Source
Excellent YouTube video!!! https://www.youtube.com/watch?v=zc5NTeJbk-k
【生成式AI導論 2024】第18講:有關影像的生成式AI (下) — 快速導讀經典影像生成方法 (VAE, Flow, Diffusion, GAN) 以及與生成的影片互動 (youtube.com) 李宏毅:加上 VAE, Flow, and GAN
https://alu2019.home.blog/2021/05/07/math-ai-variational-autoencoder-vae-bian-fen-zi-b/: VAE
2406.07524 (arxiv.org) Simple andEffective MaskedDiffusionLanguageModels
結合自回歸和擴散模型的統一框架於生成式人工智能應用 摘要:
預測 is the key!!!
引言
- Diffusion 的 noise 并非是 noise, 而應該視爲特徵向量 (embedding). Transformer 的目的在於 attention 出相關的特徵!
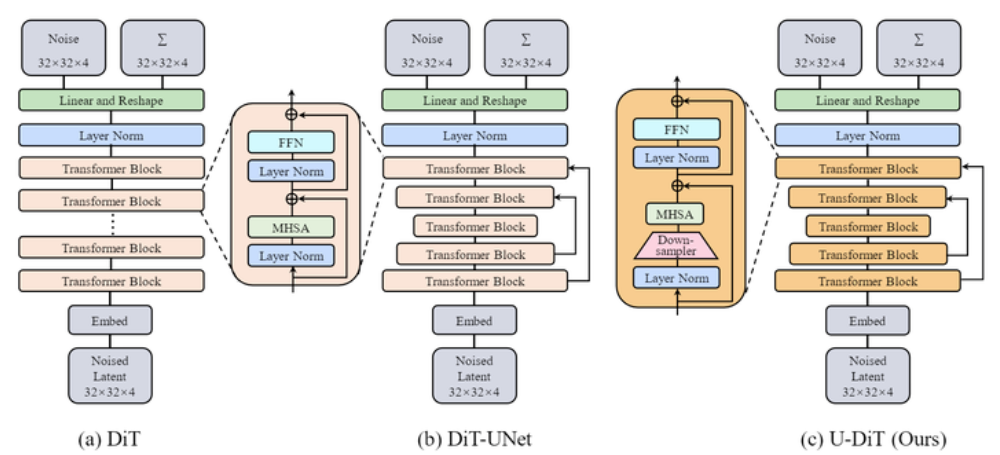
Diffusion UNet base.
- Unet 每一層都有 CNN,Resnet, 還有 long link. Up/Down 基本就是 stride = 2.
- Prompt 是 cross-attention. 即使沒有 prompt, 還是有 self-attention (?).
DiT
- 沒有中間的 Resnet,沒有 long link,沒有 up/down sampling.

-
其實 Diffusion 的 denoise 過程 可以視爲是一種 AR!
- Diffusion 中的 attention 是 parallel attention (就是 prompt mode) , 不是 auto-regression.
- Generative 的部分是 denoise, 也可以視爲是一種 AR。
- Unet diffusion 和 DiT 的差別是 Unet 每一層都有 CNN, 還有 long link. 但是 DiT 只有一開始有 CNN, 再來都是 attention. 沒有 long link.
AR vs. Diffusion
VAE, Flow-Based, Diffusion, GAN
VAE (Maxwelling!)
VAE training and inference

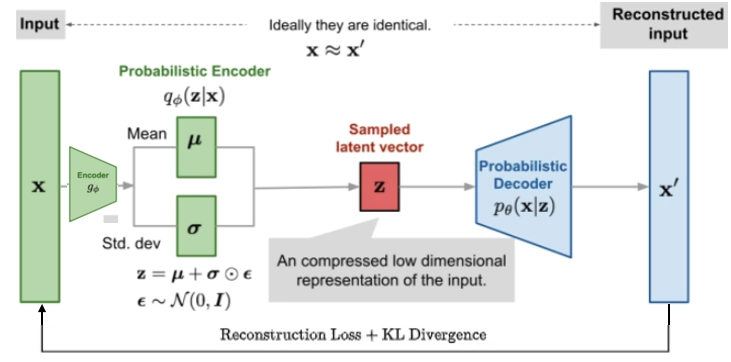
VAE 的思路如下圖

- Noise 名稱非常不恰當!其實是 latent space 所包含特徵資訊!應該稱爲 feature noise. 如果結合 attention, 可以從 text 產生對應的 image. 這是 diffusion 的雛形。但是 image quality 不好!
如何訓練 VAE? 這是最神奇的地方!
- 簡單說就是加 noise (latent loss) $\epsilon$, 然後 denoise (minimize reconstruction loss) 過程。見下圖. 請參考 reference for math.
- Diffusion 就是把這個過程重複幾十次!
- Flow-based 就是把 Encoder 變成 Decoder 的反函數 (invertible)
Inference
Vanilla VAE 非常簡單,就是 random feature 產生新的 sample.
Conditional VAE, 就是用 text attend some noise (假如用 transformer) 產生新的 sample. 用 Conditional VAE 作爲 Diffusion 的第一步!
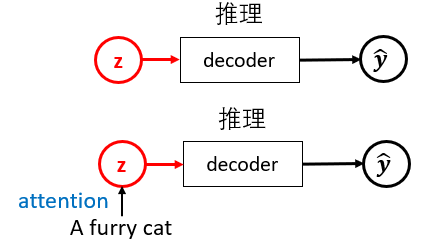
Condition 可以是 text: a furry cat. 或是前一幀圖像!
Latent Action VAE (Genie)
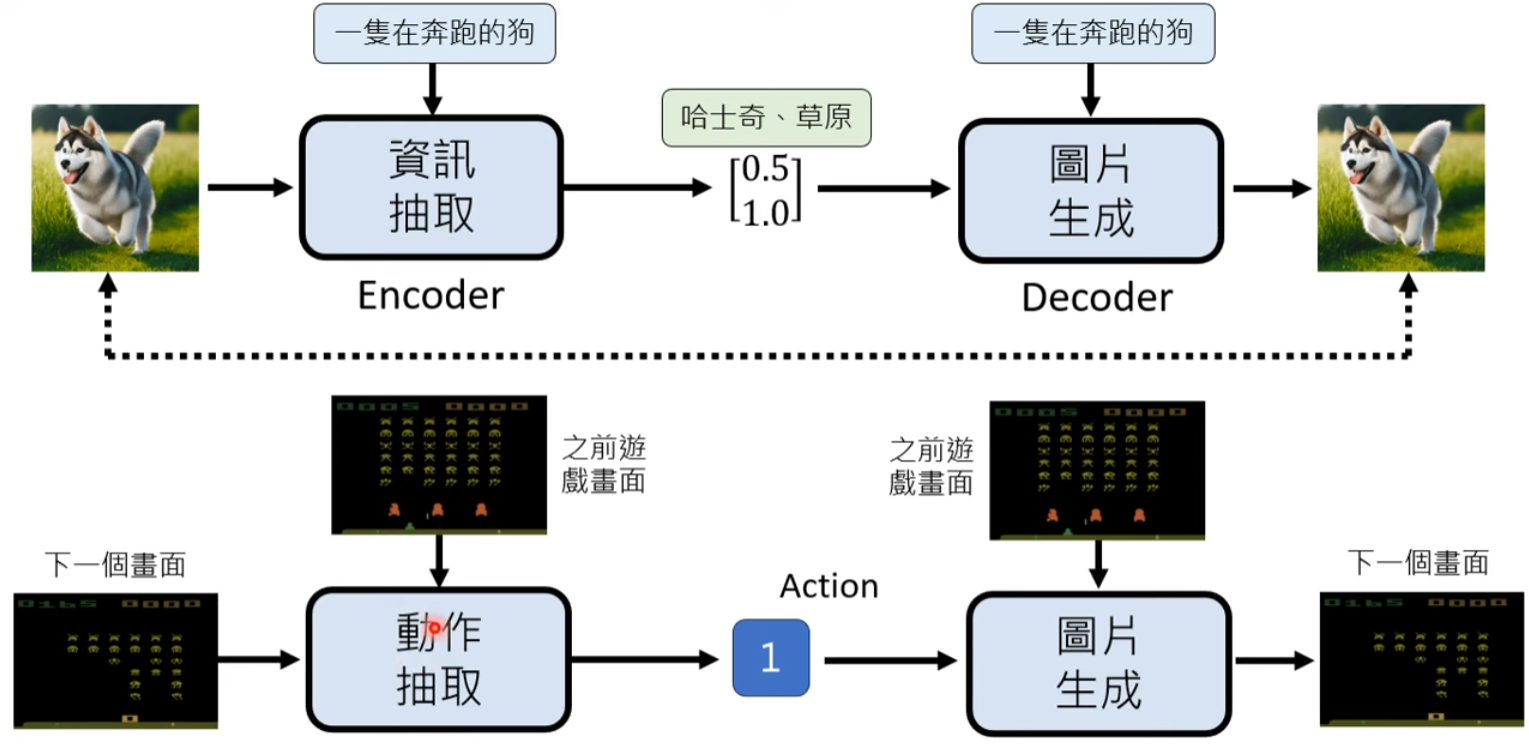
VAE 的兩個分支: A. From VAE to Flow-based
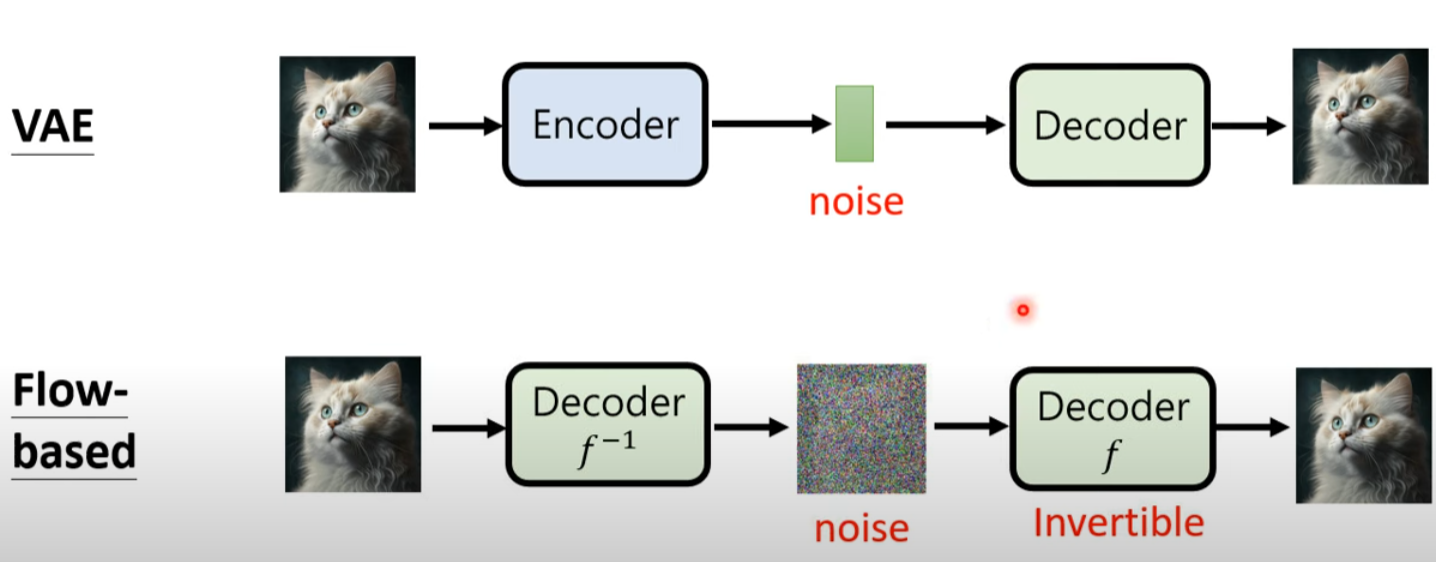
- Flow 只有一個 decoder, 但是 invertible!
- Q: 如何訓練 Invertible decoder? 可否用於 transtokenizer?
B. From VAE to Diffusion
- 同樣的:Diffusion 的 noise 并非是 noise, 而是特徵向量 (embedding). Transformer 的目的在於 attention 出相關的特徵!
- Diffusion 可以視爲多次 VAE!
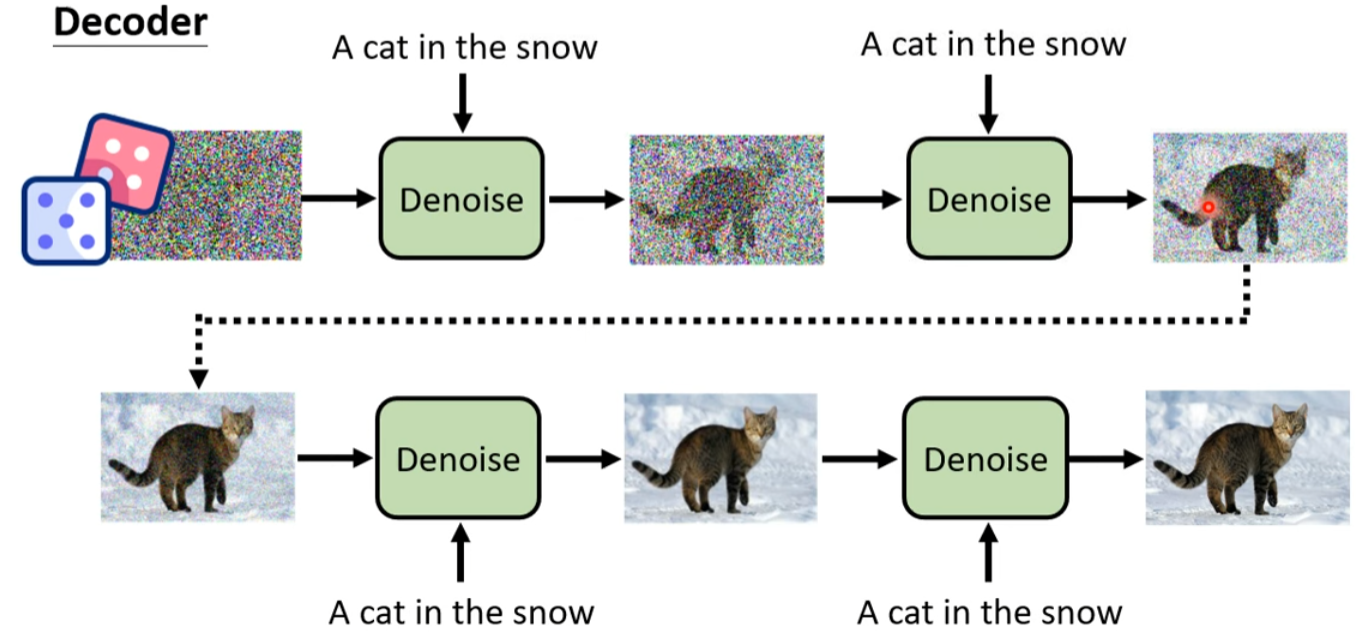
C. From VAE to Action VAE
| Diffusion | Auto-Regression | Mask | |
|---|---|---|---|
| Image | Stable Diffusion | ||
| Language | GPT | ||
| Language | MDLM | ||
| Image | Sequencing frequency coef. | ||
| Image | Li Hong-Yi example (低效率) | ||
| Language | BERT, encoder |
把 Diffusion 用於 Language Model
Simple and Effective Masked Diffusion Language Models (MDLM)
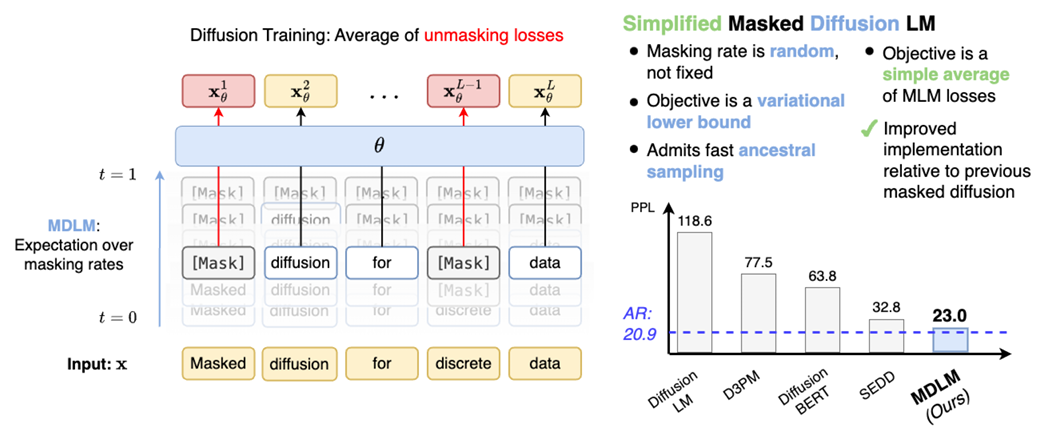
我們先看 VAE, 也就是 diffusion formula:

問題是如何把 continuous 的 q 變成 discrete for language model.

Foward path
使用 maks process.
Reverse path
當然是 unmask process.
Bound
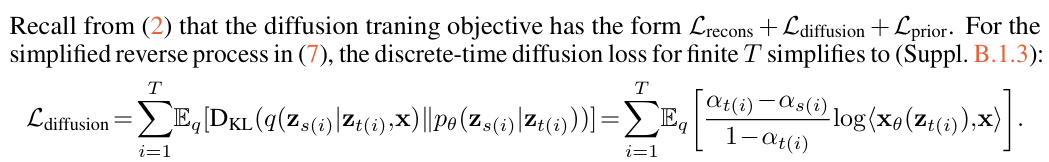
Question
-
如何做 generative or generation? 和 BERT 的差別?
BERT 是固定 mask? 只有 encoder.
本論文提出了一種基於隨機遮蔽率訓練 BERT 模型使其生成文本的方法,從而為 BERT 模型赋予生成文本的能力。先前的一些研究使用 Gibbs 採樣或其他非正式方法從 BERT 模型生成文本。