Reference
文本表示方法(BOW、N-gram、word2vec)_全文本表示方法-CSDN博客
一步步理解bert_从one-hot, word embedding到transformer,一步步教你理解bert-CSDN博客
| [Beyond Word Embeddings Part 1. This series will review the pros and… | by Aaron (Ari) Bornstein | Towards Data Science](https://towardsdatascience.com/beyond-word-embeddings-part-1-an-overview-of-neural-nlp-milestones-82b97a47977f) |
| [Beyond Word Embeddings Part 2. A primer in the neural nlp model… | by Aaron (Ari) Bornstein | Towards Data Science](https://towardsdatascience.com/beyond-word-embeddings-part-2-word-vectors-nlp-modeling-from-bow-to-bert-4ebd4711d0ec) |
2406.07550 (arxiv.org) An Image is Worth 32 Tokens for Reconstruction and Generation
引言
先結論一下。
| Token (詞元), 斷句 | Tokenizer (詞元化) | Embedding (嵌入),向量補捉 Token 關係 | Scale | |
|---|---|---|---|---|
| Text (英文) | subwords,大多是 1 個單字 (unicode:1-byte) |
Scalar index of vocab (30-250K), 16-18bit for index | 1024 dimension, 8-bit 1024*8bit = 8192 bit |
x1024 |
| Text (中文) | 多個字,大多是 1-3 字 (unicode: 3-byte) |
同上 | 同上 | x170 |
| Image (圖像) | 16x16 patch, 1024x1024 包含 32x32=1024 tokens 16x16x3x8bit = 6144 bit/token |
– | 同上 | x1.3 |
| Voice | 4 token/sec, 8K sample@8it 0.25sec voice/token 2K sample x 8bit = 16000 bit |
– | 同上 | x0.5 |
Paper: An Image is Worth 32 Tokens for Reconstruction and Generation: 256 ×256×3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods.
Token (詞元, 符元, 令牌, 令符) 和 Embedding (嵌入)
Token 和 Embedding 的相同和相異
在自然語言處理(NLP)中,Token(詞元)和Embedding(嵌入)是一體兩面,它們在處理文本數據時扮演著不同但互補的角色。
Token 是將文本數據分割成更小的單位,如詞、子詞或字符的過程。這些更小的單位被稱為詞元(tokens)。例如,句子 “I love NLP” 可以被分割成三個詞元:”I”、”love” 和 “NLP”。詞元化 (Tokenization) 的目的是將非結構化的文本數據轉化為結構化的數據,這樣可以方便後續的處理和分析。 Token 一般是用 vocab 的 index 表示,也就是一個正整數。Vocab 的 size 從 30K (Llama2) 到 250K (Llama3).
嵌入則是將詞元轉化為數值向量的過程。這些數值向量在高維空間中表示詞元的語義。嵌入的目的是捕捉詞元之間的語義關係,使得機器能夠理解和處理自然語言。例如,詞 “king” 和 “queen” 的嵌入向量應該在高維空間中距離較近,因為它們在語義上相關。
兩者的區別在於,詞元 (token) 是原始的文本單位,而嵌入是對這些文本單位的向量數值表示。詞元化是文本預處理的步驟之一,而嵌入是將詞元轉換為可被機器學習模型處理的數值形式的步驟。
Token 和 Embedding 在自然語言處理中的重要性
在自然語言處理中,詞元和嵌入都是不可或缺的。詞元化使得文本數據可以被結構化和標準化,這是文本分析和處理的第一步。而嵌入則使得文本數據可以被轉換為機器學習模型可以處理的形式並且補捉詞元之間的語義關係,這是理解和生成自然語言的關鍵。
嵌入的發展歷程
在自然語言處理(NLP)中,嵌入技術隨著時間不斷演進,逐漸提高了文本表示的質量和效率。以下是嵌入技術的發展歷程:
1. One-hot Encoding
最早的嵌入方法是One-hot編碼。每個詞都被表示為一個向量,其中只有對應於該詞的那一維是1,其餘維度都是0。這種方法簡單易懂,但存在高維度、稀疏性和無法捕捉語義關係的問題。
One-hot embedding 目前大多用於 model 的第一層。不過一般只是用於 index, 就是一本字典的 index. 並不會真的用矩陣乘法。
2. Bag of Words (BoW, 區分字的重要性)
Bag of Words模型是一種基於詞頻的表示方法。它忽略了詞的順序,僅僅計算每個詞在文檔中出現的次數。雖然解決了一部分One-hot編碼的問題,但BoW仍然無法捕捉語義和上下文信息。
一般我們會設定一個閾值 (threshold) , 低於閾值一般就不處理。對於分析式 AI 例如分類還可以。但對於生成式 AI 就不適合。
3. TF-IDF
TF-IDF(詞頻-逆文檔頻率)是對BoW的改進,它考慮了詞在文檔中的頻率以及詞在整個語料庫中的重要性。這種方法能夠減少常見詞的權重 (例如 the, of, a),增強重要詞的影響力,但仍然無法捕捉詞與詞之間的語義關係。
4. N-gram (用統計的方法捕捉上下文資訊)
N-gram模型通過考慮相鄰詞的組合來捕捉部分上下文信息。它能夠更好地反映詞之間的依賴關係,但隨著N的增大,維度和計算複雜度也迅速增加。
5. Word2Vec (CBOW, Skip-Gram,用淺層神經網絡訓練捕捉上下文資訊)
Word2Vec是由Mikolov等人提出的嵌入技術,包括CBOW(Continuous Bag of Words)和Skip-Gram兩種模型。這些模型通過神經網絡訓練,使得詞的嵌入向量可以捕捉語義上的相似性。詞向量之間的距離反映了詞之間的語義關係,這大大提高了文本表示的效果。
6. Transformer (BERT, GPT,用 transformer 捕捉上下文資訊:多頭,全局。BERT - 雙向,GPT - 單向)
Transformer模型是近年來的重大突破。BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)等模型通過自注意力機制能夠同時考慮句子中所有詞之間的關係。這些模型不僅能夠生成高質量的詞嵌入,還能處理各種下游NLP任務,如文本分類、機器翻譯等。
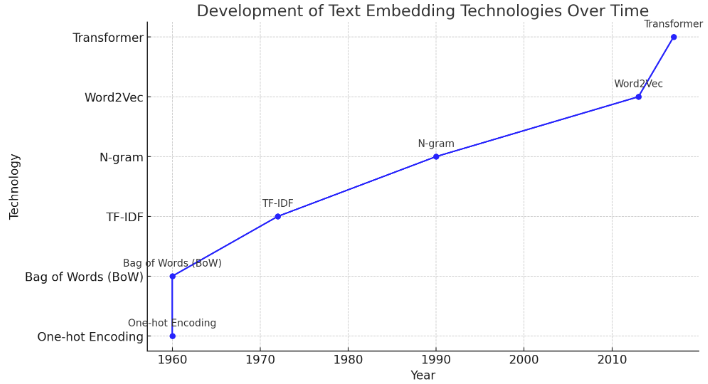
不同嵌入方法的比較
| 嵌入方法 | 特點 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|---|
| One-hot Encoding | 字典 | 簡單易懂,實現容易 | 高維度、稀疏性、無法捕捉語義關係 | 簡單文本處理 |
| Bag of Words (BoW) | 區分字的重要性 | 計算簡單,實現容易 | 無法捕捉語義和上下文信息 | 文本分類、主題建模 |
| TF-IDF | 移除常用且無用字 | 考慮詞的重要性,減少常見詞的權重 | 無法捕捉語義和上下文信息 | 信息檢索、文本分類 |
| N-gram | 統計捕捉上下文 | 捕捉部分上下文信息,反映詞依賴關係 | 維度和計算複雜度隨N增大 | 語言模型、文本生成 |
| Word2Vec | 淺層網路捕捉上下文 | 捕捉語義相似性,低維密集向量 | 需大量訓練數據,無法處理OOV詞 | 詞語相似性計算、文本分類 |
| Transformer | 深度學習捕捉上下文 | 捕捉全局語義關係,適用於多種NLP任務 | 計算資源需求高,訓練時間長 | 文本分類、機器翻譯、文本生成 |
這些嵌入方法的發展,從簡單到複雜,逐步提升了文本表示的能力和準確性。One-hot和BoW雖然簡單,但無法有效捕捉詞之間的語義關係。TF-IDF和N-gram引入了詞的重要性和部分上下文信息,但仍有局限。Word2Vec引入了語義相似性的大幅提升,而Transformer模型則進一步提高了對全局語義和上下文的理解能力,成為當前NLP領域的主流技術。
Text Embedding 的應用
- Analytic AI:文本分類
- Generative AI:文本生成
- Text search, RAG 等和 vector database 有關的應用
1 and 2 有另外的專文。接下來先看 3.
如何使用 Text Embeddings 做為 search?
嵌入是一種分配給每個句子(或更一般地說,分配給每個文本片段,可以短至一個單詞或長至整篇文章)一個向量的方法,該向量是一個數字列表。本文代碼實驗室中使用的 Cohere 嵌入模型返回一個長度為 4096 的向量。這是一個包含 4096 個數字的列表(其他 Cohere 嵌入,例如多語言嵌入,返回較小的向量,例如,長度為 768)。嵌入的一個非常重要的特性是相似的文本片段被分配給相似的數字列表。例如,“你好,你好嗎?”這句話和一句“嗨,怎麼了?”將被分配相似數字的列表,而句子“明天是星期五”將被分配一個與前兩個完全不同的數字列表。
在下一張圖片中,有一個嵌入示例。為了視覺上的簡單,這個嵌入為每個句子分配了一個長度為 2 的向量(兩個數字的列表)。這些數字作為坐標繪製在右側的圖表中。例如,句子“The world cup is in Qatar”被分配給向量 (4, 2),因此它被繪製在坐標為 4(水平)和 2(垂直)的點上。
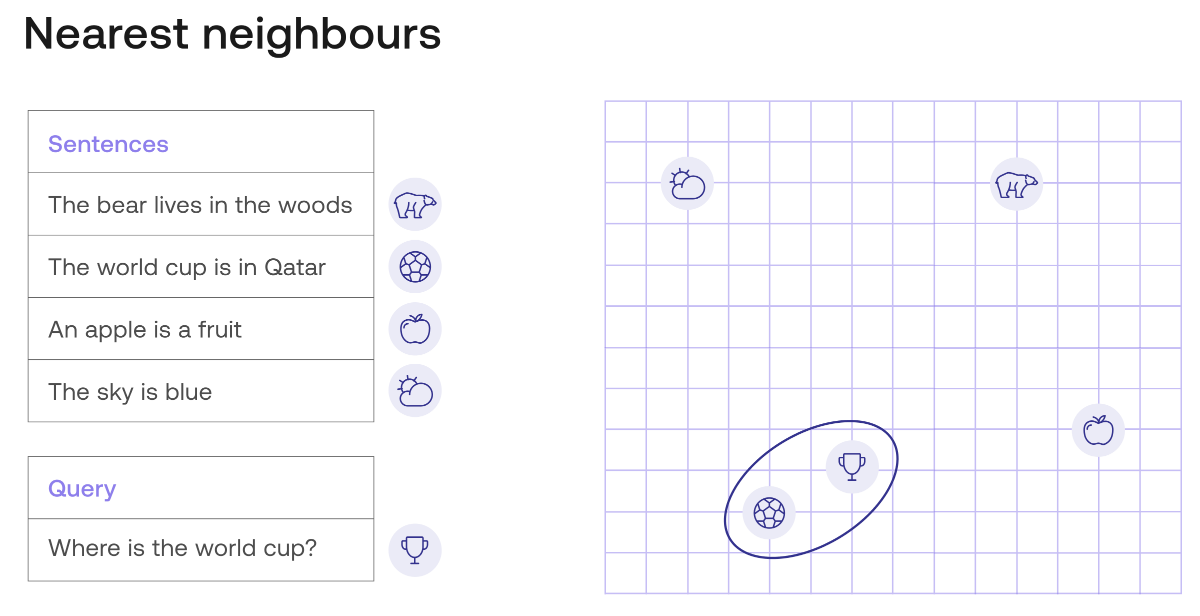
在此圖像中,所有句子都位於平面中的點。在視覺上,您可以確定查詢(由獎杯表示)最接近回應 “The world cup is in Qatar”,由足球表示。其他查詢(由雲、熊和蘋果表示)要遠得多。因此,語義搜索將返回 “The world cup is in Qatar” 的回應,這是正確的回應。
但在我們進一步深入之前,讓我們實際使用現實生活中的文本嵌入在一個小數據集中進行搜索。以下數據集有四個查詢及其四個相應的回應。
Dataset:
Queries:
- Where does the bear live?
- Where is the world cup?
- What color is the sky?
- What is an apple?
Responses
- The bear lives in the woods
- The world cup is in Qatar
- The sky is blue
- An apple is a fruit
We can use the Cohere text embedding to encode these 8 sentences. That would give us 8 vectors of length 4096, but we can use some dimensionality reduction algorithms to bring those down to length 2. Just like before, this means we can plot the sentences in the plane with 2 coordinates. The plot is below.
我們可以使用 Cohere text embedding 來編碼這 8 個句子。這將給我們8個長度為4096的向量,但我們可以使用一些降維演算法將它們減少到長度為2。就像以前一樣,這意味著我們可以用 2 個座標在平面上繪製句子如下。
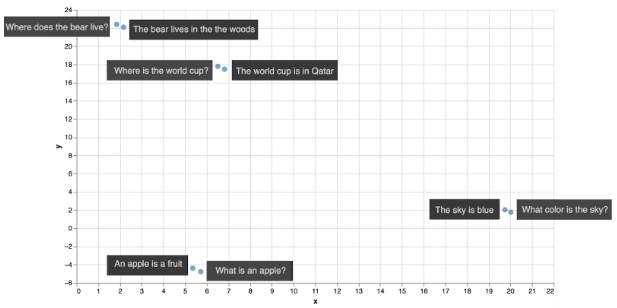
請注意,每個查詢最接近其相應的回應。這意味著,如果我們使用語義搜索來搜索對這 4 個查詢中的每一個的回應,我們將得到正確的回應。但是,這裡有一個警告。在上面的例子中,我們使用了歐幾里得距離,它只是平面中的距離。這也可以推廣到 4096 個條目的向量(使用勾股定理)。但是,這不是比較文本片段的想法方法。最常用和給出最佳結果的方式是相似性,我們將在下一節中研究。
使用 Similarity (相似度) 尋找最佳文本
相似性是一種判斷兩段文本是否相似或不同的方法。這使用 text embedding。此處是 sensentce embedding 而非 word embedding。如果您想了解相似性,請查看這篇文章。在本文中,描述了語義搜索中使用的兩種相似性:
-
點積 (dot product) 相似度
-
餘弦 (cosine) 相似度
現在,讓我們將它們視爲一個概念。相似度就是指定給兩個文本關係的一個數字,具有以下屬性:
- 一段文字與其自身的相似度是一個非常高的數字。
- 兩段非常相似的文本之間的相似度很高。
- 兩段不同的文本之間的相似度很小。
本文使用餘弦相似度,因爲它具有一個額外的屬性,即返回值介於 0 和 1 之間。一段文本與其自身之間的相似度始終為 1,並且相似度可以取的最低值為0(當兩段文本確實非常不同時)。
現在,為了語義搜索,所要做的就是計算查詢 query 與每對句子之間的相似度,並返回相似度最高的句子。舉個例子。下面是上述數據集中 8 個句子之間的餘弦相似度圖。

上圖的比例在右側給出。請注意以下特性:
- 對角線全是 1(因為每個句子與其自身的相似度為 1)。類似 graph 的 degree matrix?
- 每個句子與其相對應的回應之間的相似度約為 0.7。
- 任何其他兩個句子對之間的相似性都是較低的值。
這意味著,如果您要搜索 “What is an apple?” 這樣的查詢的答案,語義搜索模型會查看表格的倒數第二行,並找到到最接近的句子是 “What is an apple?” (相似度為 1)和 “An apple is a fruit” (相似度約為 0.7)。系統將從列表中刪除相同的查詢 (相似度為 1),因為它不想用相同於 query 來回應 (overfit or trivial)。因此,勝出的回應是 “An apple is a fruit”。這也是正確的回答。
這裡有一個隱藏的算法我們沒有提到,但是很重要:nearest neighbors algorithm (最近鄰算法。Again,是否暗示 graph!)。簡而言之,該算法找到數據集中某個點的最近鄰。在這個例子,算法找到了句子 “What is an apple?” 的最近鄰,而回應是句子 “An apple is a fruit”。
在下一節中,您將了解有關最近鄰的更多信息。
最近鄰算法 (Nearest Neightbors Algorithm) - 優點和缺點,以及如何解決它們
最近鄰是一種非常簡單且有用的算法,通常用於分類。 更一般地說,它稱為 k-nearest neighbors (knn),其中 k 是任意數字。 如果手頭的任務是分類,knn 將簡單地查看特定數據點的 k 最近鄰,並為數據點分配鄰居中最常見的標籤。 例如,如果手頭的任務是將一個句子分類為快樂或悲傷(情感分析),那麼 knn (k=3) 會做的是查看該句子的 3 個最近的鄰居(使用 embedding),並查看它們是否大多數(2)是快樂的或悲傷的。 這是它指定給句子的標籤。
knn 正是本文中為語義搜索所用的算法。 給定一個查詢,您在 embedding 中尋找最近的鄰居,這就是對查詢的回應。 在上例中,knn 效果很好。
然而,knn 並不是最快的算法。 原因是為了找到一個點的鄰居,需要計算該點與數據集所有其他點之間的距離,然後找到最小的一個。 如下圖所示,為了找到與 “where is the world cup?” 這句話最近的鄰居,我們必須計算 8 個距離,每個數據點都要算一次。
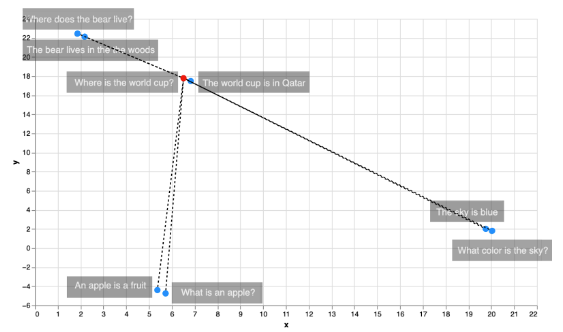
然而,當處理大量資料時,我們可以通過稍微調整算法以成為近似 knn 優化性能。 特別是在搜索方面,有幾項改進可以大大加快這個過程。 這是其中的兩個:
-
Inverted File Index (IVD):包括對相似文檔進行聚類,然後在最接近查詢的聚類中進行搜索。
-
Hierarchical Navigable Small World (HNSW):包括從幾個點開始,然後在那裡搜索。 然後在每次迭代中添加更多點,並在每個新空間中搜索。
多語言搜索
語義搜索的性能取決於 embedding 的能力。 因此 embedding 的能力可以轉化為語義搜索模型的能力,包含多語言的 embeddings。簡而言之,多語言 embedding 會將這些語言中任何文本映射到一個向量。 相似的多語言文本片段將被發送到相似的向量。 因此,可以使用任何語言的查詢(query)進行搜索,模型將搜索所有其他語言的答案。
下圖可以看到多語言 embedding 的示例。 Embedding 將每個句子映射到一個長度為 4096 的向量,就像在前面的示例中一樣,使用投影將這個向量映射到 2D 平面。

在此圖中,我們有 4 個英語句子,以及它們的西班牙語和法語直接翻譯。
English:
- The bear lives in the woods.
- The world cup is in Qatar.
- An apple is a fruit.
- The sky is blue.
Spanish:
- El oso vive en el bosque.
- El mundial es en Qatar.
- Una manzana es una fruta.
- El cielo es azul.
French:
- L’ours vit dans la forêt.
- La coupe du monde est au Qatar.
- Une pomme est un fruit.
- Le ciel est bleu.
正如圖中看到的,多語言模型將每個句子及其兩個翻譯非常靠近。
Embedding 和 Similarity 是否足夠 (No)?
在本文中,您已經了解了當搜索模型由實體嵌入和基於相似性的搜索組成時,它是多麼有效。 但這就是故事的結局嗎? 不幸的是(或者幸運的是?)沒有。 事實證明,僅使用這兩個工具可能會導致一些意外。 幸運的是,這些是我們可以解決的事故。 這是一個例子。 讓我們稍微擴展一下我們的初始數據集,添加更多對世界杯問題的回答。 考慮以下句子。
Query: “Where is the world cup?”
Responses:
-
The world cup is in Qatar
-
The world cup is in the moon
-
The previous world cup was in Russia
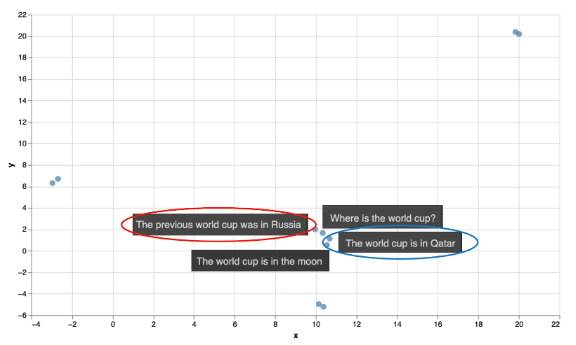
當我們在上面的嵌入中定位它們時,正如預期的那樣,它們都很接近。 然而,最接近查詢的句子不是回應 1(正確答案),而是回應 3。這個回應(“The previous world cup was in Russia”)是一個正確的陳述,並且在語義上接近問題,但它不是 問題的答案。 回應 2(“The world cup is in the moon”)是一個完全錯誤的答案,但在語義上也接近查詢。 正如您在 embedding 中看到的那樣,它非常接近查詢,這意味著像這樣的虛假答案很可能成為語義搜索模型中的最佳結果。
如何解決這個問題? 有很多方法可以提高搜索性能,使模型返回的實際回應是理想的,或至少接近理想的。 其中之一是 multiple negative ranking loss (多重負排序損失, from information retrieval, face recogintion):具有 positive pairs(查詢、回應)和幾個 negative pairs(查詢、錯誤回應)。 訓練模型以獎勵 positive pairs,並懲罰 negative pairs。
在當前的示例中,我們將採用一對肯定的 (query, response) 對,例如:
(Where is the world cup?, The world cup is in Qatar)
我們還會採用幾個否定(查詢、回應)對,例如:
- (Where is the world cup?, The world cup is in the moon)
- (Where is the world cup?, The previous world cup was in Russia)
- (Where is the world cup?, The world cup is in 2022.)
通過訓練模型對 negative pairs 做出負面回應,模型更有可能對查詢給出正確答案。
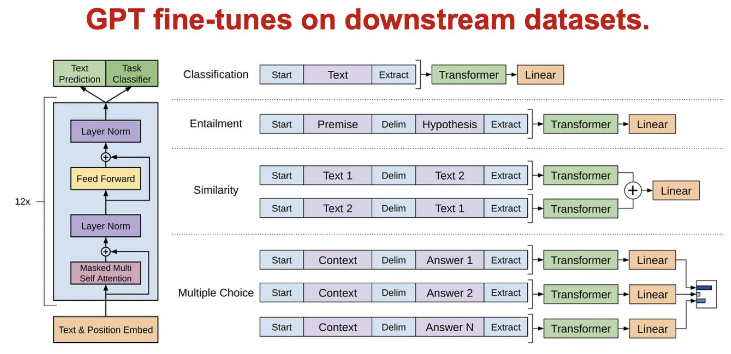
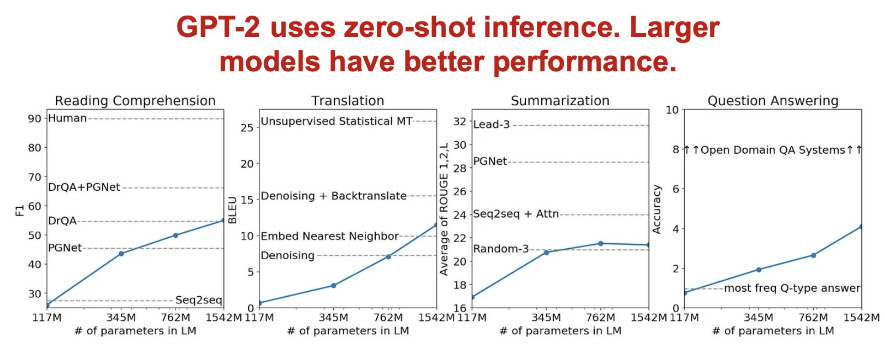
NLP Sematic Search and Classification Task
| Computer Vision | Voice | NLP | |
|---|---|---|---|
| Classification | dog, cat, very mature | sound scene | sentiment analysis, Q & A |
| Detection | bounding box | special sound, instrument | Q & A with start/end index |
| Recognition | Face recognition | Voice ID | Author ID? |
| Speech recognition | Figure caption? (img to text) | ASR (voice to text) | Translation? (text to text) or summary? |
| De-noise | De-noise | De-noise | Fill in empty |
| Super resolution | SR | SR | x (somewhat GAI) |
| MEMC | Inpainting, insert sequence | make voice more clear | x (somewhat GAI) |
| Chat | text to image | text to music/speech | Dialog, or generative AI (text-to text) |
Reference
Serrano, Luis. “What Are Word and Sentence Embeddings?” Context by Cohere. January 18, 2023.
https://txt.cohere.ai/sentence-word-embeddings/.
———. “What Is Semantic Search?” Context by Cohere. February 27, 2023.