Source
- Speculative Decoding with Big Little Decoder!!
- https://arxiv.org/abs/2302.07863
- Cloud-edge hybrid SpD! [2302.07863] Speculative Decoding with Big Little Decoder (arxiv.org)
前言
Big-Little Speculative Decode 主要是解決 autoregressive generation speed 太慢的問題。
此技術的核心便在於如何儘可能又快又準地生成 draft token,以及如何更高效地驗證 (verification)。
其他的應用:假設大小模型。大模型在雲,小模型在端。
- 小模型 Predict the response length
- 小模型 predict local or cloud tasks.
Speculative Decoding with Big Little Decoder
[paper] [paper reading]
本文把是否需要大模型進行確認的權力交給了小模型,稱之爲 Fallback。Fallback 之後,對於兩次 Fallback 之間小模型生成的 token,引入 Rollback 確保其性能。
| 在第 n 次解碼迭代中,小模型和大模型各自輸入一個部分生成的輸出文本 $ y_{1:n-1} = (y_1, \cdots, y_{n-1}) $,然後分別生成一個在整個詞彙表上的概率分佈 $ p_S(y | y_{1:n-1}) $ 和 $ p_L(y | y_{1:n-1}) $。接著,從概率分佈中取樣下一個詞 $ y_{n,S} $ 和 $ y_{n,L} $: |
| $y_{n,S} \sim p_S(y | y_{1:n-1}) $ 以及 $ y_{n,L} \sim p_L(y | y_{1:n-1}) $ |
| 回退策略 (Fallback Policy):如果 $ \max_y p_S(y | y_{1:n-1}) < \alpha_{FB} $,則回退到大模型並設置 $ y_n = y_{n,L} $。 |
| 回滾策略 (Rollback Policy):如果存在一個最小的 $ m \in [1, n-1] $ 使得 $ d(p_S(y | y_{1:m}), p_L(y | y_{1:m})) > \alpha_{RB} $,則回滾預測 $ (y_m, \cdots, y_n) $ 並設置 $ y_m = y_{m,L} $。 |
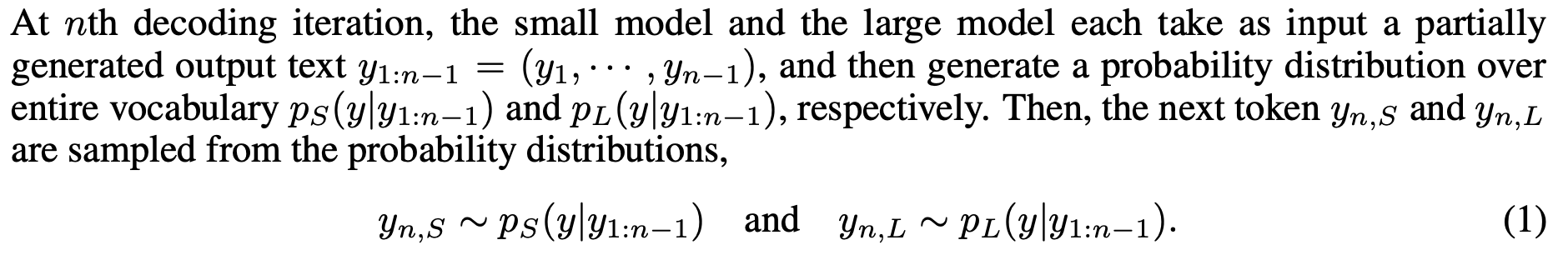
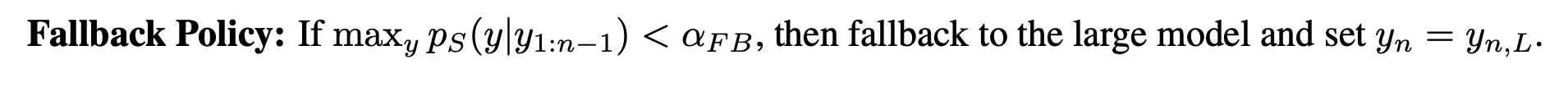
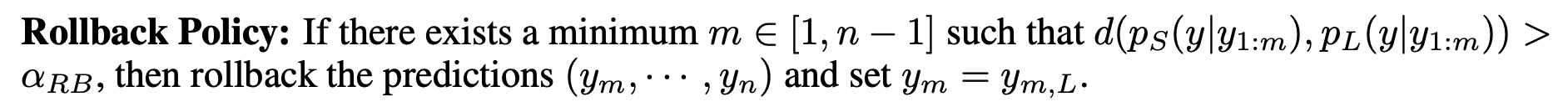
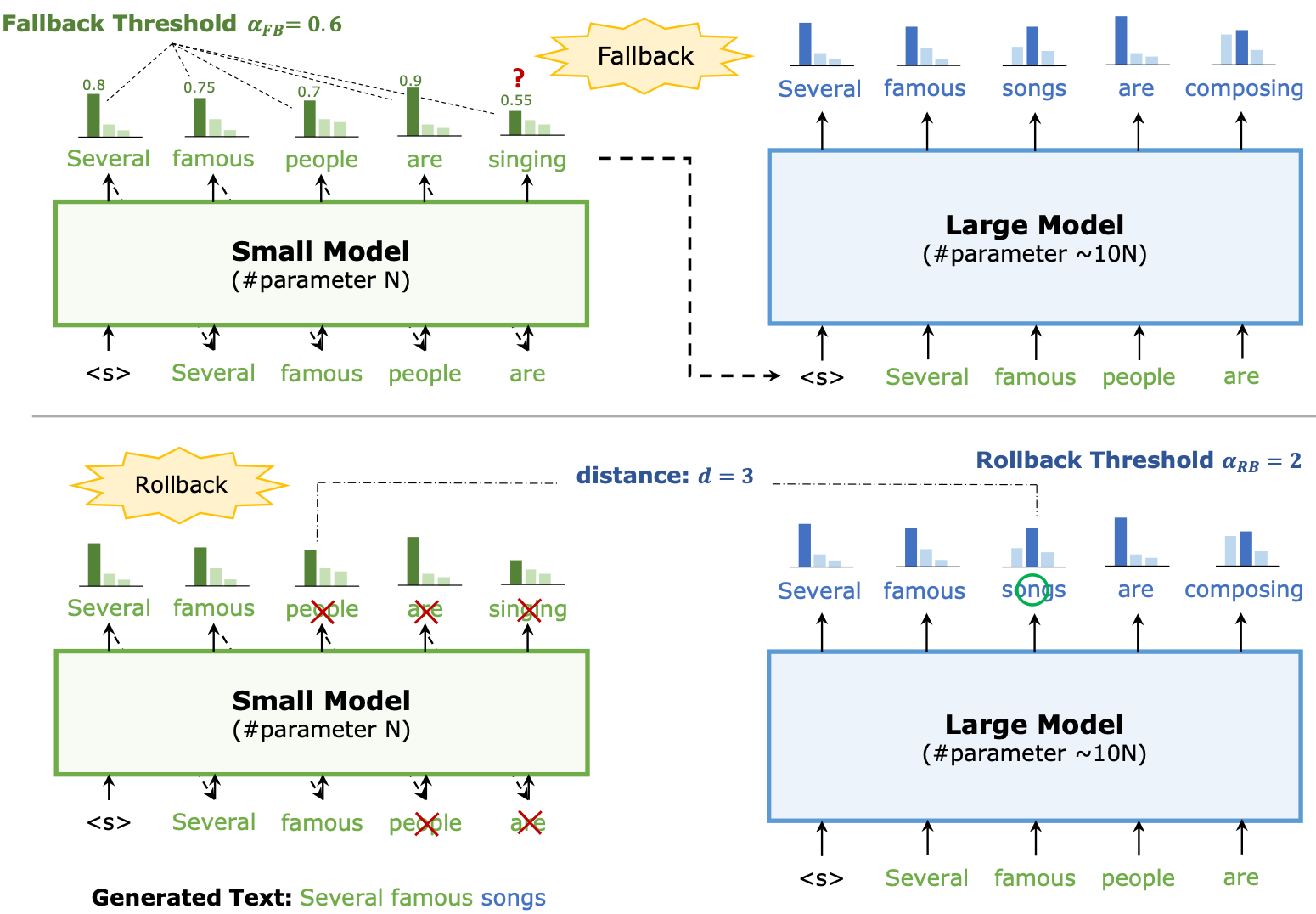
具體來說,一旦小模型在當前 token 輸出機率的最大值低於設定的閾值 𝛼𝐹𝐵,就進行 Fallback,開始引入大模型進行 verify。在 verify 過程中,計算每個 token 上大小模型輸出機率之間的距離 𝑑,一旦 𝑑 大於設定的閾值 𝛼𝑅𝐵,就將此 token 改爲大模型的輸出,並讓小模型在後續從這個 token 開始生成。
此方法無法確保輸出與原模型完全一致。實驗的模型比較小,未超過 1B。
GKT: A Novel Guidance-Based Knowledge Transfer Framework For Efficient Cloud-edge Collaboration LLM Deployment
[paper] [paper reading]
Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline
[paper] [paper reading]
這個 paper 說明:因為 LLM 可以“說話”,可以直接利用這個特點,詢問 LLM 得到資訊作為後續性能優化。
這裡舉兩個例子:(1) 請 LLM 先估計回答的長度;(2) 請 LLM 先估計問題的難度。
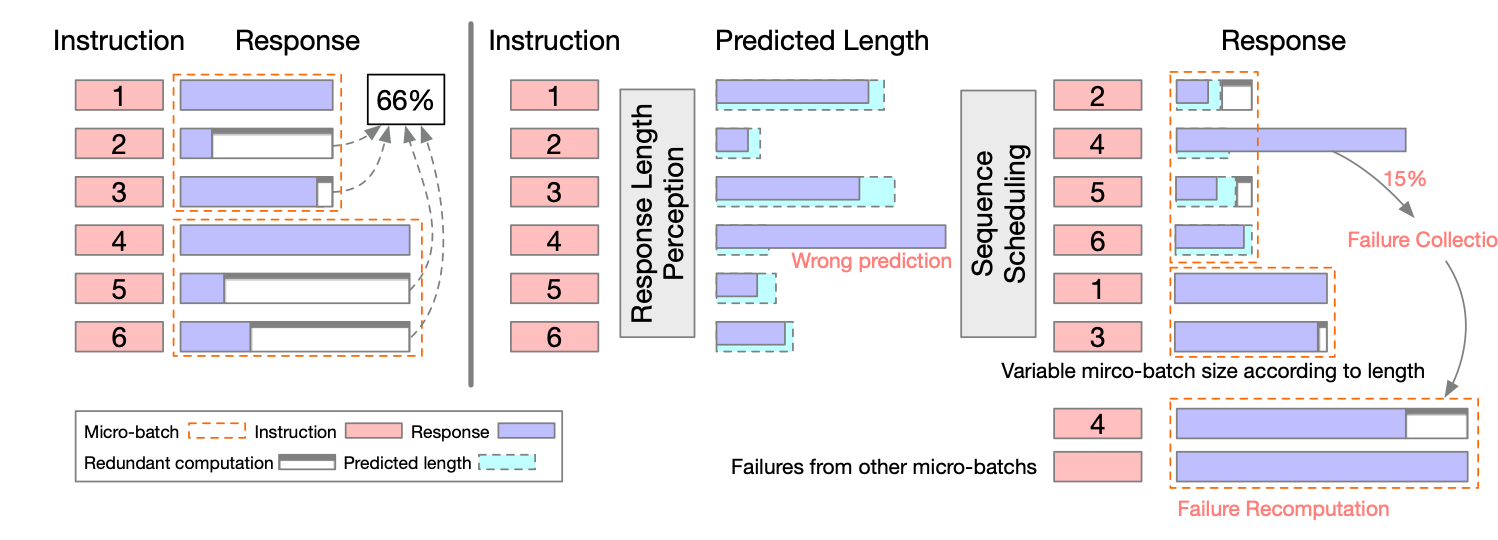
估計回答的長度:
利用如下的 prompt. 如此 LLM 在回答之前,會先估計回答的長度。對於多個 batches 的回覆,可以先排程而有跟好的優化結果。
Create a fun math question for children.
Before responding to the above instruction, you have to predict the length of your response. Print the estimated number of words in your response in the first line. Then change to a new line to respond to the instruction.
ChatGPT
16
Imagine you have 10 apples and you give 3 to your friend. How many apples do you have left? 🍎
不過有幾個問題:
- 使用 words 比 tokens 更準確。
- 額外的 prompt 實際上影響回覆。 (1) 回覆的長度本身就是變動的, depending on temperature. (1) LLM 似乎會根據回覆的長度,自動控制回覆的內容。
- 這個估計並不準確,depending on LLM size. GPT4 表現最好,但是也不是 100%. 還是需要補救措施。
估計回答的難度:
- 看起來 GPT4o 和 Llama3 8B 對於問題的判斷都還不錯。不過可能要做更完整的測試,利用 MMLU 或其他 terst dataset.
Assuming there is a 10-times more powerful model than you are. I will ask a question. You need to tell me if it’s better for you or the more powerful model to answer.
Question: what’s the capital of England.
ChatGPT
It’s better for me to answer this question.
The capital of England is London.
Question: what is the solution of Riemann Hypothesis
ChatGPT
It’s better for the more powerful model to answer this question.
The Riemann Hypothesis is an unsolved problem in mathematics and requires deep expertise and advanced capabilities to address comprehensively.
Llama3 8B
Assuming there is a 10-times more powerful model than you are. I will ask a question. You need to tell me if it’s better for you or the more powerful model to answer.
Question: The capital of England is London.
Llama
A simple question!In this case, it’s definitely better for me to answer. The capital of England is a well-known fact, and I can provide the correct answer quickly and accurately. The answer is London.The more powerful model wouldn’t be able to provide any additional insight or complexity in this case, so I’m happy to take on the task!
Question: what is the integration of cosine function?
Llama
What a great question!After analyzing the question, I think it’s more suitable for the more powerful model to answer. The integration of the cosine function is a complex mathematical problem that requires a higher level of computational power and mathematical knowledge than I possess.I can try to provide a simple answer, but it would likely be incomplete or inaccurate. The more powerful model, on the other hand, would be able to provide a more detailed and accurate answer, possibly involving advanced mathematical techniques and symbolic manipulation.So, I recommend asking the more powerful model to answer this question.
Question: what’s the height of Mt. Everest?
Llama
A simple question!In this case, it’s definitely better for me to answer. The height of Mt. Everest is a well-known fact, and I can provide the correct answer quickly and accurately. The height of Mt. Everest is 8,848 meters (29,029 feet) above sea level.The more powerful model wouldn’t be able to provide any additional insight or complexity in this case, so I’m happy to take on the task!
To Do:
- 設計一個 LLM test using Llama3 8B. 然後評估錯誤的比例和 dispatch 到 GPT4 的比例!看難度是否可以正確指到大 model.
- 設計特殊的 token 估計長度和難度。
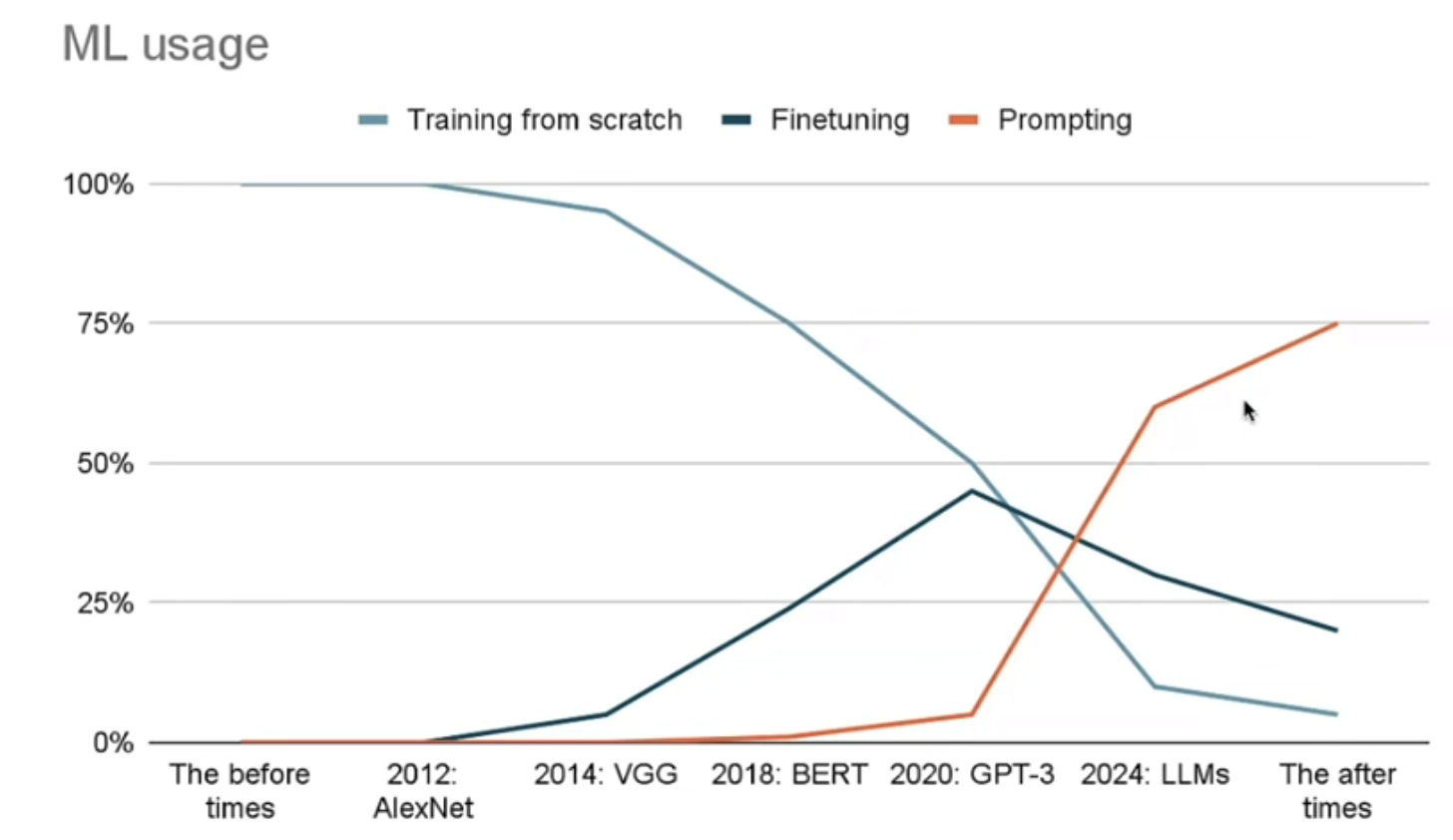
In context prompting 比 finetuning 更實用。