Source
https://www.youtube.com/watch?v=8Gqbi5M8XCQ&ab_channel=AI%E8%B6%85%E5%85%83%E5%9F%9F # kotaemon零代码打造RAG知识库!Haystack企业级RAG框架轻松实现检索增强生成!Haystack整合DeepEval,快速准确评估检索增强生成结果
Introduction
如果使用 pretrain 好的 LLM 模型,應用在你個人的情境中,勢必會有些詞不達意的地方,例如問 LLM 你個人的訊息,那麼它會無法回答;這種情況在企業內部也是一樣,例如使用 LLM 來回答企業內部的規章條款等。
這種時候主要有三種方式來讓 LLM 變得更符合你的需求:
- Promt Enginerring:
輸入提示來指導 LLM 產生所需回應。例如常見的 In-context Learning,透過在提示中提供上下文或範例,來形塑模型的回答方式。例如,提供特定回答風格的範例或包含相關的情境資訊,可以引導模型產生更合適的答案。 - Fine tuning: 這個過程包括在特定數據集上訓練 LLM,使其回應更符合特定需求。例如,一家公司可能會使用其內部文件 Fine tuning ChatGPT ,使其能夠更準確地回答關於企業內部規章條款等問題。然而,Fine tuning 需要代表性的數據集且量也有一定要求,且 Fine tuning 並不適合於在模型中增加全新的知識,或應對那些需要快速迭代新場景的情況。
- RAG (Retrieval Augmented Generation):
結合了神經語言模型和擷取系統。擷取系統從資料庫或一組文件中提取相關信息,然後由語言模型使用這些信息來生成回應。可以把 RAG 想像成給模型提供一本教科書,讓它根據特定的問題去找資訊。此方法適用於模型需要整合即時、最新或非常特定的信息非常有用。但RAG 並不適合教會模型理解廣泛的領域或學習新的語言、格式或風格。

RAG 在優化 LLM 方面,相較於其他方法具有顯著的優勢 (Shuster et al. , 2021 ; Yasunaga et al. , 2022; Wang et al. , 2023c; Borgeaud et al. , 2022),主要的優勢可以體現在以下幾點:
- RAG 透過外部知識來提高答案的準確性,有效地減少了虛假訊息,使得產生的回答更加準確可信。
- 使用擷取技術能夠識別到最新的信息(使用者提供),這使得 LLM 的回答能保持及時性。
- RAG 引用資訊來源是使用者可以核實答案,因此其透明透非常高,這增強了人們對模型輸出結果的信任。
- 透過擷取與特定領域資料,RAG 能夠為不同領域提供專業的知識支援,客製化能力非常高。
- 在安全性和隱私管理方面,RAG 透過資料庫來儲存知識,對資料使用有較好控制性。相較之下,經過 Fine tuning 的模型在管理資料存取權限方面不夠明確,容易外洩,這對於企業是一大問題。
- 由於 RAG 不需更新模型參數,因此在處理大規模資料集時,經濟效率方面更具優勢。
不過雖然 RAG 有許多優勢在,但這 3 種方法並不是互斥的,反而是相輔相成的。結合 RAG 和 Fine tuning ,甚至 Promt Enginerring 可以讓模型能力的層次性得增強。這種協同作用特別在特定情境下顯得重要,能夠將模型的效能推至最佳。整體過程可能需要經過多次迭代和調整,才能達到最佳的成效。這種迭代過程涵蓋了對模型的持續評估和改進,以滿足特定的應用需求。
RAG
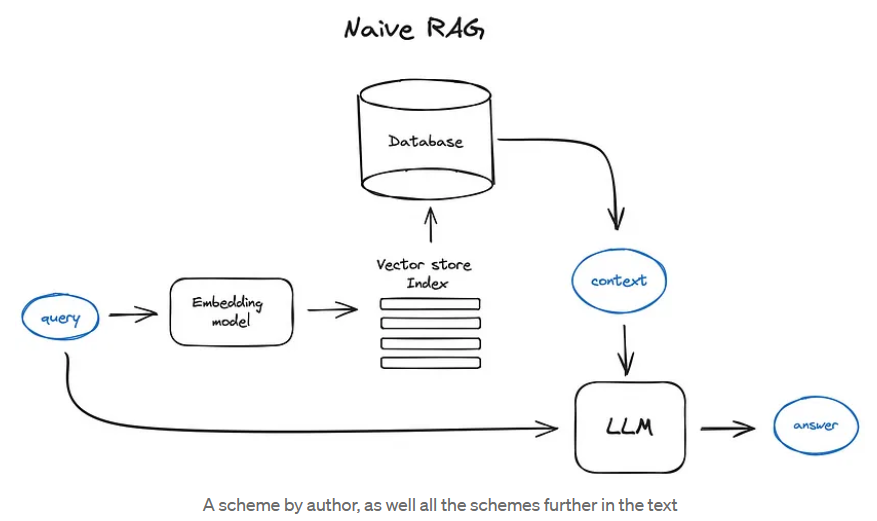
Naive RAG 簡要流程如下:
Indexing phase: 先將文本分割成塊,然後使用某個 Transformer 編碼器模型 (一般是 BERT) 將這些塊嵌入為向量,接著將所有這些向量放入索引中,最後你為大型語言模型(LLM)創建一個提示,告訴模型根據我們在搜索步驟中找到的上下文來回答用戶的查詢。
Query phase: 我們使用相同的編碼器模型 (BERT) 將用戶的查詢向量化,然後對該查詢向量在索引中執行搜索,找到前-k 個結果,從數據庫中檢索相應的文本塊,並將它們作為上下文輸入到 LLM 的提示中。
哪一個是正確的?embedding 是在數據庫之前還是之後?
在檢索增強生成(RAG)系統的上下文中,正確的順序是將文本塊 embedding 在到數據庫(或索引)之前。以下是過程的分解:
- 分塊: 將文本分割成可管理的塊。
- 嵌入: 使用 Transformer 編碼器模型將這些塊嵌入為向量。
- 索引: 將這些向量存儲在索引或數據庫中,以便高效檢索。
- 查詢處理: 當用戶提交查詢時,使用相同的編碼器模型將其向量化。
- 搜索: 對該查詢向量在數據庫中索引的向量執行搜索,以找到前 k 個結果。
- 檢索和提示: 從數據庫中檢索相應的文本塊,並將它們作為上下文輸入到 LLM 的提示中。

The prompt can look like:
1 | |
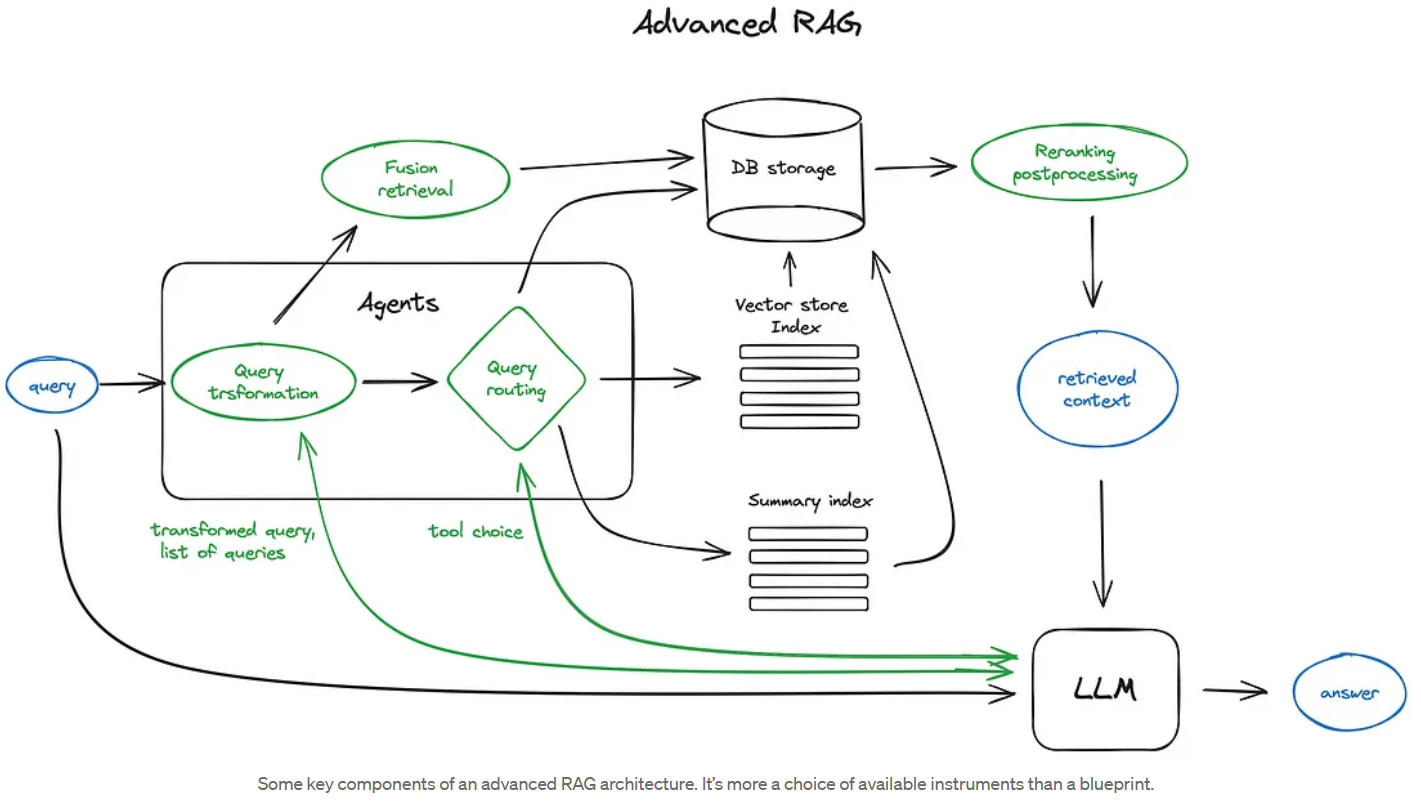
Advanced RAG
Appendix A: English Snip
Navie RAG case in brief looks the following way: you split your texts into chunks, then you embed these chunks into vectors with some Transformer Encoder model, you put all those vectors into an index and finally you create a prompt for an LLM that tells the model to answers user’s query given the context we found on the search step. In the runtime we vectorise user’s query with the same Encoder model and then execute search of this query vector against the index, find the top-k results, retrieve the corresponding text chunks from our database and feed them into the LLM prompt as context.
Whic one is correct? Embedding before or after database?
In the context of a Retrieval-Augmented Generation (RAG) system, the correct sequence is to embed your text chunks before storing them in a database (or index). Here’s a breakdown of the process:
- Chunking: You split your texts into manageable chunks.
- Embedding: You use a Transformer Encoder model to embed these chunks into vectors.
- Indexing: You store these vectors in an index or database for efficient retrieval.
- Query Processing: When a user submits a query, you vectorize it using the same Encoder model.
- Search: You execute a search of this query vector against the indexed vectors in your database to find the top-k results.
- Retrieval and Prompting: You retrieve the corresponding text chunks from your database and feed them into the LLM prompt as context.
So, to answer your question: embedding occurs before storing data in the database/index.