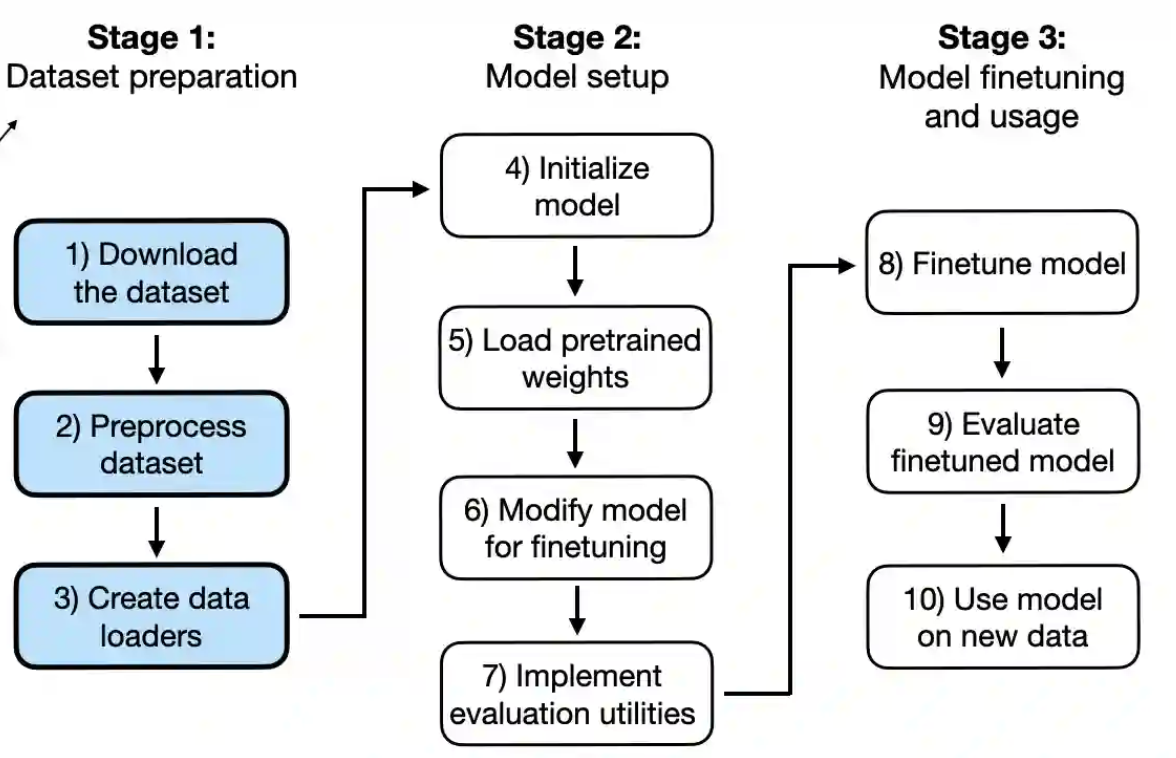
煉丹五部曲
-
應用 (起死回生,長生不老,美顔):analytic (spam, sentiment) or generative (summarization)
-
靈材:datasets, tokenizer, embedding
-
丹方:model
-
丹爐:Nvidia GPU (和財力有關)
- 煉製:training: data_loader, loss function, optimizer
- Fine-tune pre-trained model
- 評估:evaluation: accuracy, BLEU
我們很簡單比較傳統 analytic NLP (自然語言處理) 和 generative LLM (大語言模型) 的差異。
傳統 NLP 例如文本分類 (spam, sentiment, etc.):
- 單詞 tokenizer + (pre-trained embedding fixed layer?+ 簡單網路) + downstream tasks. 使用 supervised learning.
大語言模型 LLM 例如 text summarization, chatbot
- BPE tokenizer + LLM (one-hot fixed vocab + trainable embedding layer? + positional encoding + transformer layers). 使用 self-supervised learning. 最後再 fine-tune 到 downstream tasks!
| NLP | LLM | |
|---|---|---|
| 應用 | Analytic (SPAM/sentiment classification) | Generative (summarization, chatbot, coding) |
| 靈材 | ||
| Datasets | MB, GB with or without labels | TB without labels |
| Tokenizer, 分詞 | word tokenizer, 如 torchtext/get_tokenizer | BPE, 如 HuggingFace tokenizer (Others), tiktoken (OpenAI) |
| Embedding | Pre-trained fixed 詞嵌入: 例如 Word2Vec, GloVe | 屬於 LLM 的第一層, one-hot fixed vocab + trainable embedding layer?? |
| 丹方 | MLP (FC), RNN, transformer encoder | Transformer decoder |
| 煉製 | ||
| 方法 | Supervised learning for downstream | SSL pre-trained + fine-tune for downstream |
| Dataloader | pytorch Dataloader | Pytorch Dataloader |
| Loss function | Cross-entropy | Cross-entropy |
| Optimizer | Adam? | Adam? |
| 評估 | ||
| 基本盤 | loss | loss |
| 幾率分佈 base | accuracy (in probability distribution), 例如這封 email 有 90% 是 SPAM | perplexity, BLEU (translation) |
| Ground truth base | accuracy (SPAM, sentiment, …) | World knowledge, common sense (選擇題) |
| Quality base | X | 使用 ChatGPT score: summarization, chatbot, etc. |
Q: what’s the embedding layer difference between the large language model vs. traditional NLP tasks?
大型语言模型(如GPT(生成式预训练变换器)模型)和传统NLP任务中的嵌入层可以在以下几个方面有所不同:
- 大小和复杂性:
- 大型语言模型的嵌入层通常比传统NLP模型的要大得多。例如,在GPT-3中,有1024维嵌入。
- 传统NLP任务可能使用较小的嵌入维度,如100、200或300维,取决于任务的复杂性和词汇量的大小。
- 上下文嵌入:
- 大型语言模型(如GPT)使用上下文嵌入,其中词的嵌入不仅取决于词本身,还取决于周围的上下文。这是通过使用具有自注意力机制的变换器架构等技术实现的。
- 传统NLP任务通常使用静态词嵌入,如Word2Vec、GloVe或fastText,这些方法为每个词分配固定的向量表示,而不考虑上下文。
- 预训练与任务特定:
- 大型语言模型通常使用无监督学习目标(如语言建模或遮蔽语言建模)在大量文本数据上进行预训练。预训练期间学到的嵌入捕获了来自训练语料库的丰富语义和句法信息。
- 在传统NLP任务中,嵌入可以从零开始在特定任务的数据集上进行训练,或者从预训练的嵌入中进行微调。嵌入被定制为特定任务和数据集。
- 微调:
- 大型语言模型通常在下游任务上进行微调,方法是在预训练模型的顶部添加特定任务的层。这个微调过程调整了嵌入和其他模型参数,以提高目标任务的性能。
- 传统NLP模型也可以进行微调,但这个过程通常更直接,可能涉及微调整个模型或仅特定层,根据任务要求。
- 用途:
- 大型语言模型的嵌入用于广泛的自然语言理解(NLU)和生成任务,包括文本完成、问答、摘要等。
- 传统NLP嵌入常用于情感分析、命名实体识别(NER)、词性标注(POS)、机器翻译和文档分类等任务。
总体而言,在大型语言模型中,嵌入层在捕获复杂的语言模式和语义方面起着关键作用,使得模型能够在各种NLP任务中有效地执行,而无需进行重大的任务特定修改。相比之下,传统NLP任务通常需要更专门和任务特定的嵌入表示和学习方法。
下圖