Introduction
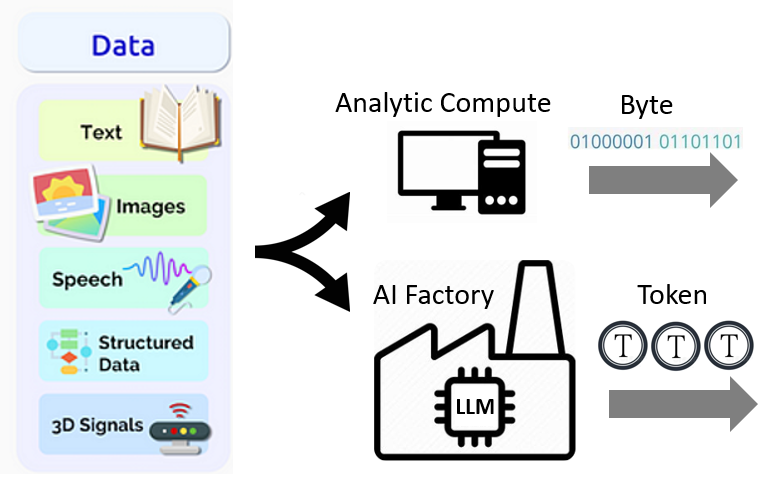
The analytic computing (i.e. traditional computing) emphasizes deterministic computation. The output product is exact byte streams.
The AI factory powered by LLM uses probabilistic computation. The output product is correlated and high-dimensional tokens.
The comparison between Language Model (LLM) tokens and traditional computing bytes in terms of energy and performance metrics is an interesting exercise. Here’s a breakdown of the comparison:
Performance Metrics
Energy Consumption (Energy per Token and Energy per Byte)
-
Energy/Token: The energy consumed by an LLM to process one token (high-dimensional weighted attention operation) can vary significantly depending on the model size, architecture, and hardware. Larger models with more parameters typically consume more energy per token. The basic operation is a high-dimensional weighted attention computation, which is more intensive than matrix multiplications, non-linear transformations, and massive data transfer from external memory.
-
Energy/Byte: The energy consumed to process a single byte in traditional computing is generally much lower compared to the energy per token in an LLM. This is because traditional computing operations, mostly scalar arithmetic or data transfer operations, are less computationally intensive than processing LLM tokens.
Bandwidth Consumption (GHz per Token and GHz per Byte)
-
GHz/Token: This metric represents the data transfer bandwidth needed to process a single token by an LLM. Given the large parameter size and computational complexity of modern LLMs, this can be quite high.
-
GHz/Byte: This metric represents the number of clock cycles needed to process a single byte in traditional computing. Processing a byte typically involves simpler operations (like memory access, basic arithmetic) compared to the operations involved in LLM token processing. The use of cache to reduce external memory access typically makes this number insignificant.
Throughput (Token/sec and Byte/sec)
-
Token/sec: This measures how many tokens an LLM can process per second. This includes input throughput (prompt mode) where the tokens are processed in parallel, and output throughput (generation mode) where the tokens are processed sequentially.
-
Byte/sec: This measures how many bytes a traditional computer can process per second. This metric is generally much higher than tokens per second for LLMs because traditional computing operations are typically less complex. High-performance computers can process billions of bytes per second.
Example Values (Hypothetical)
- Energy/Token (LLM): 0.1 to 10 millijoules per token.
- Energy/Byte (Traditional Computing): 0.001 to 0.01 millijoules per byte.
- GHz/Token (LLM): 10 GHz/token (considering the large number of operations per token).
- GHz/Byte (Traditional Computing): 1 to 10 MHz/byte (considering simpler operations).
- Token/sec (LLM): 10 to 1000 tokens/sec (highly dependent on the model and hardware).
- Byte/sec (Traditional Computing): 1M to 1G bytes/sec (depending on the hardware and type of operation).
Comparison Summary
- Energy: LLMs consume significantly more energy per token compared to traditional computing per byte due to the complexity of operations involved in token processing.
- Clock Speed: The clock cycles per token for LLMs are significantly higher than for bytes in traditional computing.
- Throughput: Traditional computing can process significantly more bytes per second than LLMs can process tokens, again due to the complexity of token processing.
In essence, while LLMs and traditional computing both handle information processing, the complexity of tasks and computational requirements make LLMs much more resource-intensive on a per-token basis compared to the per-byte basis in traditional computing.
An Image is Worth 32 Tokens for Reconstruction and Generation
Reference
An Image is Worth 32 Tokens for Reconstruction and Generation 2406.07550 (arxiv.org)