Source
- 使用haggingface datasets高效加载数据 - 知乎 (zhihu.com)
- Loading a Dataset — datasets 1.2.1 documentation (huggingface.co)
- pytorch使用总结(一) dataloader - 知乎 (zhihu.com)
- PyTorch教程-5:详解PyTorch中加载数据的方法–Dataset、Dataloader、Sampler、collate_fn等 - 简书 (jianshu.com)
- pytorch-sentiment-analysis/1 - Neural Bag of Words.ipynb at main · bentrevett/pytorch-sentiment-analysis (github.com) Excellent example!
機器學習的 A (Algorithm), B (Big data), C (Computation)
A: CNN -> Transformer -> Mamba/RWKV/…
B: Multi-modality dataset
C: Model size, long context
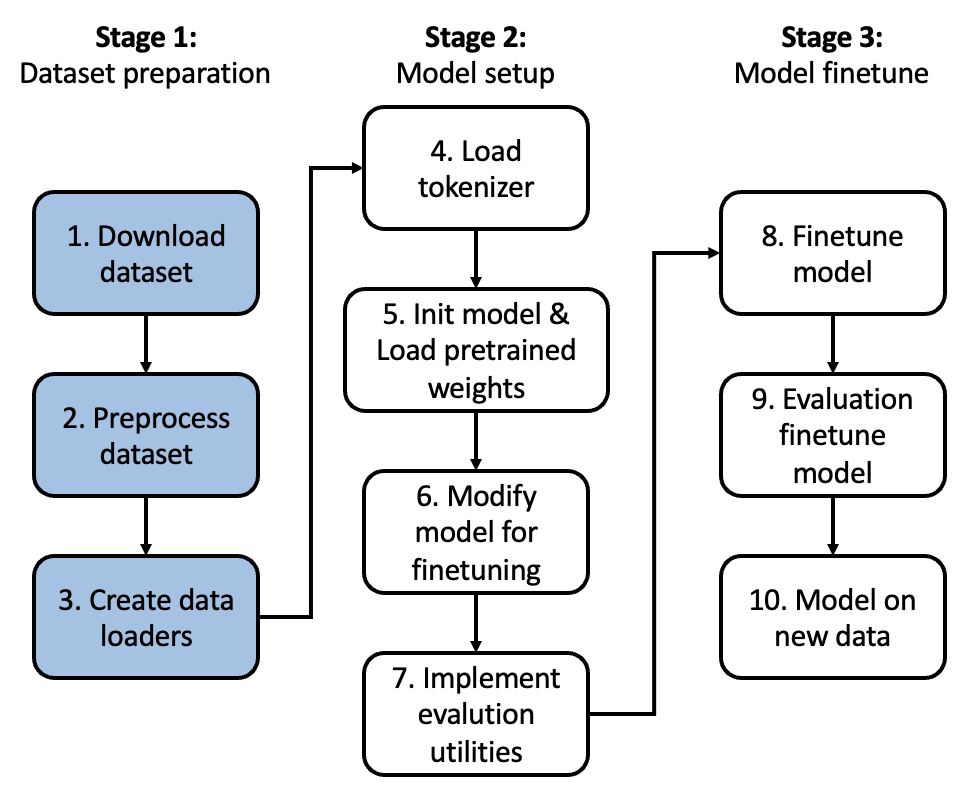
我們從 Stage 1 開始說起:下載 datasets (Dataset); 前處理 (Dataset map); 加載器 (Dataloader)
建議使用 Hugging Face 的 download dataset 和 datasets. 以及 Pytorch 的 dataloader.
盡量使用 Parquet 避免 CSV for big dataset. 可以用 dataset viewer preview dataset.
| Pytorch | Hugging Face | 建議使用 | |
|---|---|---|---|
| Download dataset | Torch …. | Datasets | Hugging Face |
| Preprocess dataset | Datasets map | Hugging Face | |
| Dataloader | Dataloader | Pytorch dataloader |
Hugging Face 資料集 datasets:跨格式的資料集載入
機器學習的基础在于数据。 提取有價值的见解和构建有效模型在很大程度上取決於數據集的質量和可訪問性。 Hugging Face 資料集通過提供一种方便和標準化的方法来加載和處理各种格式的數據集,从而解决了这一挑战。
為什麼数据集很重要
数据集是机器学习模型的原料。 數據的質量和多样性直接影响模型的性能和泛化能力。 以下是为什么一个健壮的數據集加载解决方案至关重要的原因:
- 效率: 手动下载、处理和格式化数据集可能既耗时又容易出错。 Hugging Face 資料集簡化了此过程,让您可以专注于模型构建。
- 可再現性: 标准化访问数据集可以确保研究人员和從业人员能够复制结果并基于现有工作进行构建。
- 社区驱动的策劃: Hugging Face Hub 托管著由机器学习社区贡献的大量数据集。 您可以在那里找到用于文本分类、图像识别、问答等任务的数据集。
介紹 Hugging Face 資料集
Hugging Face 資料集提供了一个 Python 庫,可以簡化加载、探索和准备机器学习项目所需的数据集。 以下是它的主要优点:
- 統一的界面: 有效地加载各种格式的数据集,例如文本文件(CSV、JSON、TXT)、网络档案或 Apache Arrow。
- 自動拆分: 轻松地将数据集拆分训练集、验证集和测试集,以便进行模型评估。
- 数据处理: 直接在库中使用分词、清理和特征工程功能来预处理文本数据。
- 緩存: 下载的数据集會缓存在本地,以便更快地访问和减少带宽使用量。
使用 Hugging Face 資料集
让我们通过一个简单的例子来探索如何使用 Hugging Face 資料集。 以下是加载用于情感分析的 IMDB 电影评论数据集的方法:
Python
1 | |
这段代码演示了如何:
- 使用
pip install datasets安装datasets库。 - 从库中导入
load_dataset函数。 - 使用
'train'拆分加载 IMDB 数据集。train 是 default split. - 使用索引访问单个数据点。
- 探索数据集中的可用功能。
- 可选地,进一步将数据集拆分为训练和测试部分。
Hugging Face 資料集提供了一个丰富的 API,其中包含用于预处理、过滤和自定义数据集体验的各种函数。
數據集檔案格式
1 | |
默认情况下,没有加载脚本的数据集会将所有数据加载到 train split 中。使用 data_files 参数将数据文件映射到像 train、validation 和 test splits:
如果數據集包含不同檔案 for train, validation, test, 可以用:
1 | |
分割再合併一個數據集
我們常常需要分割和合併數據集。最常見分割是 create: train, validation, test 數據集。
合併有兩種情況:(1) 把分割的 train, validation, test 的數據集合而為一,但是有不同的 label, 以便接下來的 training, testing, generation. (2) 兩個或是多個不同的數據集合併成一個。
以下是讀入一個 text file: Shakespeare.txt, 分割成兩個 train, test datasets. 接下來再合併成一個 dataset.
1 | |
合併多個不同數據集
簡單版
1 | |
複雜版
- 利用 concatenate_datasets 合併不同的數據集。但是要分開 train and test. 最後再合併一起。
1 | |
取得數據
假設只有 train split (default):
1 | |
Pytorch Dataset and DataLoader
Pytorch Dataset 的主要是搭配 DataLoader 用於 Pytorch 的 training 或是 inference.
要小心避免和 huggingface dataset 衝突。
CSV vs. Parquet
當比較 CSV 和 Parquet 格式的數據存儲和處理時,需要考慮多個因素,包括效率、性能和兼容性。以下是這兩種格式的差異、優劣勢比較:
| 項目 | CSV | Parquet |
|---|---|---|
| 存儲結構 | 基於列 (row) | 基於行 (column) |
| 文件大小和存儲效率 | 文件大,因無壓縮和冗餘架構存儲 | 文件小,因高效壓縮和行存儲 |
| 讀寫性能 | 對大數據集來說讀寫性能較慢 | 讀寫性能更快 |
| 架構和數據類型 | 無內置架構支持,需額外解析 | 支持複雜架構和數據類型,減少解析開銷 |
| 可讀性 | 可讀性強,易於手動閱讀和編輯 | Binary 不可讀,需特定工具檢查和編輯 |
| 工具和庫支持 | 被大多數工具、語言和平台廣泛支持 | 需特定庫 (PyArrow, fastparquet) 來讀寫,但在大數據生態系統中支持良好 |
| 使用場景 | 適合小到中等數據集,數據交換和人可讀性重要的場合 | 適合大規模數據處理和分析應用,尤其在大數據環境中 |
| Pandas 支持 | Yes | Yes |
| Viewers | 直接 text | Dataset viewer or Pandas |
實際定量數字比較:
| 数据集 | Amazon S3大小 | 查询时间 | 数据扫描量 | 成本 |
|---|---|---|---|---|
| CSV格式数据 | 1 TB | 236秒 | 1.15 TB | $5.75 |
| Parquet格式数据 | 130 GB | 6.78秒 | 2.51 GB | $0.01 |
| 节省 | 87% | 34倍更快 | 99% | 99.7% |
Parquet用法介绍
安装必要的库
首先,需要安装Pandas和PyArrow库。如果尚未安装,可以使用以下命令安装:
1 | |
创建和读取Parquet文件(df转Parquet)
以下是一个简单的示例,把一个Dataframe写入Parquet文件中:
1 | |
此时会生成一个名为data.parquet的文件。
1 | |
读取CSV并转换为Parquet
以下是一个简单的示例代码,演示如何将CSV文件转换为Parquet格式:
1 | |
在上述代码中,我们首先使用pd.read_csv函数读取CSV文件,然后使用df.to_parquet函数将DataFrame保存为Parquet格式文件。
将大型CSV文件转换成Parquet格式 这个脚本的工作流程如下:
- 使用 pandas.read_csv 逐块读取CSV文件,块大小由 chunksize 参数决定。
- 将每块数据转换为Apache Arrow的Table。
- 使用 ParquetWriter 将每块数据写入Parquet文件。
1 | |
注意:根据具体情况调整 chunksize 的大小,以平衡内存使用和I/O性能。