣 text to B tokenizer 為 output. 用這樣 (input, output) 對訓練 model (CNN, RNN, or transformer)
- 一個 trick 是 transcoder 的 vocab size 需要是兩個 tokenizers 的大者。以免 transcoder 會 out of range.
Merge Tokenizer
https://discuss.tensorflow.org/t/is-there-an-existing-tokenizer-model-for-chinese-to-english-translation/4520
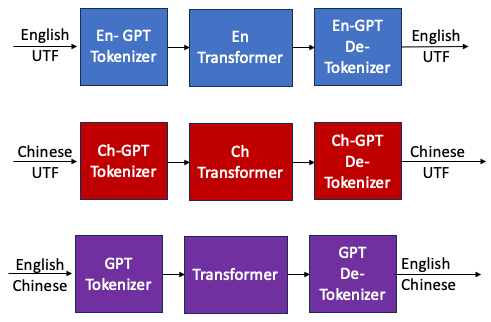
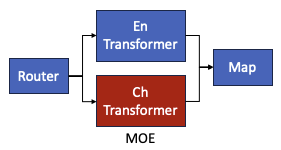
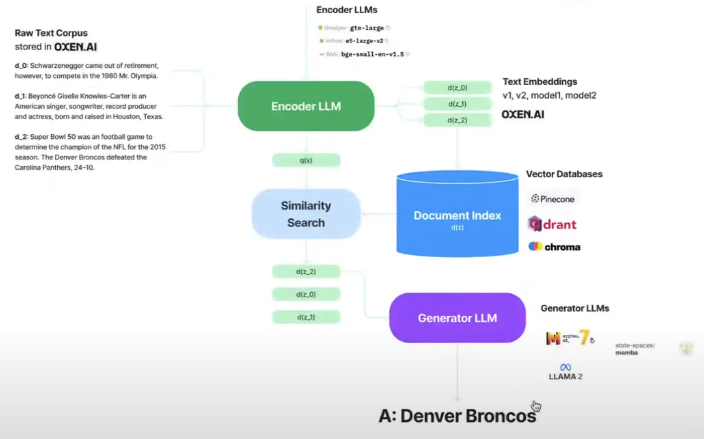
En-Tranformer 和 Ch-Transformer 可以用 MoE 解決!!!
RAG: LLM encoder and LLM generator 可以用不同的 tokenizers!