MMLU 是單選還是復選?應該是單選題。但是標準的 prompt 確是說 multiple choices. 是為了 confuse LLM?
Source
MMLU
- 測試集 dataset: hendrycks
MMLU数据集:https://github.com/hendrycks/test -
測試 code: ollmer: [GitHub - ollmer/mmlu: Measuring Massive Multitask Language Understanding ICLR 2021](https://github.com/ollmer/mmlu) - 測試 code: deepeval (JUNK!): GitHub - confident-ai/deepeval: The LLM Evaluation Framework
- Code: in ml_code/llm_evaluation_4_mmlu/evaluate_hf.ipynb and evaluate_llama.ipynb
MMLU Pro
- 測試集:Tiger-Lab: TIGER-Lab/MMLU-Pro · Datasets at Hugging Face
- [2406.01574] MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark (arxiv.org)
-
測試 code: ollama + …: Colab/mmlu_pro_gpt.ipynb and Colab/mmlu_pro_ollama_llama3.ipynb
- Sebastian 好像也有 code to evaluate MMLU performance? NO, 不是 MMLU!! Some simple examples
- LLM-from-scratch/ch07/03_model-evaluation/llm-instruction-eval-openi/ollama.ipynb
MMLU和MMLU-Pro的比較
| 特徵 | MMLU | MMLU-Pro |
|---|---|---|
| 範圍和內容 | 包含各種領域的廣泛問題集,主要以知識為主。評估模型的記憶和理解能力。 | 在MMLU的基礎上添加了更複雜的推理問題。重點在於評估高階認知技能,如問題解決和批判性思維。 |
| 難度等級 | 包含混合難度的問題,其中一些相對簡單或瑣碎。 | 通過去除簡單和噪聲問題並整合需要更深層推理的問題,顯著提高了挑戰性。 |
| 選項數量 | 每個問題提供四個選項。 | 選項擴展到十個,增加了難度,減少了隨機猜對的可能性。 |
| 準確性和敏感性 | 當前模型已達到高準確度,導致性能趨於平緩,對提示變化敏感(4-5%敏感性)。 | 由於難度增加,準確率顯著下降(比MMLU低16%到33%)。對提示變化的敏感性減少到僅2%,顯示出更大的穩定性和穩健性。 |
| 推理與直接回答 | 模型通常在直接回答技術上表現良好。 | 使用鏈式思考(CoT)推理的模型表現優於直接回答的模型,強調數據集對複雜推理任務的關注。 |
Introduction
大模型(LLM)的评测是衡量大模型效果的关键步骤,也是模型流水线中必不可少的过程。常见的大模型排行榜或平台有🤗 Open LLM Leaderboard、OpenCompass、Chatbot Arena Leaderboard.
那么,大模型的评测是如何实现的呢?
本文将会以MMLU数据集为例,考察主流开源大模型,如LLAMA-2, BaiChuan-2等模型的评估实现及结果,希望能管中规豹,一探究竟。
NLP(七十八)大模型探索:MMLU数据集评测 - My Github Blog (percent4.github.io)
MMLU数据集
MMLU数据集已开源至Github平台,访问网址为:https://github.com/hendrycks/test .
MMLU(Massive Multitask Language Understanding)是一个新的基准,用于衡量在零样本(zero-shot)和少样本(few-shot)情形下,大模型在预训练期间获得的世界知识。这使得该基准测试更具挑战性,也更类似于我们评估人类的方式。该基准涵盖 STEM、人文(humanities)、社会科学(social sciences)等领域的 57 个学科(subject)。 它的难度从初级到高级,既考验世界知识,又考验解决问题的能力。 学科范围从数学和历史等传统领域到法律和伦理等更为专业的领域。学科的粒度和广度使该基准成为识别模型盲点的理想选择。
類別和子類別
MMLU 數據集的類別和子類別結構:
- STEM (6 sub-categories)
- Mathematics
- Physics
- Chemistry
- Biology
- Computer Science
- Engineering
- Humanities (3 sub-categories)
- History
- Philosophy
- Law
- Social Sciences (4 sub-categories)
- Economics
- Psychology
- Political Science
- Geography
- **Other **(4 sub-categories)
- Health
- Culture
- Business
- Other
MMLU数据集共收集了15908个问题,并将其分为few-shot开发集、验证集和测试集。 few-shot开发集每个学科有5个问题,验证集可用于选择超参数,由1540个问题组成,测试集有14079个问题。 每个学科至少包含100个测试问题,这比大多数旨在评估人类的考试都要长。
我们来看其中一个示例:
1 | |
Dataset 的格式: [question, subject, choices, answer]
- question: 就是問題本身
- subject: 就是 category,一共有 57 分類
- choices: 4 個可能的選擇,對應 {A, B, C, D}
- answer: 真正的答案
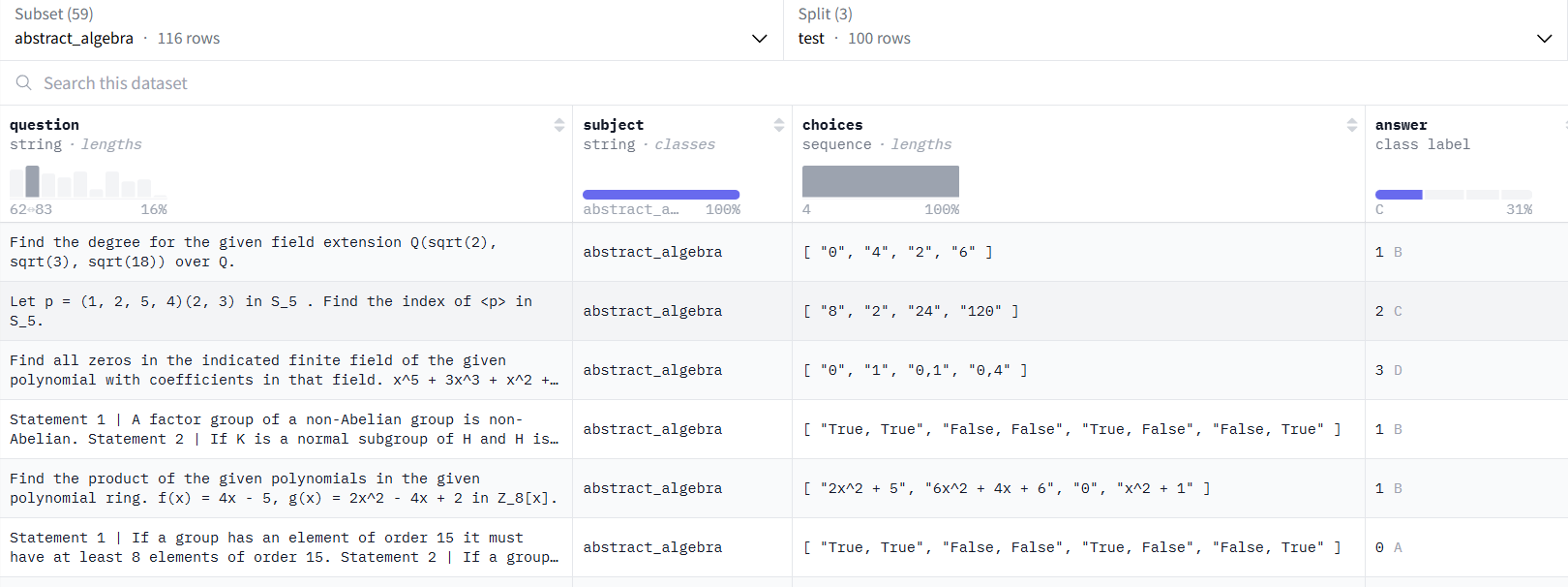
不同大語言模型 MMLU 性能
57 類別一般分成 4 大類: STEM (Science, Technology, ? 科學技術相關), Humanities (Law, Philosophy, 從亞里士多德就存在), Social Science (Economics, Psychology, ?, 想依附到科學), Others (醫學相關)
| STEM (19 學門, 1800 題) | Humanities (13 學門, 1638 題) | Social Sciences (12 學門, 1368 題) | Other (13 學門, 1890 題) |
|---|---|---|---|
| ABSTRACT_ALGEBRA | FORMAL_LOGIC | ECONOMETRICS | BUSINESS_ETHICS |
| ANATOMY | HIGH_SCHOOL_ EUROPEAN_HISTORY |
HIGH_SCHOOL_ GEOGRAPHY |
CLINICAL_KNOWLEDGE |
| ASTRONOMY | HIGH_SCHOOL_ US_HISTORY |
HIGH_SCHOOL_ GOVERNMENT_AND_POLITICS |
COLLEGE_MEDICINE |
| COLLEGE_BIOLOGY | HIGH_SCHOOL_ WORLD_HISTORY |
HIGH_SCHOOL _MACROECONOMICS |
GLOBAL_FACTS |
| COLLEGE_CHEMISTRY | INTERNATIONAL_LAW | HIGH_SCHOOL _MICROECONOMICS |
HUMAN_AGING |
| COLLEGE_COMPUTER_SCIENCE | JURISPRUDENCE | HIGH_SCHOOL_ PSYCHOLOGY |
MANAGEMENT |
| COLLEGE_MATHEMATICS | LOGICAL_FALLACIES | HUMAN_SEXUALITY | MARKETING |
| COLLEGE_PHYSICS | MORAL_DISPUTES | PROFESSIONAL_PSYCHOLOGY | MEDICAL_GENETICS |
| COMPUTER_SECURITY | MORAL_SCENARIOS | PUBLIC_RELATIONS | MISCELLANEOUS |
| CONCEPTUAL_PHYSICS | PHILOSOPHY | SECURITY_STUDIES | NUTRITION |
| ELECTRICAL_ENGINEERING | PREHISTORY | SOCIOLOGY | PROFESSIONAL_ACCOUNTING |
| ELEMENTARY_MATHEMATICS | PROFESSIONAL_LAW | US_FOREIGN_POLICY | PROFESSIONAL_MEDICINE |
| HIGH_SCHOOL_BIOLOGY | WORLD_RELIGIONS | VIROLOGY | |
| HIGH_SCHOOL_ CHEMISTRY |
|||
| HIGH_SCHOOL_ COMPUTER_SCIENCE |
|||
| HIGH_SCHOOL_ MATHEMATICS |
|||
| HIGH_SCHOOL_ PHYSICS |
|||
| HIGH_SCHOOL_ STATISTICS |
|||
| MACHINE_LEARNING |
4 大類 (categories), 17 子類 (sub-categories)
1 | |
Use LLM_EVALUATION_4_MMLU! (official)
官方數據
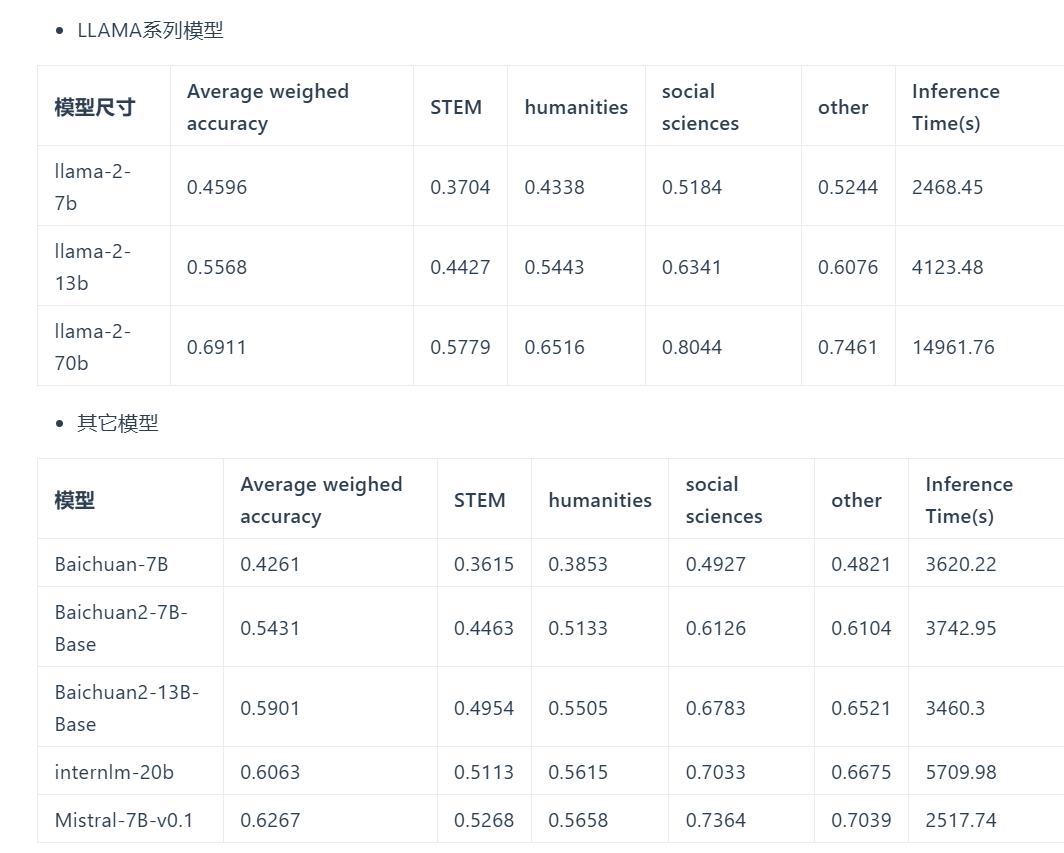
自己執行的結果:
| 模型 | Accuracy | STEM (18,1800) | Humanities (13,1638) | Social Sciences (12, 1368) | Others (14, 1890) |
|---|---|---|---|---|---|
| Llama3-8B (5 shot) | 65.0 | 55.8 | 58.9 | 76.3 | 71.6 |
| Llama2-7B (5 shot) | 46.0 | 37.0 | 43.3 | 51.8 | 52.4 |
| Mistral-7B (5 shot) | 62.6 | 52.6 | 56.5 | 73.5 | 70.4 |
| Phi3-3.8B-4K (5 shot) | 69.2 | 59.8 | 65.4 | 80.1 | 73.1 |
- Phi-3-3.8B 表現勝過 Llama3-8B? 不確定是否因為 training 過
- All models: 最差的是 STEM, 最好的是 Social Sciences.
- All models: STEM 最差的是 math, Humanities 最差的是 law.
Microsoft Phi3
Category and Sub-category
1 | |
Subject
1 | |
Llama3-8B
Category and Sub-category
1 | |
Subject
1 | |
Mistral-7B
Category and Sub-category
1 | |
Subject
1 | |
Appendix
评测代码
放在 ml_code/MMLU/…/.pyh
引入一般的庫。
1 | |
這裏引入了 categories 和 subcategories 模塊中的類別和子類別信息。定義了多選題的選項,分別為 A, B, C, D。
1 | |
將科目名稱中的下劃線替換為空格,使其更具可讀性。
1 | |
產生 1-shot 的例子。將 pandas data frame (df) 中的單個問題格式化為文本提示。就是把 A, B, C, D 和可選擇的答案結合。如果 include_answer=True, 文本提示包括答案。
1 | |
生成包含科目問題的訓練提示,並附上 k-shot 例子
1 | |
評估模型
1 | |
主程式: 利用 -m 執行 model.
1 | |
DONOT USE Deepeval (JUNK!)!!
-
先用簡單問題測試一下
- 容易卡前頭。要檢查是否都是 A, 因爲是 “Answer: B”
- 容易卡後頭,要檢查一下,如下圖 (all D)
- Single choice or multiple choice questions? Singl choice.
前面 ok, 後面好像有問題

The following results seem completely worng!!
| 模型 | Accuracy | STEM (18,1800) | Humanities (13,1638) | Social Sciences (12, 1368) |
|---|---|---|---|---|
| Llama3-8B-Chinese-Chat (3 shot) | 48 | 65 | 69 | |
| Llama3-8B (3 shot) | 43 | 60 | 61 | |
| Llama2-7B (3 shot) | 30 | 37 | 37 | |
| Mistral-7B (NG!) | NA | NA | NA | |
| Phi3-4K (nshot=0!) | 41 | 54 | 55 |
Remove below
Open AI API
2024/6/19 GPT-4o 和 GPT-3.5 Turbo 的價格差。
GPT-3.5 Turbo 便宜 10 倍,但是準確率也比較差。

GPT 設定
第二步是調用 gpt API,幾個重點:
- 設定模型本身:
- model = “gpt-4o” or “gpt-3.5-turbo-0125”
- 溫度: T = 0 是 greedy decode. T = 0.1 還是以穩定爲主。如果 T = 1 則是創意爲主。
- max_tokens: 最大的 context length, 也就是 KV cache size
- top_p, frequency_penalty, presence_penalty: ?
- 使用結構化 message 的 input prompt:
- role: 訂人設
- content: text 的 question (實際的 input)。應該可以加上 image 的content.
-
回傳 reponse, 其結構應該和 input prompt 一樣
-
message.content: 這是 answer
-
choices? 是同時產生幾個不同的 choices?
-
1 | |
1 | |