Source
NIM introduction: https://www.youtube.com/watch?v=vE80SLk-4PM&t=14s
(Enterprise) Edge Server
Trade-off between throughput and latency
Throughput = Batch Size x Tokens/sec
Higher throuput means to serve more users (batch). The advantage of high batch size.
- Better GPU utilization exploiting the parallelism of the batch
-
More users by the statisitcs multiplexing gain The disadvantage of high batch size
- Longer latency due to the multiple batch/user workload scheduling and alignment
Trade-off between Cost and User Experience
Edge server pursue “large enough” model size but not the largest model compare to the data center. The practical concern is cost and latency. However, it needs to ensure the model size provides acceptable user experience (accuracy, generality, robustness).
NIM- Enterprise Inference Server/Service
- Inference server with production ready microservices
- Hybrid - Seamless between cloud and edge server: Cloud Nvidia LaunchPad Labs.
- Microservice - small appplications with a single responsiblity that can be deployed, scaled, and tested independently.
- NIM key componenets
- HW (Nvidia): server (local or cloud: Nvidia LaunchPad Labs), seamless hybrid computing
- SW (Nvidia and Open): engine providing AI models (with microservices) and runtime
- Example: Llama3, NeLLM
- SW API (Open): integrate microservices into pipelines
How Nvidia Make Money
- NIM HW
- NIM microservice using Nvidia Cloud (Nividia LaunchPad Labs) for training and inference
How OpenAI Make Money
- LLM microservice using GPT-4o
How Meta Make Money?
- no direct revenue from LLM now
- maybe value added LLM microservice in the future? (premium model, etc.)
- Insert advertisement or xxx in the future?
![[Pasted image 20240902095114.png]]
Hardware
Integrate CPU for head node with AI acclerator
E.g. Tenstorrent Blackhole.
No HBM
Use Ethernet and UALink instead of Infiniband and NVLink
Service
Nvidia called it microservice embedded in the name of NIM - Nvidia Inference Microservice.
Speech and translate microservice
- ASR
- TTS
- Translate
LLM microservice
- Language model
Llama3.1-8B and 70B
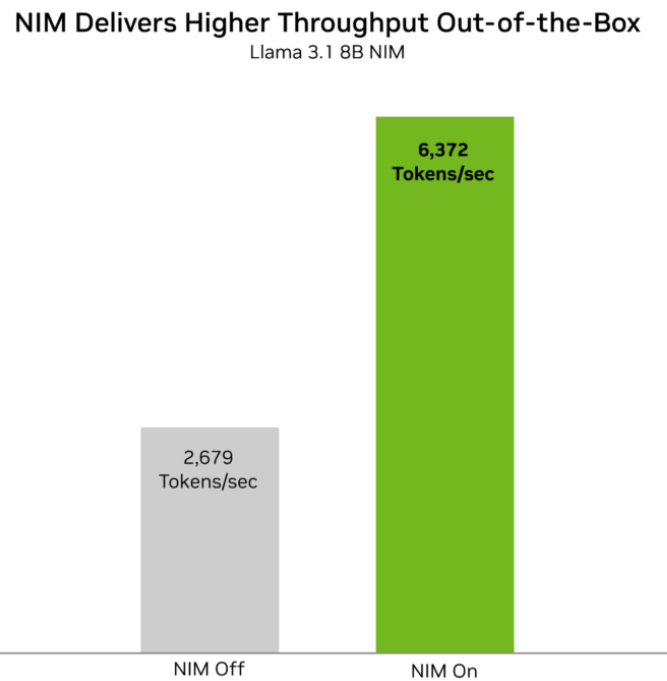
For the Llama3.1-8B performance. The throughput is 6372 tokens/sec for concurrent request: 200. Therefore, the per user/batch speed is around 32 tokens/sec. The format is BF16, and TTFT is aound 1sec. The memory bandwidth is about: 6372 x 16/8 = 12.7 TB/sec. But H100 SXM is only 3.35 TB/sec. How? Use SpD?
RAG (Retrival Augment Generation)
- Embedding
- Retrival
- Reranking
NIM (Nvidia Inference Micro-service)
Nvidia Inferencing Microservice (NIM) is a cloud-native solution designed to facilitate the deployment of machine learning models for inference at scale. It is part of Nvidia’s broader suite of tools aimed at optimizing AI workflows, particularly in production environments.
Key Features of NIM
- Scalability: NIM is built to handle large volumes of inference requests, making it suitable for applications that require high throughput and low latency.
- Flexibility: It supports various model formats, allowing users to deploy models trained with different frameworks, such as TensorFlow, PyTorch, and ONNX.
- Integration: NIM can be easily integrated into existing cloud infrastructures and workflows, enabling seamless deployment and management of AI models.
- Monitoring and Management: It provides tools for monitoring model performance and managing resources effectively, ensuring optimal operation in production.
Inference
NIM is primarily designed for inference tasks. It optimizes the process of serving AI models to respond to real-time queries and requests efficiently.
Training and Fine-Tuning (Yes! For RAG!! Advanced RAG needs training or fine-tuning BERT or encoder)
NIM is not specifically designed for training or fine-tuning models. While it may support some aspects of model management, for training and fine-tuning, Nvidia offers other solutions, such as:
- Nvidia GPU Cloud (NGC): A platform that provides pre-trained models and tools for training and fine-tuning AI models.
- Nvidia Triton Inference Server: This can be used in conjunction with NIM for efficient model serving but is primarily focused on inference.
In summary, NIM is focused on providing a robust solution for deploying AI models for inference rather than for training or fine-tuning. For those purposes, users should explore other Nvidia offerings tailored to model training workflows.
What is the Trinton inference server? what’s the SW stack. Is it open source?
Answer
Nvidia Triton Inference Server is an open-source software platform designed to simplify the deployment of machine learning models for inference. It provides a robust and flexible solution for serving AI models in various environments, supporting multiple frameworks and model formats.
Key Features of Triton Inference Server
- Multi-Framework Support: Triton supports models from various frameworks, including TensorFlow, PyTorch, ONNX, and others, allowing users to deploy models trained in different environments seamlessly.
- Dynamic Model Management: It enables dynamic loading and unloading of models, allowing for efficient resource management and the ability to serve multiple models simultaneously.
- High Throughput and Low Latency: Triton is optimized for performance, providing features like batching and concurrent model execution to maximize throughput and minimize latency.
- Model Versioning: Users can manage different versions of models, facilitating easy updates and rollbacks.
- Monitoring and Metrics: Triton provides built-in metrics for monitoring model performance and resource utilization, aiding in optimization and troubleshooting.
Software Stack
The software stack for Triton Inference Server typically includes:
- Nvidia GPU Drivers: Required for GPU acceleration.
- CUDA Toolkit: For running GPU-accelerated applications.
- TensorRT: For optimizing deep learning models for inference on Nvidia GPUs.
- Docker: Triton can be deployed in a containerized environment using Docker, simplifying installation and management.
- Kubernetes: For orchestration in cloud-native environments, Triton can be integrated with Kubernetes for scaling and managing inference workloads.
Open Source Status
Yes, Triton Inference Server is open source. It is available under the Apache 2.0 license, allowing users to modify, distribute, and use the software freely. The source code can be found on GitHub, where Nvidia actively maintains and updates the project.In summary, Nvidia Triton Inference Server is a powerful and flexible solution for deploying machine learning models for inference, with a comprehensive software stack and open-source accessibility.
What is Kubernetes and how it help to integrate Triton inference ?
Answer
Kubernetes is an open-source container orchestration platform designed to automate the deployment, scaling, and management of containerized applications. It provides a framework for running distributed systems resiliently, enabling developers to manage applications in a more efficient and automated manner.
Key Features of Kubernetes
- Container Orchestration: Kubernetes manages the lifecycle of containers across a cluster of machines, ensuring that the desired state of applications is maintained.
- Scaling: It can automatically scale applications up or down based on demand, allowing for efficient resource utilization.
- Load Balancing: Kubernetes provides built-in load balancing to distribute traffic across multiple instances of an application, ensuring high availability and reliability.
- Self-Healing: It automatically replaces or restarts containers that fail, ensuring that applications remain available and operational.
- Service Discovery: Kubernetes facilitates service discovery, allowing applications to communicate with each other seamlessly.
- Configuration Management: It allows for the management of application configurations and secrets, enabling secure and efficient deployment.
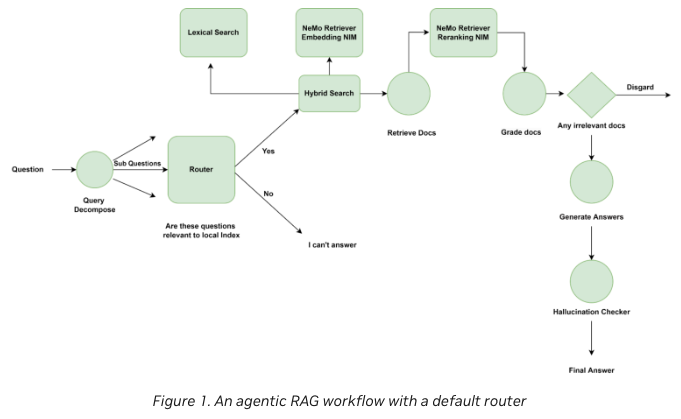
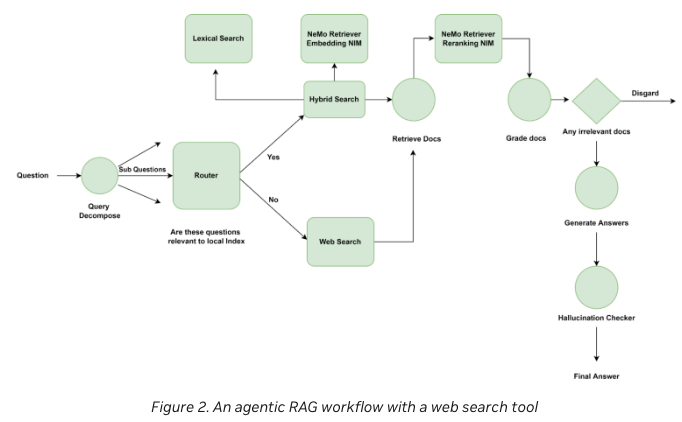
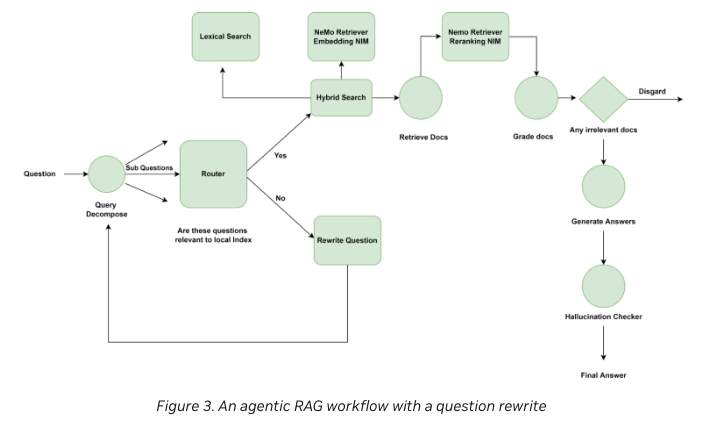
Block diagram first. It seems everything is done in the NIM, self-sufficient, nothing to do with the cloud!
The nuance is RAG, part of the micro-service in NIM.
https://developer.nvidia.com/blog/build-an-agentic-rag-pipeline-with-llama-3-1-and-nvidia-nemo-retriever-nims/
Tenstorrent (no HBM)
https://www.youtube.com/watch?v=uhHdz_aI-mo Very good!: https://1nfinite.ai/t/tenstorrent-grayskull-wormhole/100 Sparse TOPS
Roadmap
![[Pasted image 20240811000842.png]]
Grayskull
![[Pasted image 20240810235348.png]]
e75 board ![[Pasted image 20240810235715.png]]
e150 ![[Pasted image 20240810235802.png]]
SW ![[Pasted image 20240811000019.png]]
![[Pasted image 20240811000137.png]]
Wormhole
New board: Wormhold n150s (1 chip), 160W and n300s (dual chips), 300W Memory: GDDR6 (12/24GB) Computation: 4xx TOPS (sparse?)
![[Pasted image 20240811000410.png]]
The figure below is n150s. The populated PCB is n300s. ![[Pasted image 20240811000315.png]]
Reference
- Speculative Decoding with Big Little Decoder!!
- https://arxiv.org/abs/2302.07863
-
Cloud-edge hybrid SpD! [2302.07863] Speculative Decoding with Big Little Decoder (arxiv.org)
- Apple Intelligence: https://x.com/Frederic_Orange/status/1804547121682567524/photo/1
- Qualcomm hybrid AI white paper: https://www.qualcomm.com/content/dam/qcomm-martech/dm-assets/documents/Whitepaper-The-future-of-AI-is-hybrid-Part-1-Unlocking-the-generative-AI-future-with-on-device-and-hybrid-AI.pdf
前言
Big-Little Speculative Decode 主要是解決 autoregressive generation speed 太慢的問題。
此技術的核心便在於如何儘可能又快又準地生成 draft token,以及如何更高效地驗證 (verification)。
其他的應用:假設大小模型。大模型在雲,小模型在端。
- 小模型 Predict the response length
- 小模型 predict local or cloud tasks.
Speculative Decoding with Big Little Decoder
[paper] [paper reading]
本文把是否需要大模型進行確認的權力交給了小模型,稱之爲 Fallback。Fallback 之後,對於兩次 Fallback 之間小模型生成的 token,引入 Rollback 確保其性能。
| 在第 n 次解碼迭代中,小模型和大模型各自輸入一個部分生成的輸出文本 $ y_{1:n-1} = (y_1, \cdots, y_{n-1}) $,然後分別生成一個在整個詞彙表上的概率分佈 $ p_S(y | y_{1:n-1}) $ 和 $ p_L(y | y_{1:n-1}) $。接著,從概率分佈中取樣下一個詞 $ y_{n,S} $ 和 $ y_{n,L} $: |
| $y_{n,S} \sim p_S(y | y_{1:n-1}) $ 以及 $ y_{n,L} \sim p_L(y | y_{1:n-1}) $ |
| 回退策略 (Fallback Policy):如果 $ \max_y p_S(y | y_{1:n-1}) < \alpha_{FB} $,則回退到大模型並設置 $ y_n = y_{n,L} $。 |
| 回滾策略 (Rollback Policy):如果存在一個最小的 $ m \in [1, n-1] $ 使得 $ d(p_S(y | y_{1:m}), p_L(y | y_{1:m})) > \alpha_{RB} $,則回滾預測 $ (y_m, \cdots, y_n) $ 並設置 $ y_m = y_{m,L} $。 |
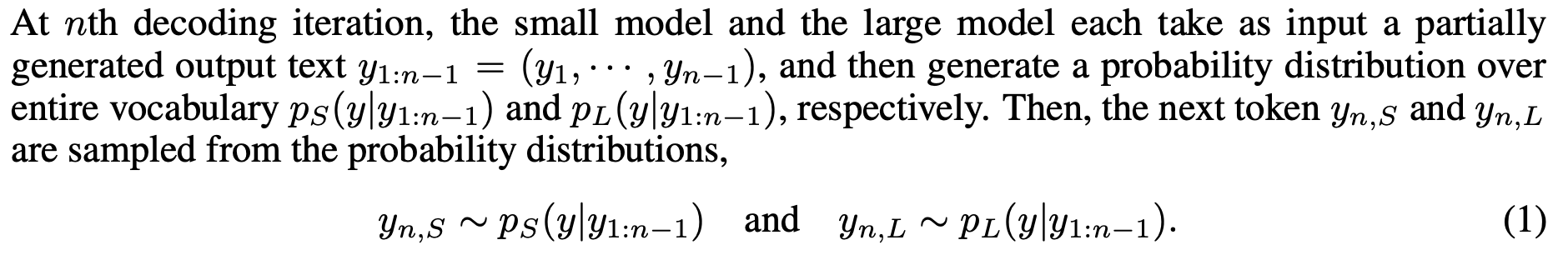
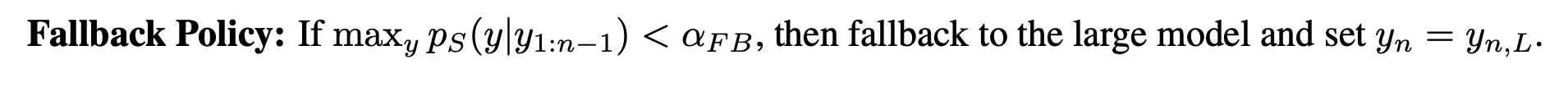
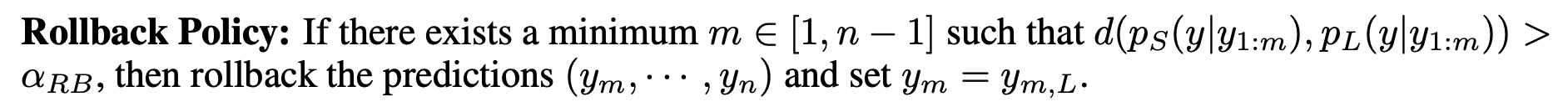
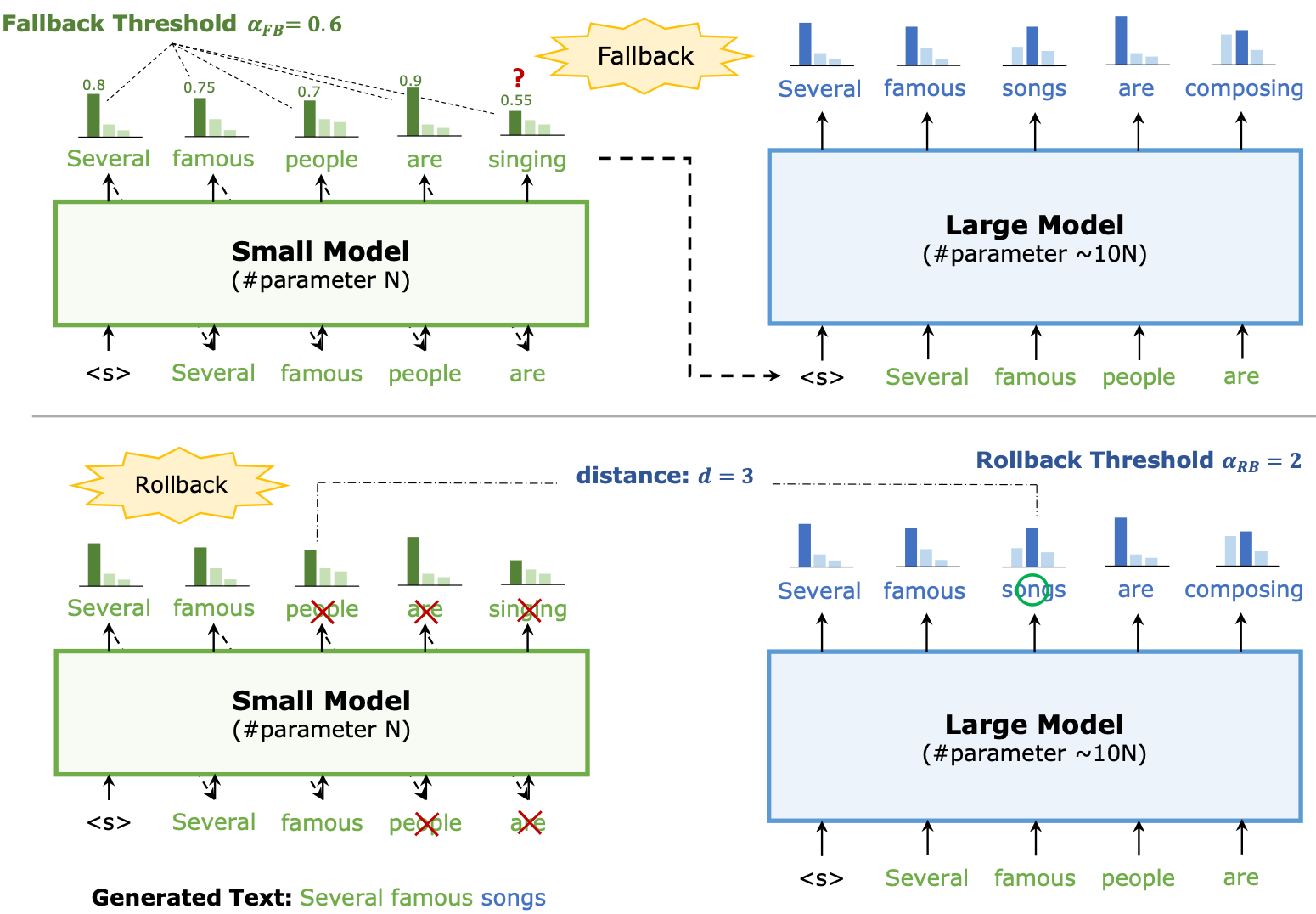
具體來說,一旦小模型在當前 token 輸出機率的最大值低於設定的閾值 𝛼𝐹𝐵,就進行 Fallback,開始引入大模型進行 verify。在 verify 過程中,計算每個 token 上大小模型輸出機率之間的距離 𝑑,一旦 𝑑 大於設定的閾值 𝛼𝑅𝐵,就將此 token 改爲大模型的輸出,並讓小模型在後續從這個 token 開始生成。
此方法無法確保輸出與原模型完全一致。實驗的模型比較小,未超過 1B。
GKT: A Novel Guidance-Based Knowledge Transfer Framework For Efficient Cloud-edge Collaboration LLM Deployment
[paper] [paper reading]
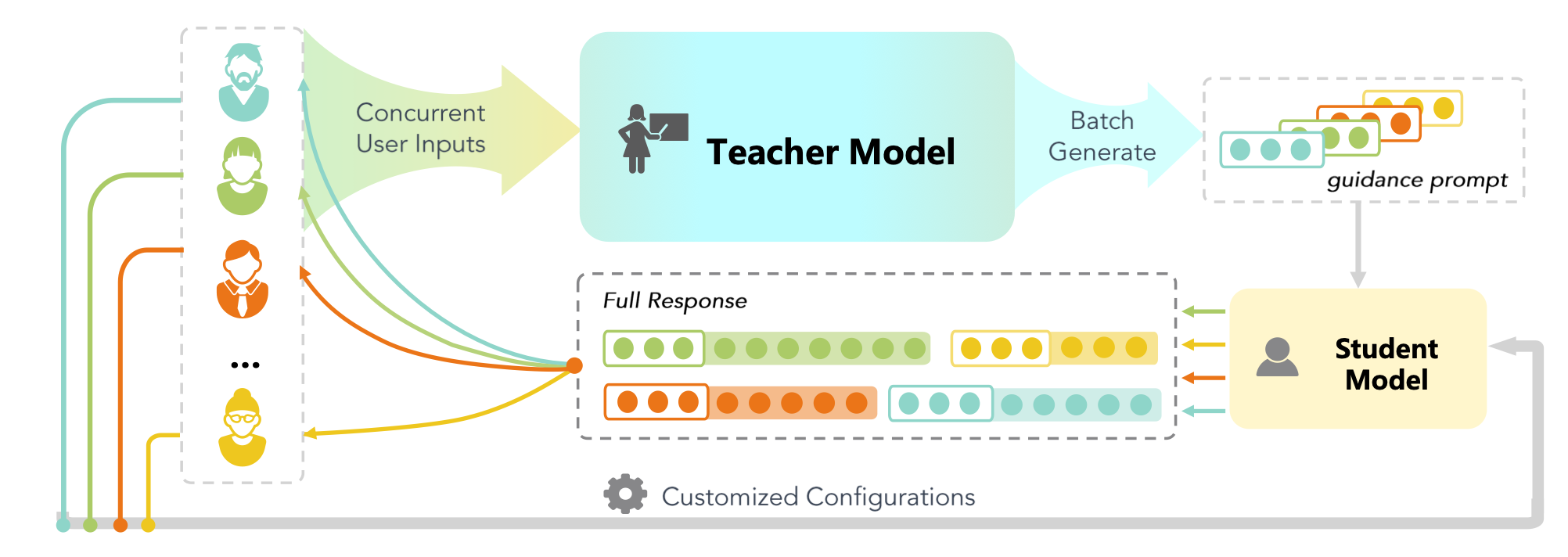
Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline
[paper] [paper reading]
這個 paper 說明:因為 LLM 可以“說話”,可以直接利用這個特點,詢問 LLM 得到資訊作為後續性能優化。
這裡舉兩個例子:(1) 請 LLM 先估計回答的長度;(2) 請 LLM 先估計問題的難度。
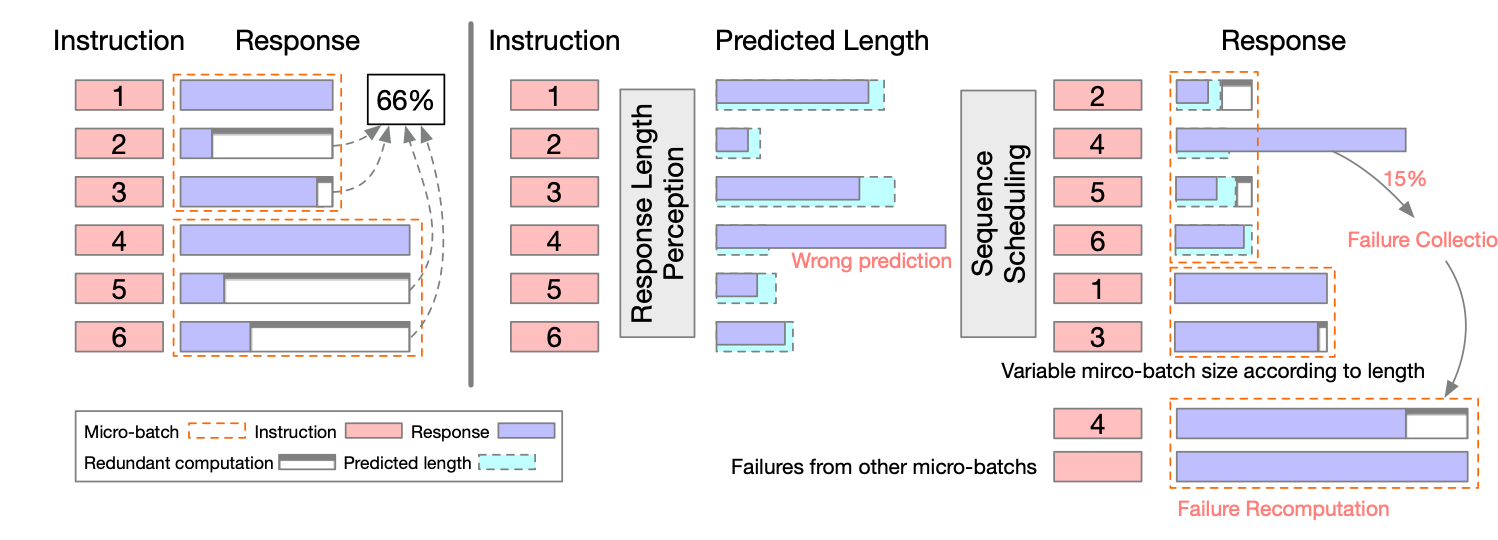
估計回答的長度:
利用如下的 prompt. 如此 LLM 在回答之前,會先估計回答的長度。對於多個 batches 的回覆,可以先排程而有跟好的優化結果。
Create a fun math question for children.
Before responding to the above instruction, you have to predict the length of your response. Print the estimated number of words in your response in the first line. Then change to a new line to respond to the instruction.
ChatGPT
16
Imagine you have 10 apples and you give 3 to your friend. How many apples do you have left? 🍎
不過有幾個問題:
- 使用 words 比 tokens 更準確。
- 額外的 prompt 實際上影響回覆。 (1) 回覆的長度本身就是變動的, depending on temperature. (1) LLM 似乎會根據回覆的長度,自動控制回覆的內容。
- 這個估計並不準確,depending on LLM size. GPT4 表現最好,但是也不是 100%. 還是需要補救措施。
估計回答的難度:
- 看起來 GPT4o 和 Llama3 8B 對於問題的判斷都還不錯。不過可能要做更完整的測試,利用 MMLU 或其他 terst dataset.
Assuming there is a 10-times more powerful model than you are. I will ask a question. You need to tell me if it’s better for you or the more powerful model to answer.
Question: what’s the capital of England.
ChatGPT
It’s better for me to answer this question.
The capital of England is London.
Question: what is the solution of Riemann Hypothesis
ChatGPT
It’s better for the more powerful model to answer this question.
The Riemann Hypothesis is an unsolved problem in mathematics and requires deep expertise and advanced capabilities to address comprehensively.
Llama3 8B
Assuming there is a 10-times more powerful model than you are. I will ask a question. You need to tell me if it’s better for you or the more powerful model to answer.
Question: The capital of England is London.
Llama
A simple question!In this case, it’s definitely better for me to answer. The capital of England is a well-known fact, and I can provide the correct answer quickly and accurately. The answer is London.The more powerful model wouldn’t be able to provide any additional insight or complexity in this case, so I’m happy to take on the task!
Question: what is the integration of cosine function?
Llama
What a great question!After analyzing the question, I think it’s more suitable for the more powerful model to answer. The integration of the cosine function is a complex mathematical problem that requires a higher level of computational power and mathematical knowledge than I possess.I can try to provide a simple answer, but it would likely be incomplete or inaccurate. The more powerful model, on the other hand, would be able to provide a more detailed and accurate answer, possibly involving advanced mathematical techniques and symbolic manipulation.So, I recommend asking the more powerful model to answer this question.
Question: what’s the height of Mt. Everest?
Llama
A simple question!In this case, it’s definitely better for me to answer. The height of Mt. Everest is a well-known fact, and I can provide the correct answer quickly and accurately. The height of Mt. Everest is 8,848 meters (29,029 feet) above sea level.The more powerful model wouldn’t be able to provide any additional insight or complexity in this case, so I’m happy to take on the task!
To Do:
- 設計一個 LLM test using Llama3 8B. 然後評估錯誤的比例和 dispatch 到 GPT4 的比例!看難度是否可以正確指到大 model.
- 設計特殊的 token 估計長度和難度。
In context prompting 比 finetuning 更實用。
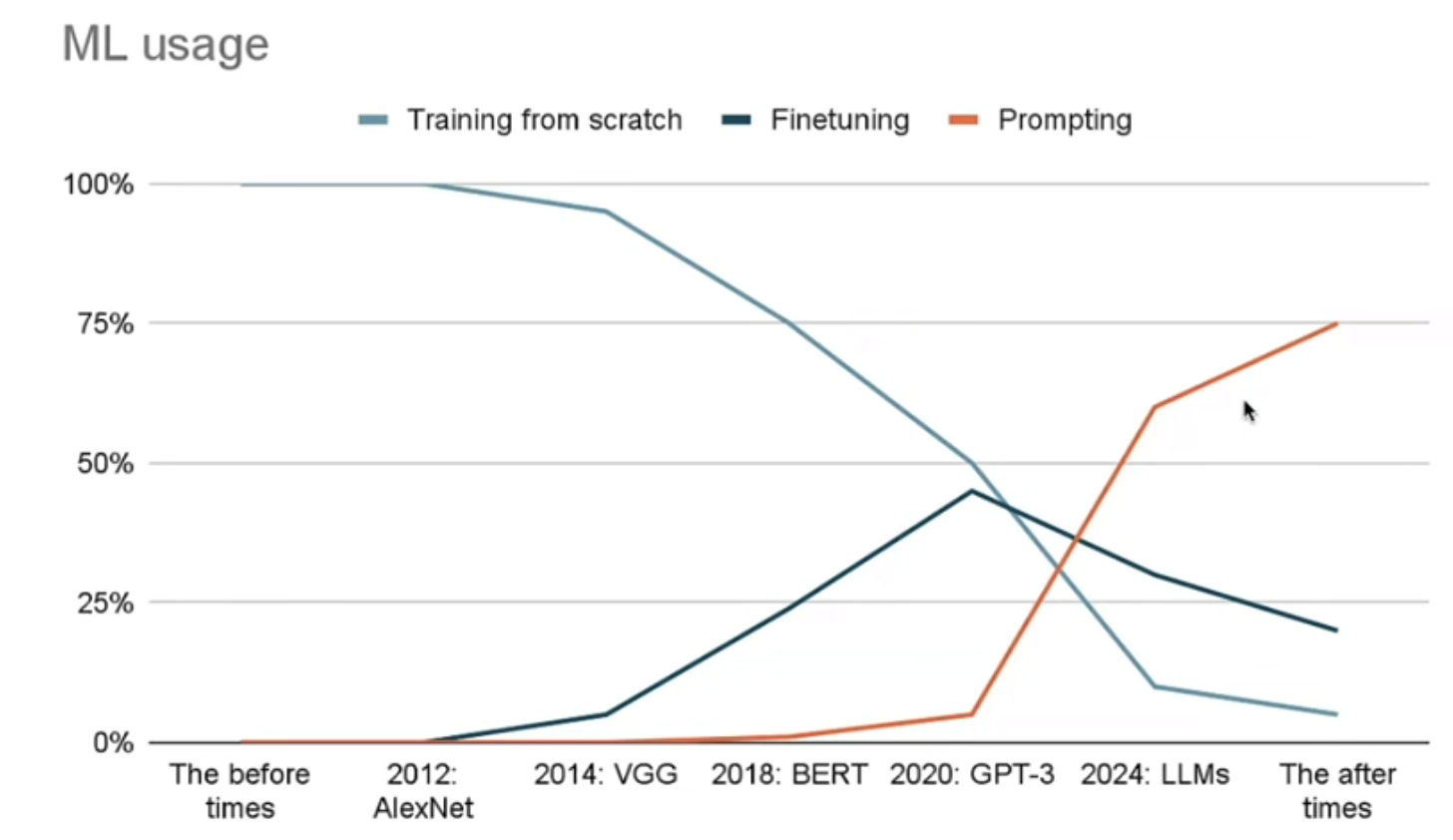
Reference
Nvidia Inference Microservice: https://developer.nvidia.com/blog/a-deep-dive-into-the-latest-ai-models-optimized-with-nvidia-nim/