介紹
大型語言模型(LLMs)在眾多語言任務和自然語言處理(NLP)基礎模型中展現了卓越的能力。基於這些「通用」模型的產品使用案例正在增加。在這篇文章中,我們將澄清圍繞 LLMs 的常用術語,簡要比較可用的不同調適 (adapting) 方法,最後推薦一個逐步流程圖,以幫助您確定適合您用例的正確方法。
計算能力 C ≈ α × transformer 模型的參數大小 A × 數據的大小 B
α 是一個常數。對於推理,α = 2;對於訓練,α = 6。
一個 Meta 的圖表和下面的摘要表
| 預訓練 (Pre-train) | 持續預訓練 | 全微調 (FFT) | 參數高效微調(PEFT) | 檢索增強生成(RAG) | 上下文學習 (ICL) | |
|---|---|---|---|---|---|---|
| 參數 | 100% | 100% | 100% | 1-6% | – | – |
| 數據 | 100% | 10% | 1% | 1% | 外部數據庫 | 幾個示例 |
| GPU 小時 | 1000’s | 100’s | 10’s | 1’s | 1’s | 0 |
| 方法 | 自監督學習*(SSL) | 自監督學習(SSL) | 監督學習(SL)或強化學習(RL) | 監督學習(SL) | 數據庫索引 (database indexing) | 提示工程 (prompt engineering) |
| 軟體 | 訓練 | 訓練 | 微調 | 微調 | RAG + 推理 | 推理 |
| 目的 | 建立基礎模型 | 增強基礎模型 | 指令跟隨、人類對齊 | 自定義、風格變更 | 實時內容、減少幻覺 | 提高準確性 |
- Pre-train is mostly SSL, but also with SFT (Supervised Fine-tuning) and HFRL (Human Feedback Reinforcement Learning)
- SSL: Self-Supervised Learning 自監督學習
- SL: Supervised Learning 監督學習
- RL: Reinforcement Learning 強化學習

LLM 調適方法
預訓練 (Pre-training)
預訓練是從頭開始訓練 LLM 的過程,使用數兆 (T) 的數據 tokens。該模型使用自我監督算法 (SSL) 進行訓練。最常見的訓練方式是通過自回歸 (AR) 地預測下一個 tokens(即因果語言建模)。預訓練通常需要數千小時的 GPU 時間,分佈在多個 GPU 上。預訓練的輸出模型被稱為基礎模型。
持續預訓練 (Continued pre-training)
持續預訓練(即第二階段預訓練)涉及使用新的、未見過的領域數據進一步訓練基礎模型。使用與初始預訓練相同的自我監督算法。所有模型權重通常都會參與,並且將原始數據的一部分與新數據混合。
微調 (Fine-tuning)
微調是使用帶有標註數據集的監督方式 (SL)或使用基於**強化學習 (RL) **的技術來調適預訓練語言模型的過程。與預訓練相比,有兩個主要區別:
-
在帶有正確標籤/答案/偏好的標註數據集上進行監督訓練,而不是自我監督訓練。
-
需要的tokens數量較少(數千或數百萬,而不是預訓練所需的數十億或數兆),主要目的是增強指令跟隨、和人類對齊、任務表現等能力。
理解當前微調有兩個維度:1. 改變的參數百分比和 2. 微調帶來的新能力。
改變的參數百分比
根據改變的參數數量,有兩類算法:
-
完全微調: 顧名思義,這包括改變模型的所有參數,並包括在像 XLMR 和 BERT(100 – 300M 參數)這樣的小型模型上進行的傳統微調,以及在大型模型如 Llama 2、GPT3(1B+ 參數)等上進行的微調。
-
參數高效微調(PEFT): PEFT 算法僅微調少量額外參數或更新預訓練參數的子集,通常為總參數的 1 – 6%。
添加基礎模型的能力
微調的目的是為預訓練模型添加能力,例如:指令跟隨、和人類對齊等。Chat-tuned Llama 2 是一個例子,它是一個具有新增指令跟隨和對齊能力的微調模型。
檢索增強生成(RAG)
企業還可以通過添加特定領域的知識庫來調適 LLMs。RAG 本質上是「搜索驅動的 LLM 文本生成」。RAG 於 2020 年推出,使用動態提示上下文,該上下文是通過用戶問題檢索的,並注入到 LLM 提示中,以引導其使用檢索到的內容,而不是其預訓練的——可能過時的——知識。Chat LangChain 是一個流行的基於 RAG 的 LangChain 文檔 Q/A 聊天機器人。
上下文學習(ICL)
使用 ICL,我們通過在提示中放置原型示例來調適 LLM。「通過示例演示」在多項研究中已被證明是有效的。這些示例可以包含不同類型的信息:
- 僅輸入和輸出文本——即少量示例學習
- 推理過程:添加中間推理步驟;參見 Chain-of-Thought(CoT)提示
- 計劃和反思過程:添加教導 LLM 計劃和反思其問題解決策略的信息;參見 ReACT
還有多種其他策略可以修改提示,提示工程指南 提供了全面的概述。
選擇正確的調適方法
要決定上述哪種方法適合特定應用,您應考慮各種因素:所需任務的模型能力、訓練成本、推理成本、數據集類型等。下面的流程圖總結了建議,幫助選擇正確的 LLM 調適方法。
這個訣竅是:1. 如果 prompting、ICL、檢索增強生成(RAG)可行,不要動大型語言模型(LLM)。 2. 如果需要動LLM,則從 PEFT 開始,再考慮完整的微調。 3. 最後的手段才是進行預訓練/持續預訓練,如果有足夠的資金和數據。
![[Pasted image 20240815203923.png]]
另一個流程圖顯示了類似的觀察結果。

Appendix A: English Version
Introduction
Large language models (LLMs) have demonstrated exceptional abilities across a plethora of language tasks and natural language processing (NLP) benchmarks. Product use cases based on these “generalized” models are on the rise. In this blog post, we’ll provide guidance for small AI product teams who want to adapt and integrate LLMs into their projects. Let’s start by clarifying the (often confusing) terminology surrounding LLMs, then briefly comparing the different methods of adaptation available, and finally recommending a step-by-step flowchart to identify the right approach for your use case.
A diagram Meta blog and a summary table below
| Pretrain | Continuous Pretrain | Finetune | PEFT | RAG | In-context learning | |
|---|---|---|---|---|---|---|
| Parameter | 100% | 100% | 100% | 1-6% | – | – |
| Data | 100% | 10% | 1% | 1% | External database | A few examples |
| GPU hrs | 1000’s | 100’s | 10’s | 1’s | 1’s | 0 |
| Method | SSL | SSL | SL or RL | SL | Database indexing | Prompt engineering |
| SW | Training | Training | Fine-tuning | Fine-tuning | RAG + Inferencing | Inferencing |
| Purpose | Build FM | Enhance FM | Instruction following, human alignment | Customization, style change | Real-time content, reduce hallucination | Increase accuracy |
Approaches to LLM adaptation
Pre-training
Pre-training is the process of training an LLM from scratch using trillions of data tokens. The model is trained using a self-supervised algorithm. Most commonly, training happens by predicting the next token autoregressively (a.k.a. causal language modeling). Pre-training typically requires thousands of GPU hours spread across multiple GPUs. The output model from pre-training is known as a foundation model.
Continued pre-training
Continued pre-training (a.k.a. second-stage pre-training) involves further training a foundation model with new, unseen domain data. The same self-supervised algorithm from the initial pre-training is used. All model weights are typically involved, and a fraction of the original data is mixed with the new data.
Fine-tuning
Fine-tuning is the process of adapting a pre-trained language model using an annotated dataset in a supervised manner or using reinforcement learning-based techniques. There are two major differences compared to pre-training:
-
Supervised training on an annotated dataset—that contains the correct labels/answers/preferences—instead of self-supervised training
-
Requires fewer tokens (thousands or millions instead of the billions or trillions needed in pre-training) where the primary aim is to enhance abilities like instruction following, human alignment, task performance, etc.
There are two dimensions to understanding the current landscape of fine-tuning: percentage of parameters changed and new capabilities added as a result of the fine-tuning.
Percentage of parameters changed
Depending on the number of parameters changed, there are two categories of algorithms:
-
Full fine-tuning: As the name suggests, this encompasses changing all parameters of the model and includes legacy fine-tuning as done on smallish models like XLMR and BERT (100 – 300M parameters) as well as fine-tuning on large models like Llama 2, GPT3 (1B+ parameters), etc.
-
Parameter-efficient fine-tuning (PEFT): Instead offine-tuning all LLM weights, PEFT algorithms only fine-tune a small number of additional parametersorupdate a subset of the pre-trained parameters, typically 1 – 6% of the total parameters.
Capabilities added to a base model
Fine-tuning is carried out with the intention of adding capabilities to the pre-trained model—for example: instruction following, human alignment, etc. Chat-tuned Llama 2 is an example of a fine-tuned model with added instruction-following and alignment capabilities.
Retrieval augmented generation (RAG)
Enterprises can also adapt LLMs by adding a domain-specific knowledge base. RAG is quintessentially “search-powered LLM text generation.” Introduced in 2020, RAG uses a dynamic prompt context that is retrieved using the user question and injected into the LLM prompt in order to steer it to use the retrieved content instead of its pre-trained—and possibly outdated—knowledge. Chat LangChain is a popular Q/A chatbot on LangChain documentation that’s powered by RAG.
In-context learning (ICL)
With ICL, we adapt the LLM by placing prototype examples in the prompt. “Demonstration through examples” has been shown in multiple studies to be effective. The examples can contain different kinds of information:
- Input and output text only—that is, few-shot learning
- Reasoning traces: adding intermediate reasoning steps; see Chain-of-Thought (CoT) prompting
- Planning and reflection traces: adding information that teaches the LLM to plan and reflect on its problem solving strategy; see ReACT
Multiple other strategies to modify the prompts exist, and the Prompt Engineering Guide contains a comprehensive overview.
Choosing the right adaptation method
To decide which of the above approaches are suitable for a particular application, you should consider various factors: the model capability required for the pursued task, cost of training, cost of inference, types of datasets, etc. The flowchart below summarizes our recommendations to assist you in choosing the right LLM adaptation method.
The catch is: 1. Don’t touch the LLM if prompting, ICL, RAG work. 2. If you need to touch the LLM, starting from PEFT, then full fine-tuning. 3. The last method is to do pre-train/contuned pre-train if you have $$$ and data.
![[Pasted image 20240815203935.png]]
Another flow chart says similar observation.
Data Cleaning
![[Pasted image 20240828232305.png]]
長文本模型、微調與增強式生成技術的比較
長文本模型(Long-Context LLMs, > 128K, e.g. 1M)
優點:
-
直接處理長輸入: 能够直接處理較長的提示或文件,无需外部擷取。
-
潛在的推理能力提升: 可能捕捉到輸入中的更多上下文和關係,進一步提升理解能力。
-
減少對外部知識源的依賴: 在某些情況下,可以直接處理輸入信息,不需要額外的擷取。
缺點:
-
高計算成本: 相較於傳統的 LLM,訓練和推理的計算成本更高。
-
上下文長度限制: 雖然比傳統 LLM 更長,但仍存在可處理輸入長度的限制。
-
數據效率: 可能需要更多的訓練數據來達到最佳性能。
微調(Fine-Tuning)
優點:
-
調適特定任務: 可以針對特定任務或領域進行訓練,以提升性能。
-
性能提升: 通常比直接使用預訓練模型效果更好。
-
潛在的小模型優化: 有時可以在較小的模型上進行微調,降低計算需求。
缺點:
-
需要標註數據: 微調通常需要帶有標籤的數據集。
-
過擬合風險: 如果訓練數據不夠多樣化,可能導致過擬合。
-
計算成本: 雖然比從頭訓練模型低,但仍需要一定的計算資源。
增強式生成(RAG)
優點:
-
接入外部知識: 可以利用大量的外部信息。
-
提升準確度和相關性: 通過結合外部知識,可以生成更準確、相關的回應。
-
靈活性: 可以與不同類型的 LLM 和知識源結合使用。
缺點:
-
需要知識庫: 建立和維護高品質的知識庫可能具有挑戰性。
-
擷取效率: 從知識庫中高效擷取相關信息至關重要。
-
潛在幻覺問題: 如果擷取到的信息不準確或誤導,生成的輸出也可能不正確。
選擇最佳方法
最佳方法取決於具體的應用場景、可用資源和期望的性能。
-
長文本模型 適合直接處理長輸入的任務,例如摘要長篇文件或生成代碼。
-
微調 適用於有大量標註數據且明確性能提升目標的任務。
-
增強式生成 在需要接入外部知識且 LLM 上下文長度有限的情況下很有價值。
在許多情況下,可以結合使用這些技術來達到最佳效果。例如,RAG 系統可以使用長文本模型來處理增強後的輸入,以提升性能。
RAG vs. Long Context
先説結論:
-
LLM-4K + RAG > LLM-16K w/o RAG (LLM: Llama2-70B and GPT-43B)
-
Llama2-70B-32K + RAG > GPT-3.5-(175B)-16K > Llama2-70B-32K w/o RAG
Takeaway
| LLM only (cloud or edge) | Cloud+Edge LLM post arbitration |
Cloud+Edge LLM pre arbitration |
Cloud info+ edge LLM RAG |
Cloud info+ edge AutoGPT |
| ———— | ———————————————————— | ———————————————————— | ———————————————- | ————————— | ————————— |
| Accuracy | 1. Based of pre-trained knowledge, could be out-of-date. 2. Hallucination without credible source |
1. Based of pre-trained knowledge, could be out-of-date. 2. Hallucination without credible source |
Worst. Edge LLM error + cloud LLM error |
High | Med-High |
| Cost | Edge:low; Cloud:high | High | Medium | Low | Med |
| Latency | Edge: fast; Cloud: slow | Fast | Fast | Slow? | Slow |
| Self-improve | You don’t know you don’t know. Ceiling: cloud LLM |
Yes, use cloud LLM fine-tune edge LLM |
Maybe | Yes | Maybe |
Source
-
[Advanced RAG Techniques: an Illustrated Overview by IVAN ILIN Dec, 2023 Towards AI](https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6) - https://arxiv.org/html/2312.10997v5
RAG
Vanilla RAG case in brief looks the following way: you split your texts into chunks, then you embed these chunks into vectors with some Transformer Encoder model, you put all those vectors into an index and finally you create a prompt for an LLM that tells the model to answers user’s query given the context we found on the search step.
In the runtime we vectorise user’s query with the same Encoder model and then execute search of this query vector against the index, find the top-k results, retrieve the corresponding text chunks from our database and feed them into the LLM prompt as context.
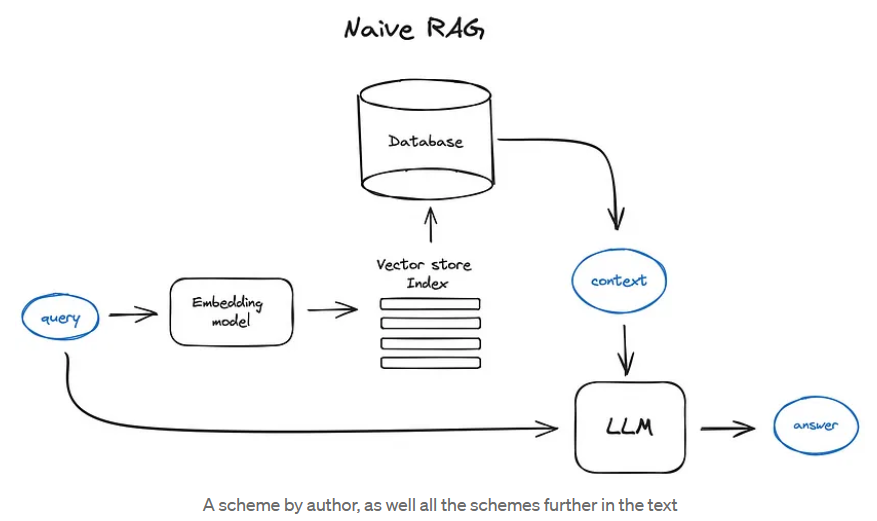
The prompt can look like:
1 | |
Advanced RAG
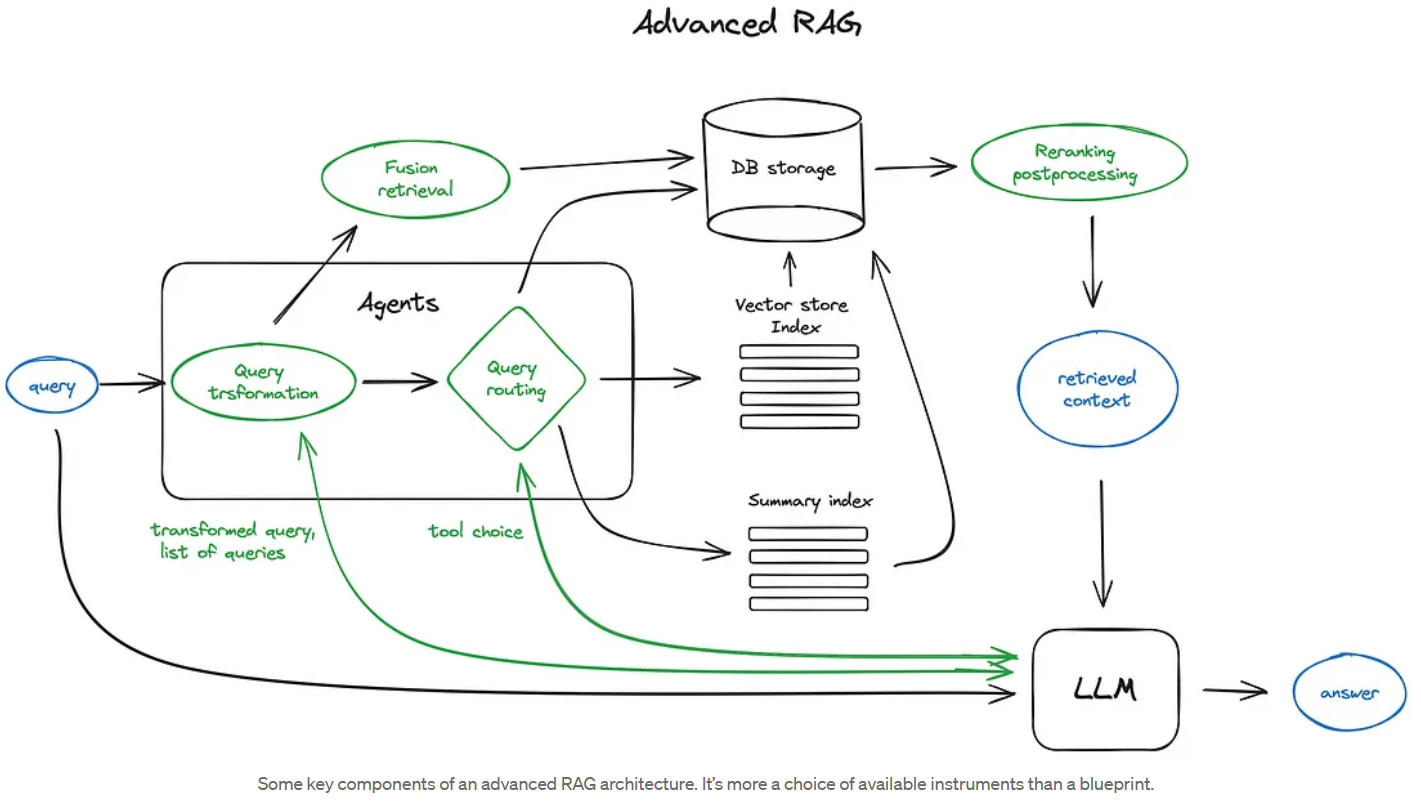
Reference
Good introduction: https://ai.meta.com/blog/adapting-large-language-models-llms/