Source
- 彻底搞明白 GB2312、GBK 和 GB18030 - 知乎 (zhihu.com)
- 線上文字亂碼還原工具 - ToolsKK 線上工具網
- 寫代碼總是莫名其妙的亂碼?這一篇教你從原理出發徹底幹掉它 - 每日頭條 (kknews.cc)
- 三類亂碼原因分析 - 每日頭條 (kknews.cc)
- 有亂碼?口算修復下 - 每日頭條 (kknews.cc)
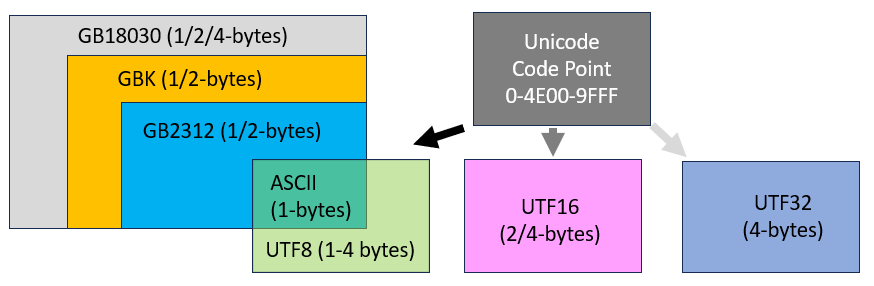
GB18030 与 Unicode
GB18030 和 Unicode 相当于两套单独的编码体系,它们都对世界上大部分字符进行编码,赋予每个字符一个唯一的编号,只不过对于同一个字符,GB18030 和 Unicode 对应的编号是不一样的, 比如:汉字 “中” 字的 GB18030 编码是 0xD6D0, 对应的 Unicode 码元是 0x4E2D, 从这一点上可以认为 GB18030 是一种 Unicode 的转换格式
注意:要表达 Unicode 的编码格式才真正算得上 Unicode 转换格式,所以严格意义上说 GB18030 并不是真正的 Unicode 转换格式
GB18030 既是字符集又是编码格式,也即字符在字符集中的编号以及存储是进行编码用的编号是完全相同的,而 Unicode 仅仅是字符集,它只规定了字符的唯一编号,它的存储是用其他的编码格式的,比如 UTF8、UTF16 等等
既然 GB18030 和 Unicode 都能表示世界上大部分字符,为什么要弄两套字符集呢,一套的话不更有利于信息的传播吗?
1、在 Unicode 出现之前,没有统一的字符编码,每个操作系统上都有自己的一套编码标准,像早期的 window 上需要安装字符集,才能支持中文,这里的字符集就是微软自定的标准,换个其他系统就会失效
2、对于大部分中文字符来说,采用 GB18030 编码的话,只需两个字节,如果采用 UTF8 编码,就需要三个字节, 所以用 GB18030 存储和传输更节省空间

雖然有如上的分區原則,但因編碼時的碼位及區塊的整體考慮,使得BMP現況 與上述分區有所差異。典型的例子如1998年剛擴編完成的「中日韓認同表意文字擴充A」字集6,582字,因為I區僅餘零星位置,因此就編入A區3400~4DFF的位置,而該區原為韓文拼音(Hangul)符號,但因後來韓文拼音移置O區,空出的碼位就給了「中日韓認同表意文字擴充A」,造成實際編碼與理論分區有別的現象。 在I區的中日韓漢字部份,最當初進行編碼時,因各國漢字型體不盡相同,必須先進行認同(unify)整理工作,SC2/WG2因此邀集有關各國指派專家組成CJK/JRG(中日韓聯合研究工作組,即IRG前身),進行字集的總整理。CJK/JRG歷經五次會議完成此項艱鉅工作,所整理的「中日韓認同表意文字」(CJK Unified Ideographs)參考了我國75年版CNS 11643之第1、2、14字面(T欄),大陸的GB 2312、GB 12345、GB 7589、GB 17590、GB 8565(G欄),日本的JIS X 0208、JIS X 0212(J欄)及南韓的KS C 5601、KSC 5667(K欄)等標準字符集,可說已包含這四地所常用的字。其字序主要是參考康熙字典、大漢和詞典、漢語大詞典及大字源字典,以先部首後筆劃的順序排列。CJK/JRG將此結果送交SC2/WG2編碼,完成了ISO 10646:1993 之BMP中I區的表意文字編碼標準,總計含20,902個漢字。其中包含了CNS 11643用字共有17,011個字。
亂碼如何產生的呢?
亂碼產生的原因主要有兩個,1. 文本字符編碼過程與解碼過程使用了不同的編碼方式,2. 使用了缺少某種字體庫的字符集引起的亂碼。
1. 編碼與解碼使用了不同的編碼方式
亂碼就是 encode 和 decode 采用不同的編碼和解碼格式,包含:
- UTF encode/decode 的不一致: 例如 UTF8, UTF16, UTF32 的不一致
- GBK, BIG5, UTF 之間 encode/decode 的不一致
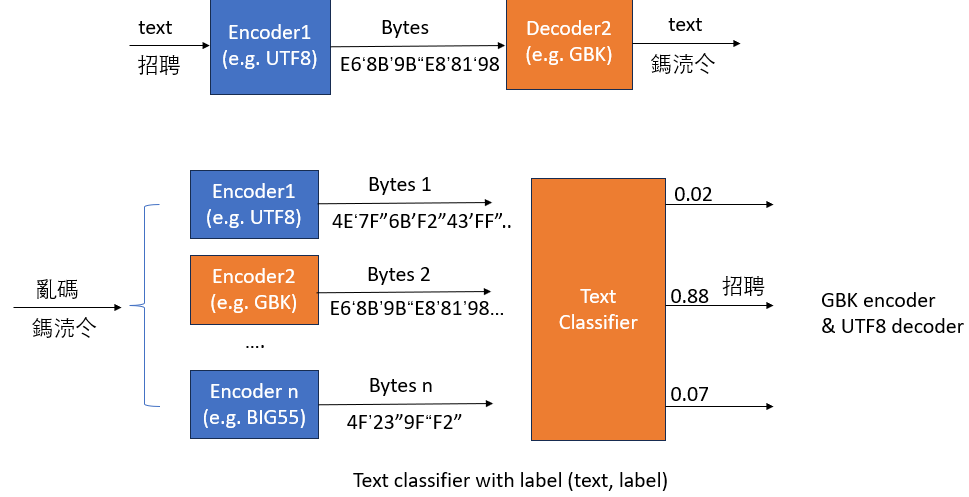
GBK——>UTF-8:”鎷涜仒”
這三字一看就是亂碼,我們使用GBK編碼與UTF-8解碼來修復。
GBK編碼映射結果為:
| 鎷 | E68B |
|---|---|
| 涜 | 9BE8 |
| 仒 | 8198 |
是按照:E68B 9BE8 8198 四個一組來做拆分
通過上面介紹可知,中文字符在UTF-8中是通過三字節進行編碼的,我們將三個字的GBK編碼按照每三字節為一組重組可得:
E68B9B
E88198
這兩個字符代表什麼呢?查詢UTF-8編碼表:

1 | |
例子中,用了utf-8編碼,使用了GBK解碼,結果產生了亂碼。因為在utf-8中,一個漢字用三個字節編碼,而GBK中,每個漢字用兩個字節表示,所以產生了亂碼。
2. 使用了缺少某種字體庫的字符集
我們知道GB2312是不支持繁體字的,所以使用缺少某種字體庫的字符集編碼,會產生亂碼。
3. 软件缺陷或设定不当
一些软件或系统在处理特殊或复杂文本时出错,可能是由于软件本身的编码处理模块存在缺陷。例如,某些文本编辑器可能无法正确处理跨越多个字节的字符编码。用户设定错误或更换语言设置可能导致系统采用了错误的默认编码方式,这种情况下也会引发乱码问题。
亂碼如何解決呢
使用支持要展示字體的字符集編碼,並且編解碼使用同一種編碼方式,就可以解決亂碼問題了。
接下來列舉一下亂碼的經典場景與解決方案
IntelliJ Idea亂碼問題
IDE項目中的中文亂碼問題?File->settings->Editor->File Encodings,設置一下編碼方式utf-8
- 确认并统一编码标准 保证信息发送和接收双方使用相同的编码标准是避免乱码最直接的方法。一般建议使用广泛兼容的Unicode编码,如UTF-8,这样即便是在多语言环境中也很少会出现乱码问题。
- 使用兼容的字体 确保使用的字体支持您需要显示的字符集。对于显示罕见字符或特殊文字系统,可能需要安装额外的字体包。
- 软件和系统更新 不断更新软件和系统,以确保编码处理的兼容性和正确性。软件开发者应保证软件更新包含对新的编码方式的支持。
- 文件转码工具 对于已经出现乱码的文本,可以使用文件转码工具来尝试恢复到正确的编码。例如,Notepad++等编辑器提供了转换编码的功能。
- 高级文本编辑器使用 使用高级文本编辑器处理文本文件,这些编辑器通常有检测和转换编码的功能,能自动识别和提供修复乱码的方案。
检测和转换编码的方法
- 编码检测工具 编码检测工具如chardet(Python库)可以自动分析文本文件的编码。这个库通过检查文本中字符的频率及其在不同编码系统中的分布情况,采用统计分析的方法来推测文本的编码。
- 编码转换工具 一旦正确识别出编码,就可以使用编码转换工具如iconv(通用命令行程序)或程序库(如Java中的Charset类)来转换文本文件的编码。这些工具和库提供了从一种编码到另一种编码的转换功能,用户只需要指定源编码和目标编码即可。
- 编写转换脚本 如果现成的工具不能满足需求,可以编写转换脚本来处理文本。例如,可以使用Python编写脚本,利用其强大的编码支持与字符串处理功能,来实现复杂的编码检测和转换任务。
- 编码标准化 为了避免乱码,推荐使用统一的编码标准,如UTF-8。UTF-8是Unicode的一种实现方式,它兼容ASCII,且能够表示全世界所有的字符,是目前Web和多数操作系统中推荐使用的编码。在数据的存储和传输中使用UTF-8,可以大大减少乱码问题的发生。
1 | |
1 | |
實例
1. 英文字母
1 | |
-
‘\xff\xfe’ is the BOM (Byte-Order-Mark) for UTF-16 Little Endian, indicating the byte order.
-
‘a\x00’ could represent the character ‘a’ followed by a null byte, but it’s important to note that UTF-16 encodes characters in two bytes (unless it’s a supplementary character).
-
‘\xff\xfe\x00\x00’ is the Byte Order Mark (BOM) for UTF-32 Little Endian, indicating the byte order.
-
‘a\x00\x00\x00’ represents the character ‘a’ followed by three null bytes, as UTF-32 uses 4 bytes per character.
2. 繁體中文
1 | |
3. 簡體中文
1 | |
1 | |
Neural Network Coding Conversion
Constraint Neural Network!
因爲 < 7F output code 就是 input code!!!!
可是所有其他的 code 都需要計算!
兩種做法
| Encoder | Decoder | Coment | |
|---|---|---|---|
| GBK | UTF8 | ||
| UTF8 | GBK | ||
| UTF8 | UTF16 | ||
| BIG5 | GBK | ||
| GBK | BIG5 |
Text classification
基本是判斷什麽 encoder + decoder!
利用 BERT 類似的 transformer network! 比較其他的方法: RNN, …
BERT 有 [CLS] text [SEP] 的方法。
Trans-coder
N x N 方法
Appendix
###