Source
Colab使用教程(超级详细版)及Colab Pro/Pro+评测 - 知乎 (zhihu.com)
Google Colab 的正确使用姿势 - 知乎 (zhihu.com)
Colab Pro 值得花 9.9$/mon 订阅吗?来看这篇完整评测 - 知乎 (zhihu.com)
Argparse: https://colab.research.google.com/github/anthony-agbay/introduction-to-python/blob/main/modules/introduction-argparse-pt1/introduction-argparse-pt1.ipynb#scrollTo=70ApDftOmCKk
Takeaway
性价比较高的组合是:每月 $3 的 Google Drive + 每月 $11 Colab Pro。
Why Colab
雖然我自己有 GTX1080 8GB 和 RTX3060 12GB, 但有兩個問題 (1) 自己的 GPU 還是太慢; (2) 如果在外面使用 Mac Book Air, 還是需要雲的 GPU 處理。我看了一下選擇 Google Colab Pro ($10.49 / month). 好處是可以使用 Nvidia V100 和 A100 (比較難連上) 以及更大的 DRAM (50GB?),可以節省不少時間。
因此我的計劃:
- Prototype 就用 GTX1080 8GB or RTX3060 12GB。
- 一旦 debug 完畢, 使用 Colab GPU 執行。
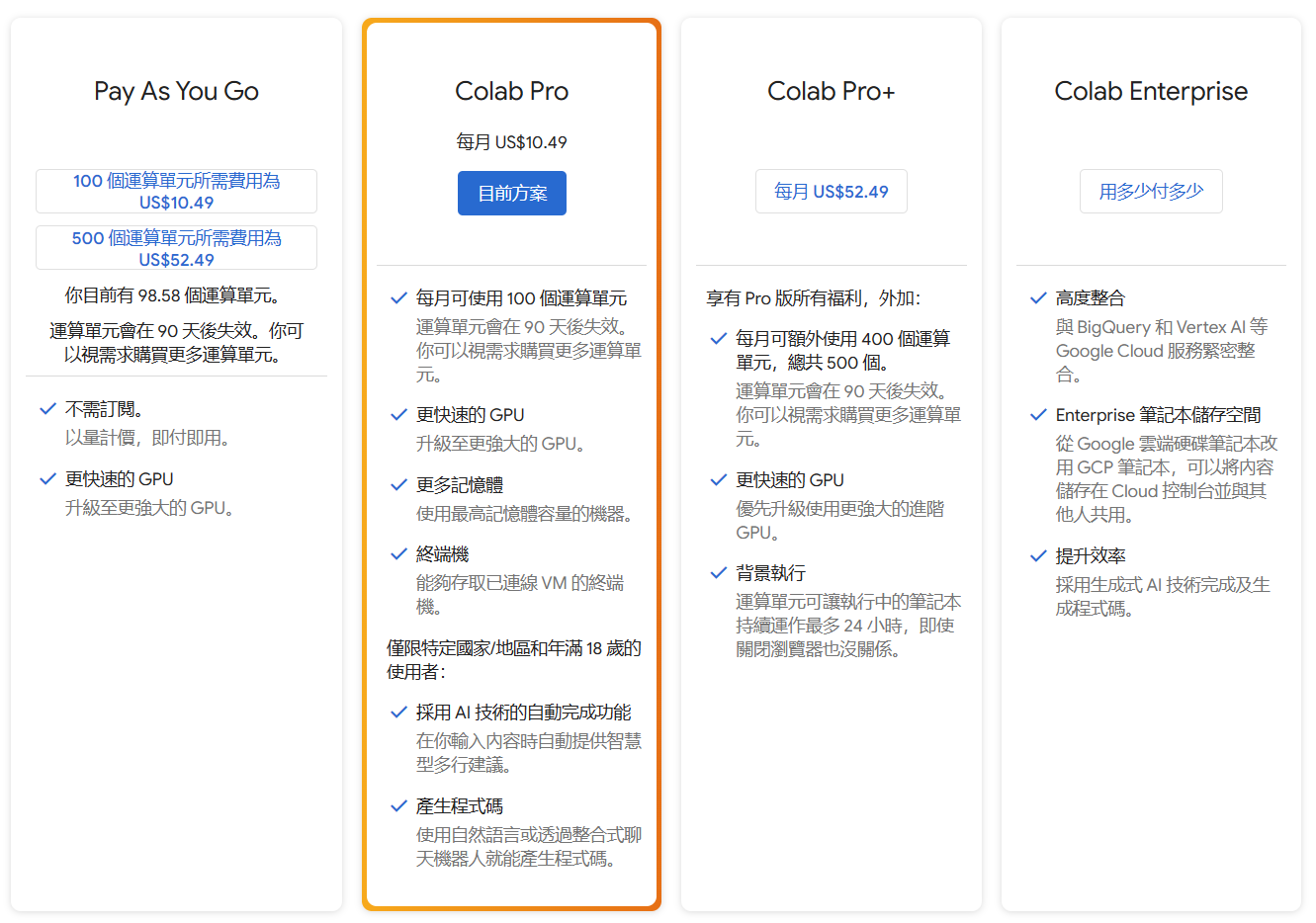
Colab 介紹
Colab = Colaboratory(即合作实验室),是谷歌提供的一个在线工作平台,用户可以直接通过浏览器执行python代码并与他人分享合作。Colab的主要功能在提供的GPU。
Jupyter Notebook:在Colab中,python代码的执行是基于.ipynb文件,也就是Jupyter Notebook格式的python文件。这种笔记本文件与普通.py文件的区别是可以分块执行代码并立刻得到输出,同时也可以很方便地添加注释,这种互动式操作十分适合一些轻量的任务。
代码执行程序:代码执行程序就是Colab在云端的”服务器”。简单来说,我们先在笔记本写好需要运行的代码,连接到代码执行程序,然后Colab会在云端执行代码,最后把结果传回浏览器。
实例空间:连接到代码执行程序后,Colab需要为其分配实例空间(Instance),可以简单理解为运行笔记本而创建的”虚拟机”,其中包含了执行ipynb文件时的默认配置、环境变量、自带的库等等。
会话:当笔记本连接到代码执行程序并分配到实例空间后,就成为了一个会话(Session),用户能开启的回话数量是有限的

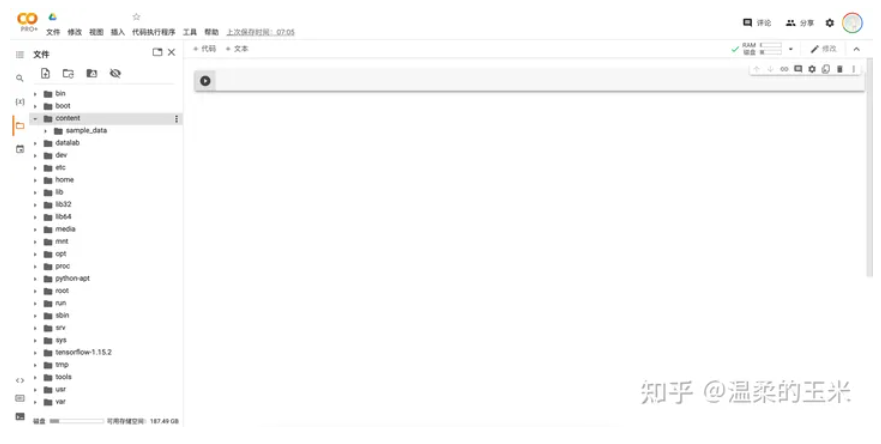
在打开笔记本后,我们默认的文件路径是“/content”,这个路径也是执行笔记本时的路径,同时我们一般把用到的各种文件也保存在这个路径下。在点击”..”后即可返回查看根目录”/”(如下图),可以看到根目录中保存的是一些虚拟机的环境变量和预装的库等等。
不要随意修改根目录中的内容,以避免运行出错,我们所有的操作都应在“/content”中进行。
Colab from Scratch
最簡單的方法就是直接創建 jupyter notebook.
新建笔记本
有两种方法可以新建一个笔记本,第一种是在在云端硬盘中右键创建。
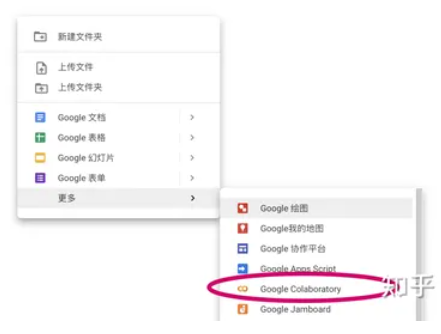
第二种方法是直接在浏览器中输入https://colab.research.google.com,进入Colab的页面后点击新建笔记本即可。使用这种方法新建的笔记本时,会在云端硬盘的根目录自动创建一个叫Colab Notebook的文件夹,新创建的笔记本就保存在这个文件夹中。
上傳所有的 jupyter notebook and data.

不過真的太麻煩。比較適合几个轻量的模块,也不打算使用git进行版本管理,则直接将这些模块上传到实例空间即可。或是從下載網路的 notebook.
Google Drive + Colab
Colab一般配合Google Drive使用(下文会提到这一点)。因此如有必要,我建议拓展谷歌云端硬盘的储存空间,个人认为性价比较高的是基本版 (100GB, NTD 65/month) 。
执行代码块
notebook文件通过的代码块来执行代码,同时支持通过”!
1 | |
Let’s try an example.
1 | |
加载数据集
在深度学习中,我们常常需要加载超大量的数据集,如何在Colab上快速加载这些数据?
- 将整个数据集从本地上传到实例空间
理论可行但实际不可取。经过作者实测,无论是上传压缩包还是文件夹,这种方法都非常的浪费时间,对于较大的数据集不具备可操作性。
- 将整个数据集上传到谷歌云盘,挂载谷歌云盘的之后直接读取云盘内的数据集
理论可行但风险较大。根据谷歌的说明,Colab读取云盘的I/O次数也是有限制的,太琐碎的I/O会导致出现“配额限制”。而且云盘的读取效率也低于直接读取实例空间中的数据的效率。
为什么云端硬盘操作有时会因配额问题而失败?research.google.com/colaboratory/faq.html#drive-quota
- 将数据集以压缩包形式上传到谷歌云盘,然后解压到Colab实例空间
实测可行。挂载云盘不消耗时间,解压所需的时间远远小于上传数据集的时间。
此外,由于实例空间会定期释放,因此模型训练完成后的日志也应该储存在谷歌云盘上。综上所述,谷歌云盘是使用Colab必不可少的一环,由于免费的云盘只有15个G,因此建议至少拓展到基本版。
如何執行 Python?
有些時候我們希望直接執行 python file. 可以利用下列方法:
1 | |
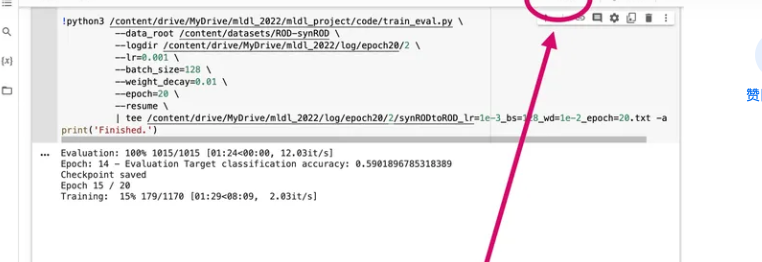
如何让代码有“断点续传”的能力?
由于Colab随时有可能断开连接,在Colab上训练模型的代码必须要有可恢复性(能载入上一次训练的结果)。我把两个分别实现保存和加载checkpoint的函数附在下方,给大家作参考(基于pytorch)。
1 | |
在主程序train.py正式开始训练前,添加下面的语句:
if args.resume: # args.resume是命令行输入的参数,用于指示要不要加载上次训练的结果
first_epoch = load_checkpoint(checkpoint_path, first_epoch, net_list, optims_list)
在每个epoch训练结束后,保存checkpoint:
# Save checkpoint
save_checkpoint(checkpoint_path, epoch, net_list, optims_list)
net_list是需要保存的网络列表,optims_list是需要保存的优化器列表
这里没有记录scheduler的列表,如果代码里用到了scheduler,那也要保存scheduler的列表。
Command-Line Argpase
可以利用以下方法和 argparse 共用 or for debugging purpose.
In addition to positional arguments, there is second type of argument: the optional argument. As the name suggests, optional arguments do not need to be passed when a script is called. Instead, you use an optional argument by passing in a name-value pair (e.g., -arg value). To indicate that an argument is optional, you append a - to a short name (e.g., a single letter) and a -- to a long name (e.g., word). By convention, you should have both a short and long name for an optional argument.
1 | |
1 | |
Argument 1: 5
Argument 1: 5
Argument 2: Optional Argument
Reference
WSL2: VSCode + Conda + Formatter使用設定: https://medium.com/@mh.yang/wsl2-vscode-conda-formatter%E4%BD%BF%E7%94%A8%E8%A8%AD%E5%AE%9A-acca390e94c8
(知乎) win10+wsl2+vs code+python平台搭建笔记
(知乎) WSL2: VSCode + Virtualenv的使用与配置 (知乎)
https://code.visualstudio.com/blogs/2019/09/03/wsl2