Source
SORA: https://www.youtube.com/watch?v=dDUyK0_KC7w&ab_channel=ZOMI%E9%85%B1
JEPA: https://www.youtube.com/watch?v=kGu6AnNPuJE&ab_channel=ZOMI%E9%85%B1
【生成式AI導論 2024】第18講:有關影像的生成式AI (下) — 快速導讀經典影像生成方法 (VAE, Flow, Diffusion, GAN) 以及與生成的影片互動 (youtube.com) 李宏毅:加上 VAE, Flow, and GAN
Takeaways
SORA: (b) + Auto-regression. x, y 都是 pixel/voxel domain.
Genie: (b) + Auto-regression. 除了 video pixel/voxel, 多了一套 action hidden space.
- 生成式有 decoder, 而且使用 Auto-regression, 因此有 hallucination.
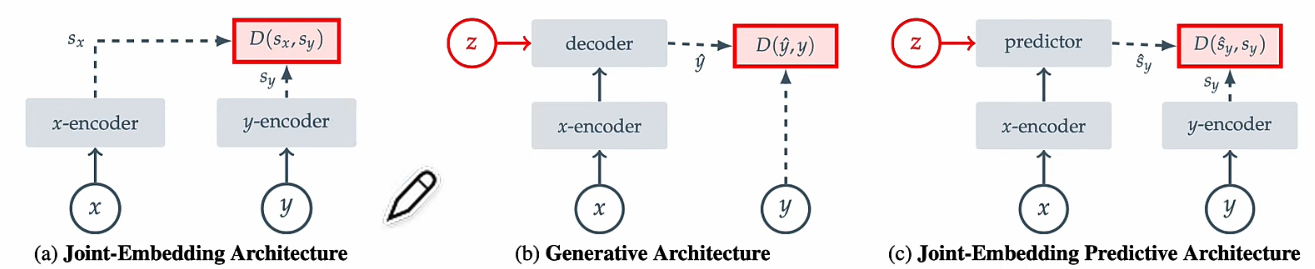
JEPA: 從 (a) 演進到 (c) I-JEPA. (a) 完全沒有生成或預測能力。 (c) 加上了預測能力。
- Predictor 不就是 decoder? NO 使用 RL-agent!
- 但是如何從 state 轉換成 video?
-
Sora 是直接原始的 decoder + AR。只有 video latent space, 强調生成下一幀 video. PQ 效果好。
-
Genie 分開 video and action. Video and action 有各自的 latent space (use LLM). 强調互動。
-
JEPA 的核心指導思想就是沒有生成 (only encoder, no decoder),只有預測。所以在世界模型的定位就顯得的不清不楚
-
JEPA 和 Genie 有部分相似:
- Video 一樣用 transformer encode 到 latent space.
- 把 action 部分分開
但 Yan LeCunn 不喜歡 AR, 也不談生成。 JEPA 沒有討論 video 如何從 latent space 生成,因爲需要 AR decoder. 也不用 LAM for action :) 主要應用應該是視頻分析或世界理解。
差異部分:
- Action 部分用 RL agent with state 而不是像 Genie 用 LAM.
- 强調預測下個 latent state,而不是預測幀 in pixel/voxel domain.
結論
- 一定要在 latent space 處理 video 或是 action,pixel/voxel domain 處理都太花資源!
- Video 和 action 最好要分開。一個是 output (video), 一個是 input (action). text 是另一個 input.
- 少點意識形態,多點產品思維!
| Sora (OpenAI) | Genie (Google) | JEPA (Meta) | |
|---|---|---|---|
| 應用 | 文生視頻 | (圖 + action) 生視頻,Game | 視頻分析、世界理解 |
| 技術 | decoder + AR for video | decoders + ARs for video and action | RL state prediction using encoder |
| Video Latent | Space/Time-transformer | Space/Time-transformer | Space/time transformer? |
| Action Latent | No | LAM, another ST-transformer | RL-agent, state |
| 預測 | 下一個 pixel/voxel/frame | 下一個 pixel/voxel/frame | 下一個 latent state, how? |
| Pro | 質量高,大力出奇跡 | 互動 | 可以嵌入物理定律? |
| Con | AR 無法學會物理定律 or video hallucination 無互動 |
Video hallunication 目前質量低,應可以大力出奇跡 |
沒說如何從 state 生成視頻 沒有生成式應用 |
引言
世界模型或模擬大戰。

Sora (Autogression, OpenAI, 文生成視頻)
文生視頻,宣傳成 World simulator, how? 强調視頻生成。
Sora 訓練如下。推理只需要下面一路。
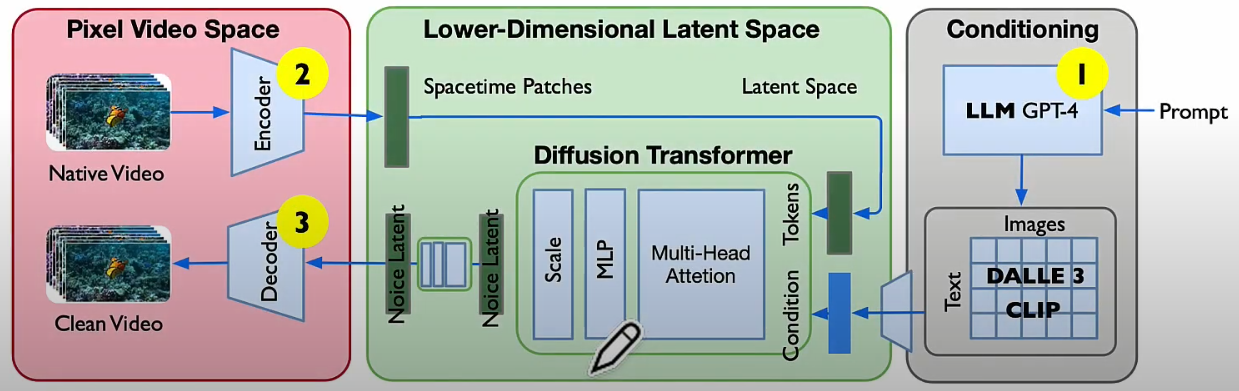
Pros:
- 生成視頻質量很好。看來真實。
Cons:
- 因爲文生視頻。需要 label data.
- 生成視頻可能不符合物理定律 (video hullucination!)
- 理解 prompt, 沒有和真實世界互動!
Genie (11B, Video LLM + LAM -> 生成式交互, Google. 圖生成視頻)
圖像生視頻。强調視頻互動。可以用於 game generation! 還有 ADAS!
在 training, 可以 extract 出 action (就是 driver behavior),和 CAN bus ground true information 可以比對。
在 inference, 基於 video, 就可以自動駕駛!!
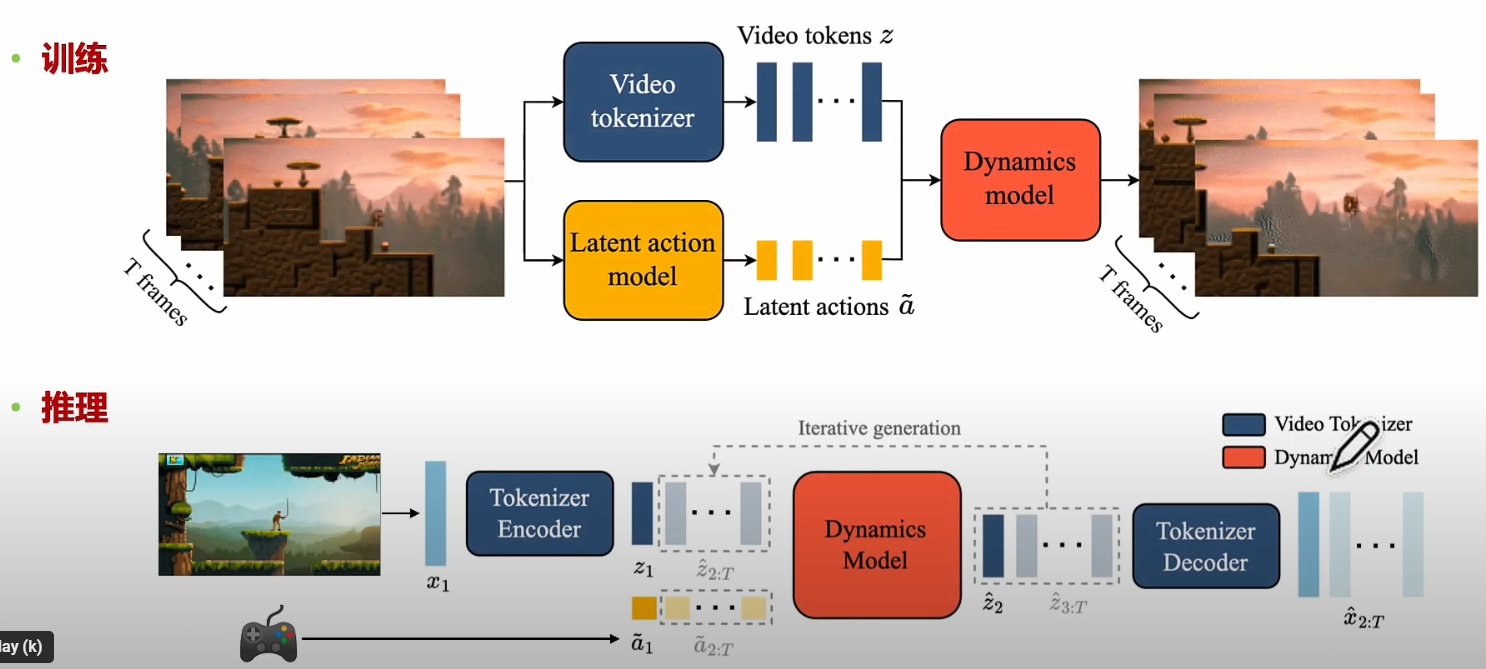
-
Dynamic model, LAM, 都是 ST-Transformer.
-
LAM training:
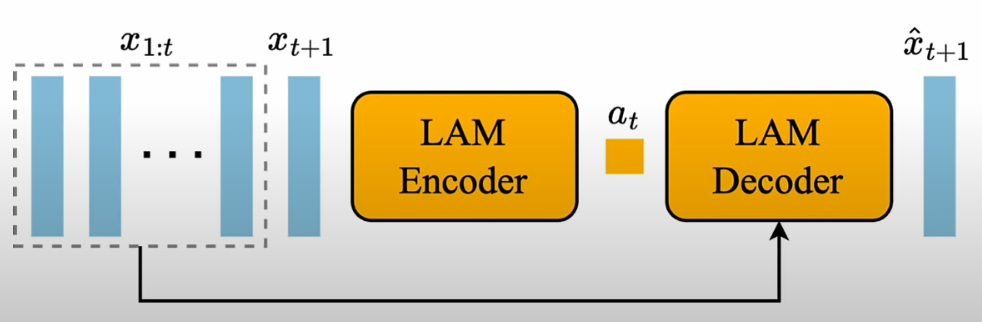
Pros:
- 雖然不是文生視頻,但是 action 生成視頻。使用 self-supervised learning from video.
- 有交互
Cons
- Lower quality
- 很多 events 並沒有互動, 這是世界模型的展開方式嗎? 應該沒有影響。沒有 action input 也 ok.
另外參考李宏毅的 youtube
JEPA ( 聯合嵌入預測架構, RL, Meta. 視頻分析)
https://www.youtube.com/watch?v=kGu6AnNPuJE&ab_channel=ZOMI%E9%85%B1
Yan LeCunn 不喜歡 AR, 也不談生成。JEPA 的核心指導思想就是沒有 auto-regression, 也不談生成。所以在世界模型的定位就顯得的不清不楚
-
JEPA 似乎和 Genie 有部分相似:
- Video 一樣用 transformer encode 到 latent space.
- 把 action 部分分開
但 ** JEPA 沒有討論 video 如何從 latent space 生成,因爲需要 AR decoder. 也不用 LAM for action :)** 主要應用應該是視頻分析或世界理解。
差異部分:
- Action 部分用 RL agent with state 而不是像 Genie 用 LAM.
- 强調預測下個 latent state,而不是預測幀 in pixel/voxel domain.
JEPA 是從人腦得到靈感。預測下一個 latent space state!
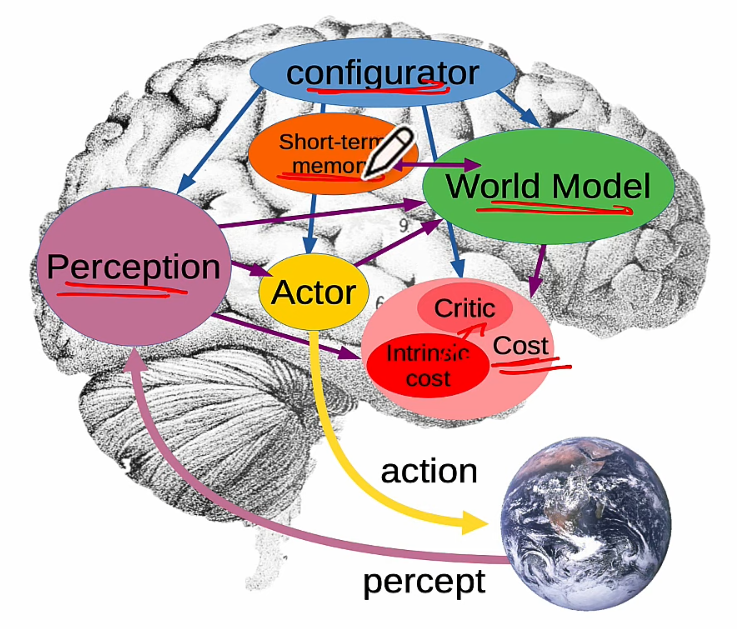
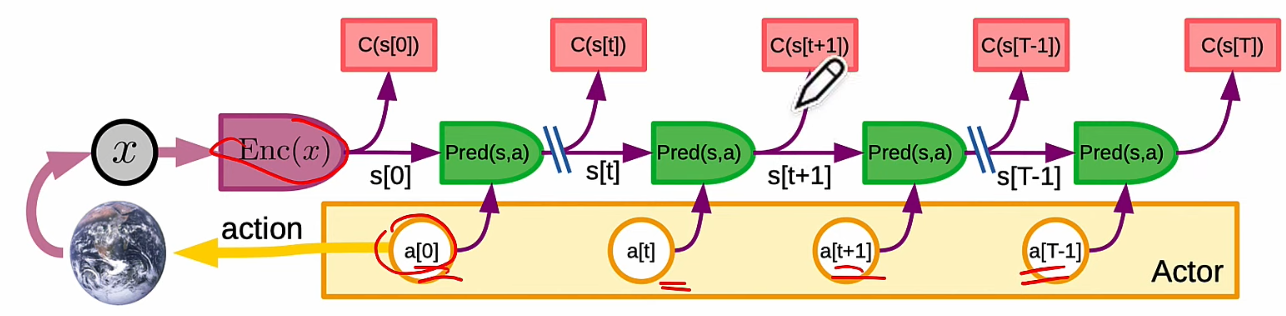
- JEPA 雖然使用 self-supervised learning, 但不是生成式。如下圖。生成式 self-supervised learning 是比 x and y. JEPA 是比較 latent 部分。
- JEPA 的 action 使用 RL-agent, 不是另一個 LLM (LAM).
强調預測,但不是視頻預測,而是 latent space 預測
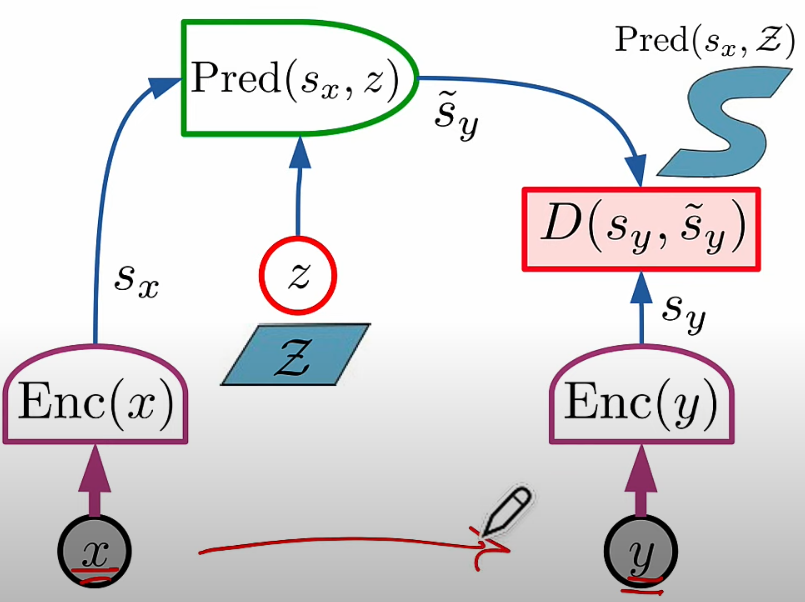
JEPA 和生成式比較
- 生成式有 decoder, 而且使用 Auto-regression, 因此有 hallucination.
- Predictor 不就是 decoder? NO 使用 RL-agent!
Pros:
- 有交互 (actor),只是用 RL agent 而不是 LAM. 在 RL agent 的 state 可以嵌入物理定律?
- 因爲沒有生成,也沒有 hallunication :)
Cons
- 沒有生成式應用。沒説如何生成視頻。