##
為什麼需要 Trans-tokenizer?
Tokenizer Conversion for Cascaded Model
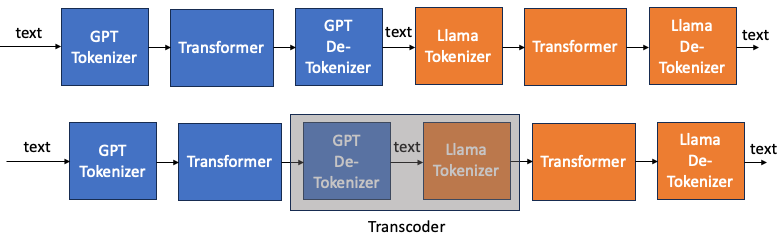
下圖一是兩個不同 tokenizer LLM model 串接。一個例子就是 speculative decode 的 draft mode 和 original model, Draft model 可能使用一個小模型使用和 original 模型不同的 tokenizer.
最直覺的方法就是把 GPT transformer 的 GPT token 先轉換成 text,再由 Llama tokenizer 轉換成 Llama tokens. 這好像是一個可行的方法,基本是兩次的 table lookup (de-tokenizer + tokenizer)。
一個問題是我們是否可以訓練一個 transcoder model, 類似翻譯。從 GPT token 轉換成 Llama token?
先不論是否划算,因為一個 transcoder 可能比兩次的 table lookup 更複雜。但也有可能更簡單。因為 table 都是很大的 table (32K or 50K 參數)。也許簡單的 transcoder (CNN, RNN, or transformer) 可以達成同樣的結果。
如何 train 這個 transcoder?
上圖 transcoder 很難訓練,因為 input token 和 output token 很難產生。如果勉強用完整的圖一,還會與 transformer 有關。是否可以有容易的 input and output tokens, 並且和 transformer 無關的方法? YES!
下圖是 transcoder 等價的方塊圖。如果要得到一個 GPT de-tokenizer to Llama tokenizer 的transcoder。 相當於訓練一個 input text to GPT tokenizer 而 output 是相同 text to Llama tokenizer 的 transcoder.
因為 text, Llama tokenizer, GPT tokenizer 都是已知。並且整個訓練和 transformer 完全無關!
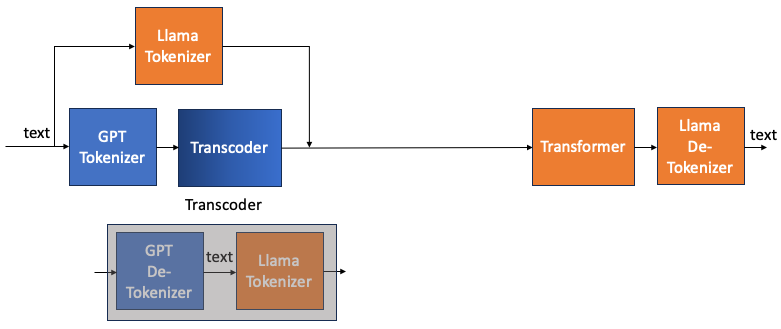
可以推廣如果要做一個 A de-tokenizer to B tokenizer 的 transcoder, 可以用 text to A tokenizer 為 input, 同樣 text to B tokenizer 為 output. 用這樣 (input, output) 對訓練 model (CNN, RNN, or transformer)
- 一個 trick 是 transcoder 的 vocab size 需要是兩個 tokenizers 的大者。以免 transcoder 會 out of range.
如何實現 Trans-tokenizer?
可以想像這就是一個翻譯的問題,就像把中文翻譯成英文。
所以要找一個 translation 而不是 generation 的 model!
HuggingFace 的 translation model 有幾個:
| T5 (Google) | Bart (Facebook) | MarianMT (Facebook) | |
|---|---|---|---|
| 架構 | Encoder-decoder | Encoder-decoder | Encoder-decoder |
| Vocab_size | 32K | 50K | 50K or 60K |
Translation 的 training 小撇步:
- 最好有 BOS (Begin-Of-Sentence), EOS (End-Of-Sentence). 空白的地方用 PAD, 在 input 和 output (label) 上?
- Output 最好 offset 一個 token?
基本問題:
- 理論上 tokenizer 都是一個 word (中文除外) 或是 sub-word, context length 可以多短? (16/32/64/128/256?)
- 中文的 token length 可能和英文的 token lengths 差異很大 (3X), 如何處理?
進階問題:
- 可以用非常簡單的模型嗎? CNN, LSTM? 還是要用到 transformer? Attention 只要很短?還是要長?
- 如何簡化 trans-tokenizer?
- 如何用於 multi-modality, 還是 token? 還是 embedding (vector space)?
如何對齊 (align) 輸入和輸出 during Training
在使用序列到序列(Seq2Seq)架构训练翻译模型时,正确对齐输入和输出序列至关重要。这种对齐确保模型学习生成准确的翻译。以下是对齐输入和输出序列的关键步骤:
- 序列 padding (need to process in input and output data):
- 在训练之前,将输入和输出序列都 pad 到相同的长度。通常使用特殊标记(例如,
<PAD>)进行填充。 - 例如,输入序列的 tokens 少于最大序列长度,则在末尾用
<PAD>token 进行填充。同样,将输出序列填充到相同的长度。 - 这一步确保了批处理中所有序列具有相同的长度,以便进行有效的批处理。
- 在训练之前,将输入和输出序列都 pad 到相同的长度。通常使用特殊标记(例如,
- Target sequence shift (need to process in output data):?? 到底是 target sequence 移除第一個 token, 還是最後一個 token (in PyTorch translation tutorial)?
- 在 Seq2Seq 模型中,在训练过程中,目标序列 (target sequence) 通常会比输入序列偏移一个 token。这是因为模型学习根据先前的 token 预测下一个 token。
- 例如,如果输入序列是 “I love deep learning”,目标序列将是 “love deep learning
" or "I love deep "?(其中 ` ` 是序列结束标记)。模型根据 "I" 预测 "love",根据 "I love" 预测 "deep",依此类推。
- **注意力机制 (in transformer model already): **
- 在 Seq2Seq 模型中实现注意力机制。注意力有助于模型在生成输出序列的每个 token 时专注于相关部分的输入序列。这提高了翻译质量,特别是对于长句子。
- 注意力机制计算注意力权重,指示每个输入 token 对生成每个输出 token 的贡献程度。
- Teacher Forcing (in model training already?): 參考 reference2
- 在训练过程中,使用 teacher forcing 来更有效地训练模型。In teacher forcing 中,下一个时间步的输入不是使用模型的预测结果,而是使用实际的目标 token。
- 这种技术有助于稳定训练,并防止推理过程中的错误传播。
- 损失计算 (use mask in training, both attention mask and pad mask):
- 为序列生成任务选择适当的损失函数,例如交叉熵损失。该损失函数基于预测概率与实际目标 tokens 之间的差异来对模型进行惩罚。
- 确保损失仅针对输出序列中的 non-pad tokens进行计算,以避免因 padding tokens 而对模型进行惩罚。
- 评估指标:
- 使用 BLEU 分数等评估指标评估模型的翻译质量。BLEU 将模型的输出与参考翻译进行比较,并提供相似性的度量。
通过遵循这些步骤,您可以有效地对齐输入和输出序列,从而提高翻译模型的性能。
Multi-input Trans-tokenizer
Merge Tokenizer
https://discuss.tensorflow.org/t/is-there-an-existing-tokenizer-model-for-chinese-to-english-translation/4520
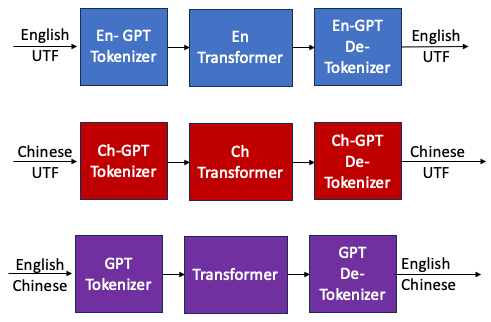
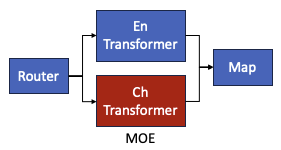
En-Tranformer 和 Ch-Transformer 可以用 MoE 解決!!!
RAG: LLM encoder and LLM generator 可以用不同的 tokenizers!
Reference
https://pytorch.org/tutorials/beginner/translation_transformer.html
https://medium.com/@magodiasanket/implementation-of-neural-machine-translation-using-python-82f8f3b3e4f1
Appendix
When training a translation model using sequence-to-sequence (Seq2Seq) architecture, it’s crucial to align the input and output sequences properly. This alignment ensures that the model learns to generate accurate translations. Here are some key steps to align input and output sequences:
- Sequence Padding:
- Before training, pad both input and output sequences to the same length. Padding is typically done with a special token (e.g.,
<PAD>). This step ensures that all sequences in a batch have the same length for efficient batch processing. - For example, if your input sequence has fewer tokens than the maximum sequence length, pad it with
<PAD>tokens at the end. Similarly, pad the output sequence to the same length.
- Before training, pad both input and output sequences to the same length. Padding is typically done with a special token (e.g.,
- Target Sequence Shift:
- In Seq2Seq models, during training, the target sequence is usually shifted by one token compared to the input sequence. This is because the model learns to predict the next token given the previous tokens.
- For example, if the input sequence is “I love deep learning”, the target sequence would be “love deep learning
" (where ` ` is the end-of-sequence token). The model predicts "love" given "I", "deep" given "I love", and so on.
- Attention Mechanism:
- Implement an attention mechanism in your Seq2Seq model. Attention helps the model focus on relevant parts of the input sequence when generating each token in the output sequence. This improves translation quality, especially for long sentences.
- The attention mechanism computes attention weights that indicate how much each input token contributes to generating each output token.
- Teacher Forcing:
- During training, use teacher forcing to train the model more effectively. In teacher forcing, instead of using the model’s predictions as inputs for the next time step, use the actual target tokens.
- This technique helps stabilize training and prevents error propagation during inference.
- Loss Calculation:
- Choose an appropriate loss function for sequence generation tasks, such as cross-entropy loss. This loss function penalizes the model based on the difference between predicted probabilities and actual target tokens.
- Ensure that the loss is calculated only for non-padding tokens in the output sequence to avoid penalizing the model for padding tokens.
- Evaluation Metrics:
- Use evaluation metrics such as BLEU score to assess the translation quality of your model. BLEU compares the model’s output with reference translations and provides a measure of similarity.
By following these steps, you can align input and output sequences effectively, leading to better performance of your translation model.