Takeaway
-
Heyna 核心觀念: Recurrent + FIR 變成無限長的 Hyena filter 取代有限的 attention!
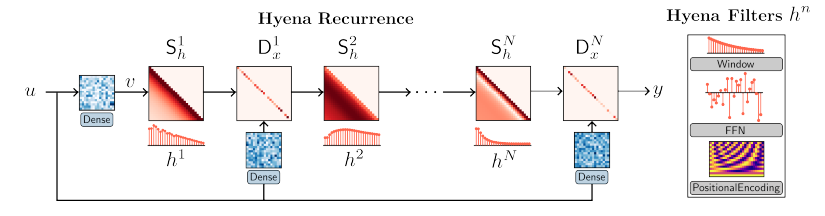
-
RNN 或是類似 state compression 的 model 例如 RetNet, RWKV, Mamba 可以解決這個問題。
- S4 (or SSM) for linear sequence -> S6 (add selector) -> Mamba (add more layers and other blocks) for generation
| RNN/LSTM | Transformer | RWKV | Mamba | |
|---|---|---|---|---|
| Train, 時間維度 | 梯度消失,無法平行 | 可以平行 | 可以平行 | 可以平行 |
| Attention scope | 小,附近 tokens | 大,$T$ | 大,$T$ | 無窮大? |
| Attention 計算, $T$ tokens | 綫性 | 平方 (prefill) | 綫性 | 綫性 |
| Attention 存儲 | 1-step | 平方 (update) | 1-step | 1-step |
| Complexity, Time | $O(T^2 d)$ | $O(T d)$ | ||
| Complexity, Space | $O(d)$, 1-step | $O(T^2 + Td)$ | $O(d)$, 1-step | $O(d)$ |
| Nonlinearity | Small sigmoid ($d$) | Big softmax ($d^2$) | Softmax, sigmoid? | Small softmax ($d$), SILU x*sigmoid(x) |
$T$: sequence length; $d$: feature dimension. $d$ 和 $N$ 是同一件事嗎?